1 Peeking inside the black box
This chapter demystifies why building GenAI applications feels so different from writing traditional software. Instead of prescribing deterministic, step-by-step logic, you design workflows that route text through a Large Language Model—a probabilistic, non-explanatory “black box” that speaks natural language, not code. Because LLMs are non-deterministic, stateless, and pre-trained, the focus shifts from controlling exact outputs to shaping behavior through prompts, context, and architecture, with a practical aim: understand what GenAI does well, where it falls short, and how to assemble effective applications (the book uses low-code tools like LangFlow along the way).
The chapter then shows how real products overcome core LLM limitations by engineering around them. Apparent “memory” comes from the application capturing prior turns and resending relevant history with each request; “fresh knowledge” is injected at inference time by attaching up-to-date, task-relevant snippets to the prompt (later formalized as retrieval-augmented generation). Beyond memory and knowledge, production systems orchestrate tool use via APIs, guide tone and behavior through prompt engineering, and even coordinate multiple specialized agents. Much of what ChatGPT or Copilot seems to do natively is, in fact, careful scaffolding that developers can replicate and tailor to their own domains.
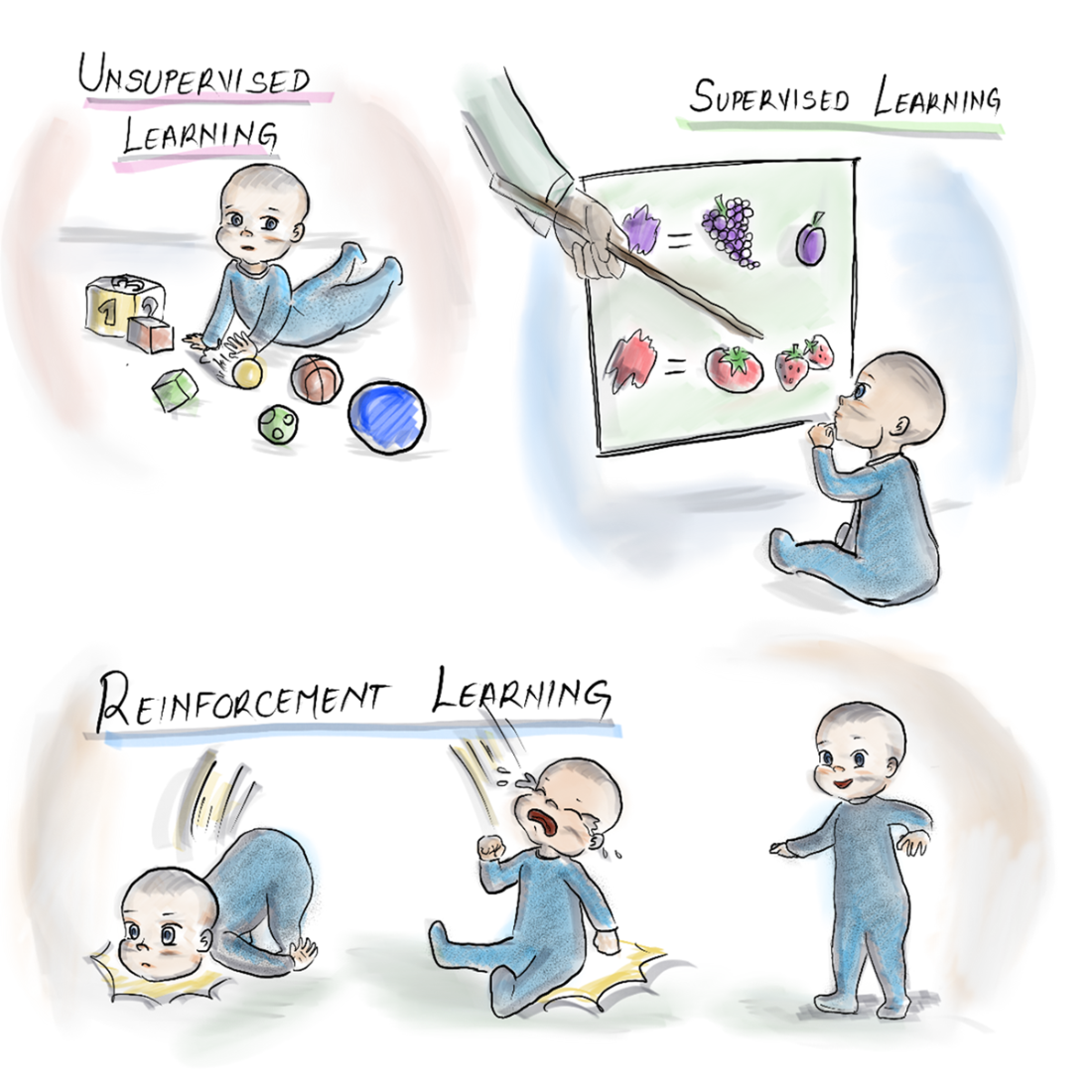
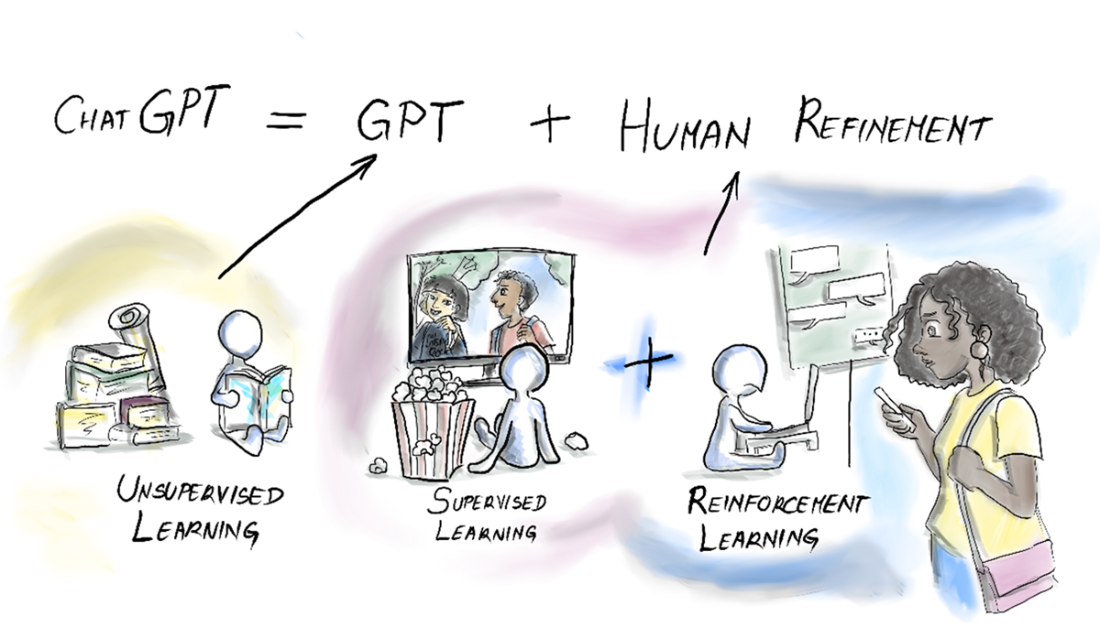
Finally, the chapter peeks inside the box to build intuition for how LLMs generate text. GPT-style models tokenize input, map tokens to high-dimensional embeddings, and predict the next token autoregressively using transformer networks trained at massive scale. Training progresses from unsupervised pre-training to supervised refinement and reinforcement learning from human feedback, yielding models like GPT-3 with enormous parameter counts and compute demands. Because pre-training fixes knowledge up to a cutoff, applications must keep outputs current by enriching prompts with external context, optionally fine-tuning for specialization, and choosing the right model size (including smaller SLMs) for the job. The overarching lesson: you “tame the beast” by respecting these limits and supplying the right memory, knowledge, and control mechanisms around the LLM core.
GenAI apps have an LLM (Magic Black Box) somewhere.
