1 Making our First Image: “A damn fine cup of coffee”
The chapter introduces Stable Diffusion through the lens of remix culture, likening it to early hip-hop’s art of combining familiar elements into something new. It invites readers to channel imagination into images, while acknowledging that compelling results come from learning tools and techniques rather than one-click magic. A key theme is empowerment: because Stable Diffusion is open source, a thriving community continually extends its capabilities, and everything in the book can be run on consumer hardware, making exploration accessible and fun.
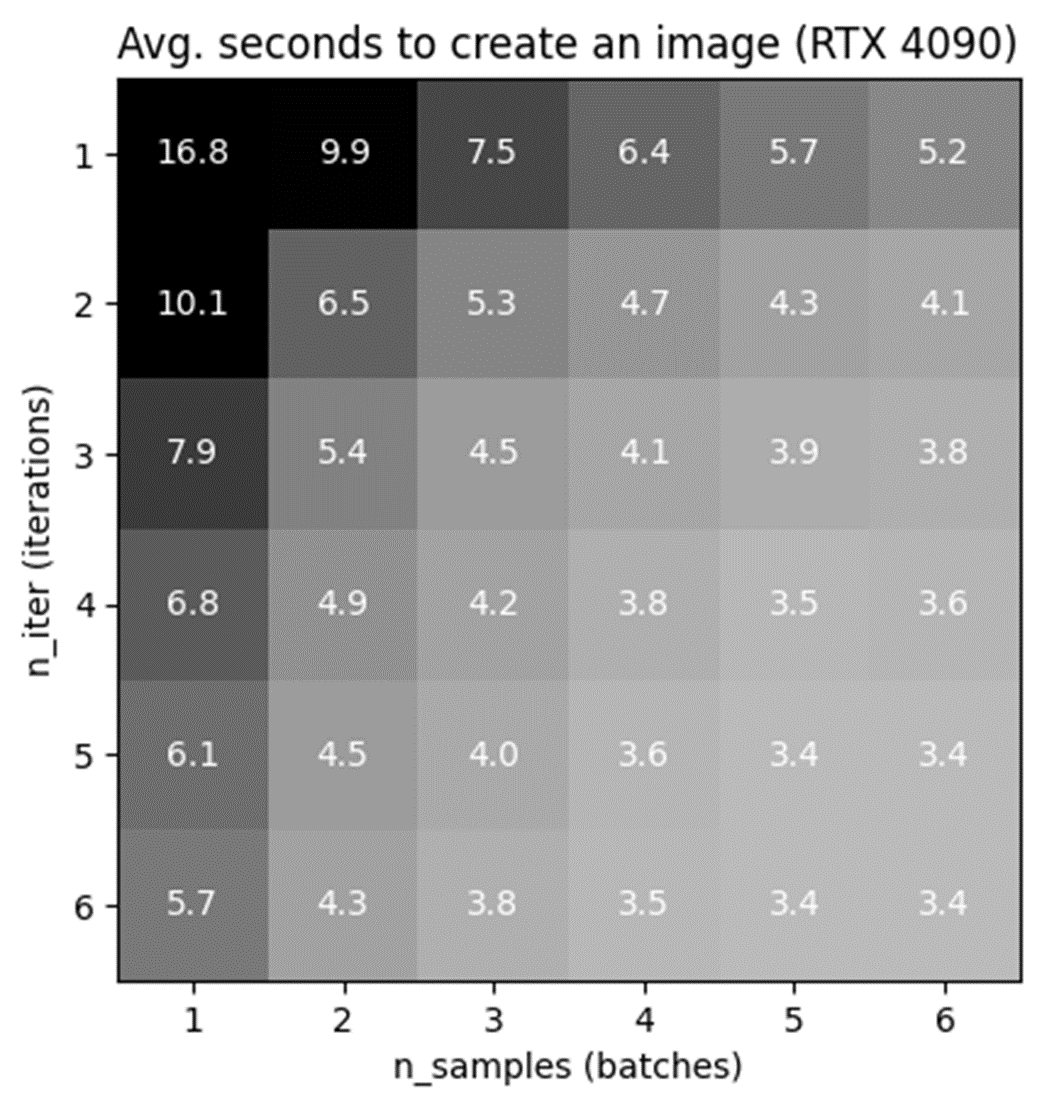
Readers are guided through the essentials of text-to-image generation using CompVis’s implementation and the prompt “A damn fine cup of coffee.” The chapter explains how to run the script, why generating many images helps, and how iterations versus batch size affect throughput and GPU VRAM—with little real-time advantage to larger batches. It introduces seeds for reproducibility and variety, then shows how height and width constraints (and especially aspect ratio) can meaningfully alter composition and content, all while reminding that higher pixel counts demand more VRAM.
The chapter then focuses on prompt engineering: favor clear, descriptive language over vague poetry, add contextual scene details, and specify artistic styles to steer results—iterating as you go. Examples evolve from a plain “cup of black coffee” to adding a diner setting and stylistic cues like “surrealist painting” or “wood etching” to achieve mood and avoid the uncanny valley. It closes by demonstrating a simple source edit to disable the NSFW safety checker (behind the notorious placeholder image), emphasizing the user control open source provides and setting up more powerful, user-friendly workflows in subsequent chapters.
Getting my imagination on the screen

Browsing an infinite library of Pulp Sci-Fi that never was.

Who knew monks were such avid readers of sci-fi?

Envisioning ancient aliens.

The initial 6 images created by our prompt: “A damn fine cup of coffee.”

Average seconds to create an image, comparing iterations and batch.
Generating 30 images at once.

Creating 6 different images with seed 12345.

Images with a 5:3 landscape aspect ratio.

Images with a 3:5 aspect ratio using the same seed.

Images with a 3:7 aspect ratio using the same seed.

Images with a 4:1 aspect ratio using the same seed.

A poetic prompt does not always yield poetic images.

A straight forward prompt yields more cups of black coffee.

Adding a scene to an image can help provide context.

Choosing a landscape aspect ratio helps display the counter.

Creating surrealistic images.

Images in the style of a wood etching.

I would say that’s a damn fine cup of coffee!

Being “Rick-rolled” by Stable Diffusion.

Summary
- Generating with Stable Diffusion is an iterative process, in which we are constantly revising our settings and prompts.
- Despite the many ways to improve images, it’s always a good idea to generate a variety of images to see if we find a particular one that stands out to us as pleasing.
- Our prompts should be clear and descriptive. Giving some context for the object we’re prompting can change the image dramatically. Describing the style of the image can further let us change the feeling of the images we’re generating.
- The aspect ratio that we use to generate an image can have a major impact on the way the image looks. Consider whether the image you want to create would look better as a square, a landscape or portrait.
- Because Stable Diffusion is open source we (as well as the entire community of users) can change and extend its behavior.
 A Damn Fine Stable Diffusion Book ebook for free
A Damn Fine Stable Diffusion Book ebook for free