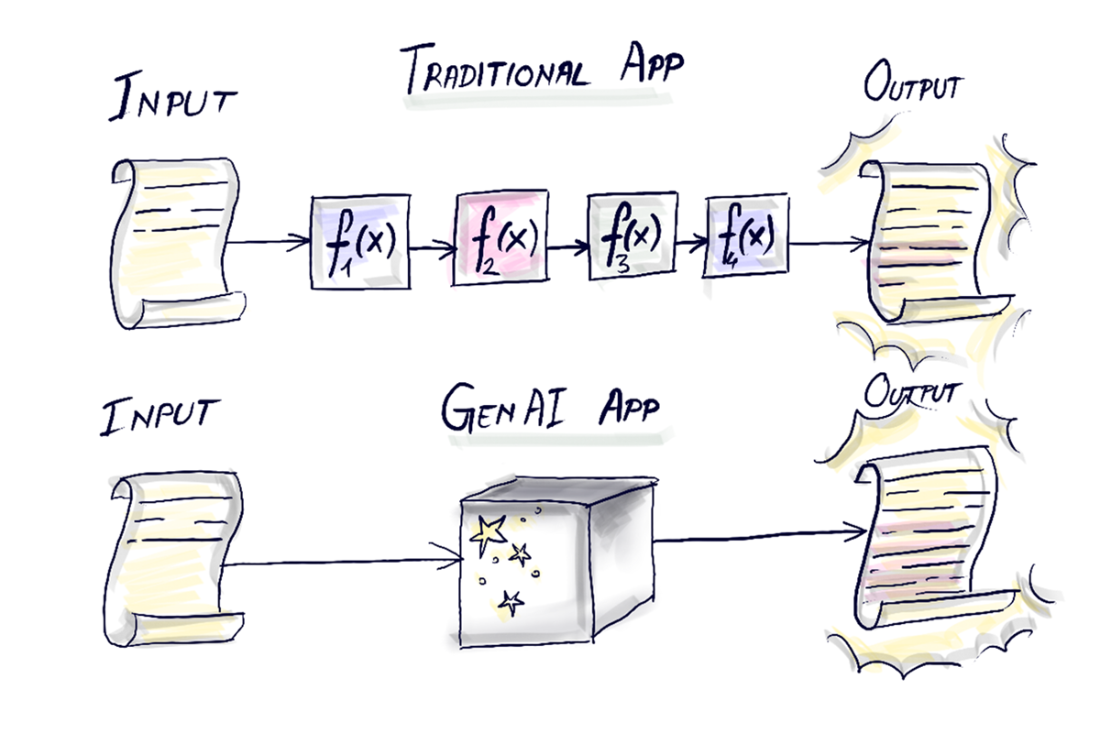
The magic box. Gets text as input and generates text as output.
LLM relationships: every chat is a first date.

Taming the GenAI beast.

The three types of machine learning: Unsupervised, supervised, and reinforcement.
The learning stages of ChatGPT.
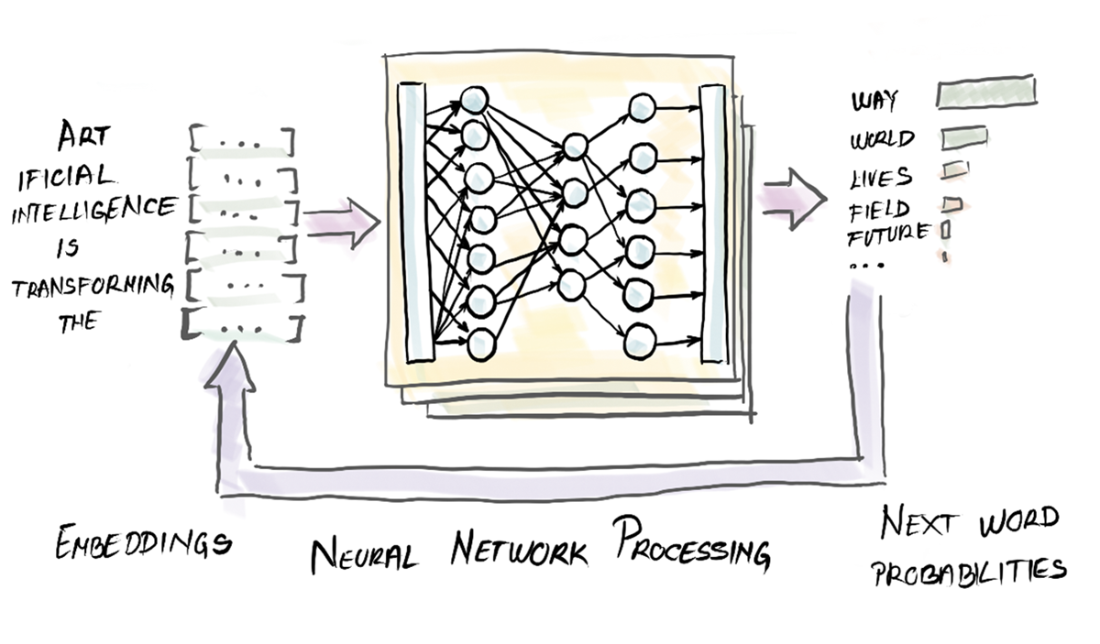
Words are numbers in the eyes of an LLM.
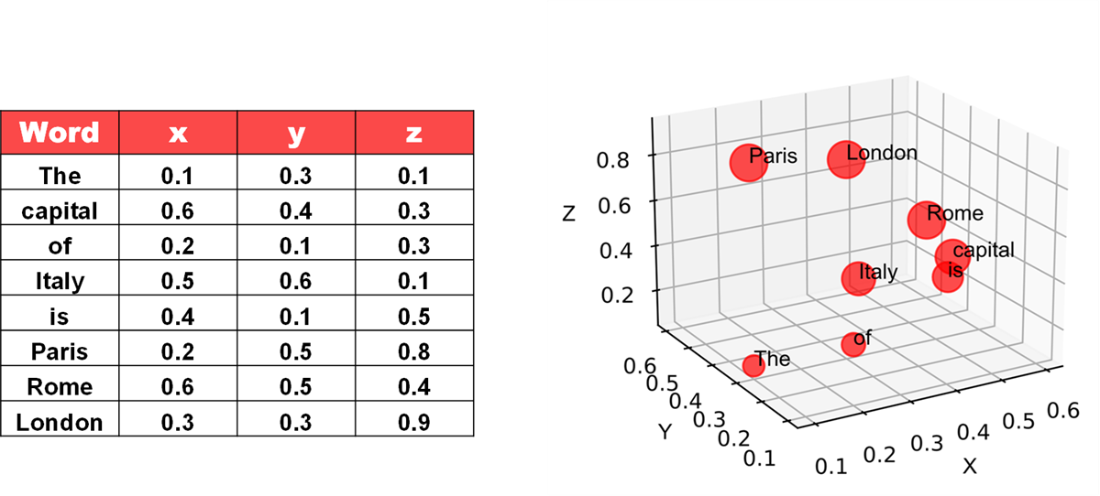
Given a prompt, you can calculate the context.
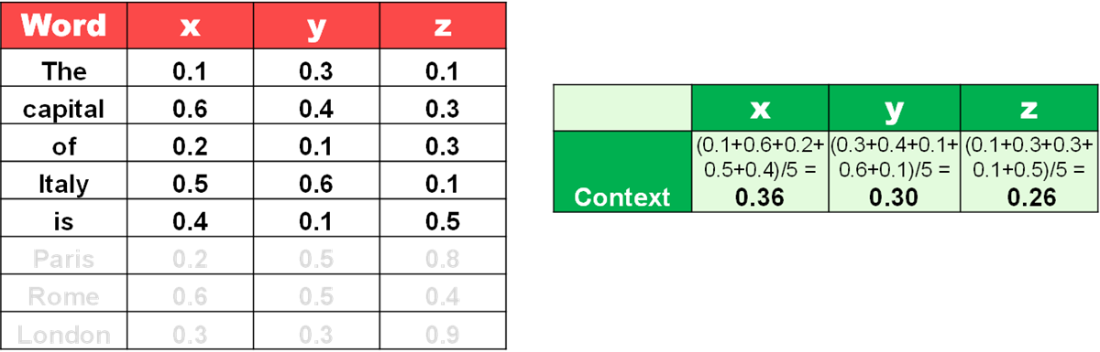
Guess the next best word by combining embeddings with context.
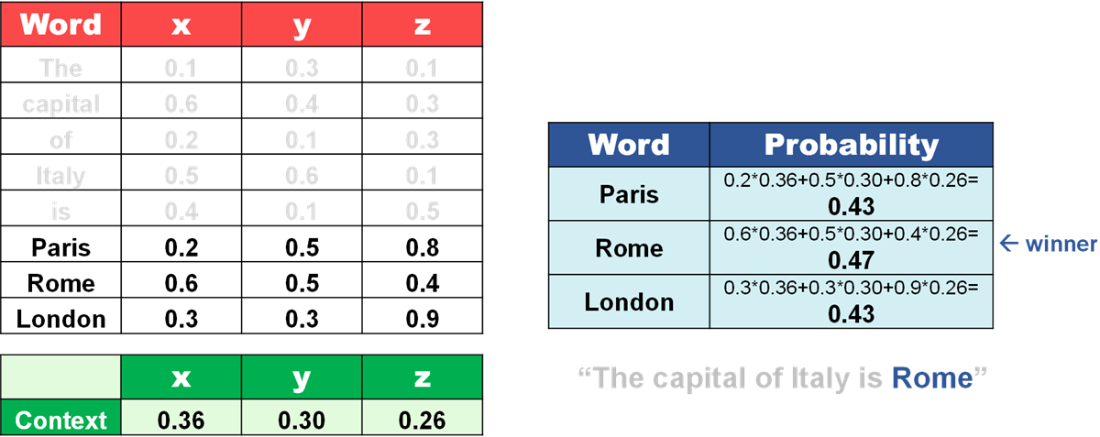
The GPT sentence completion process.
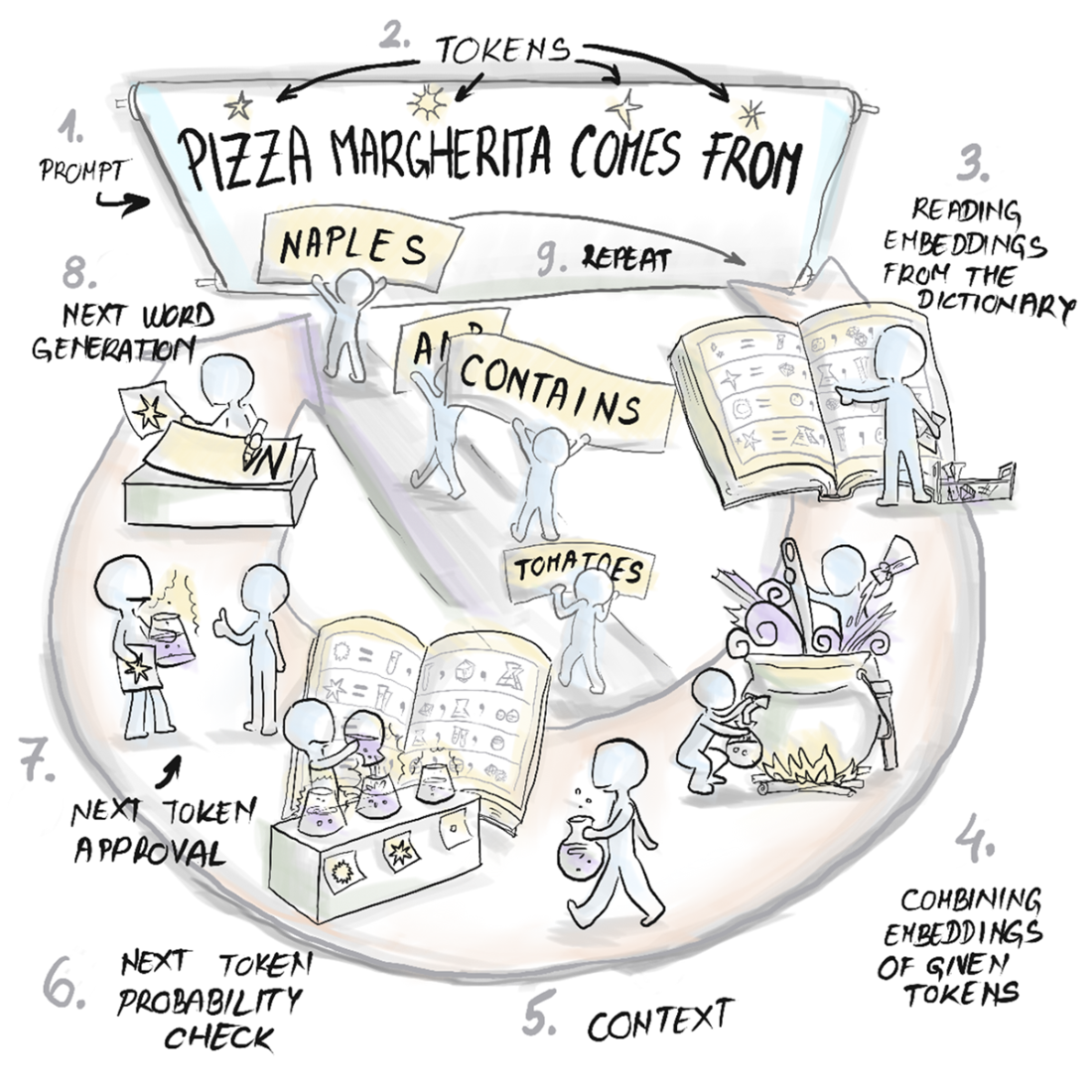
How a GPT architecture generates sentences.
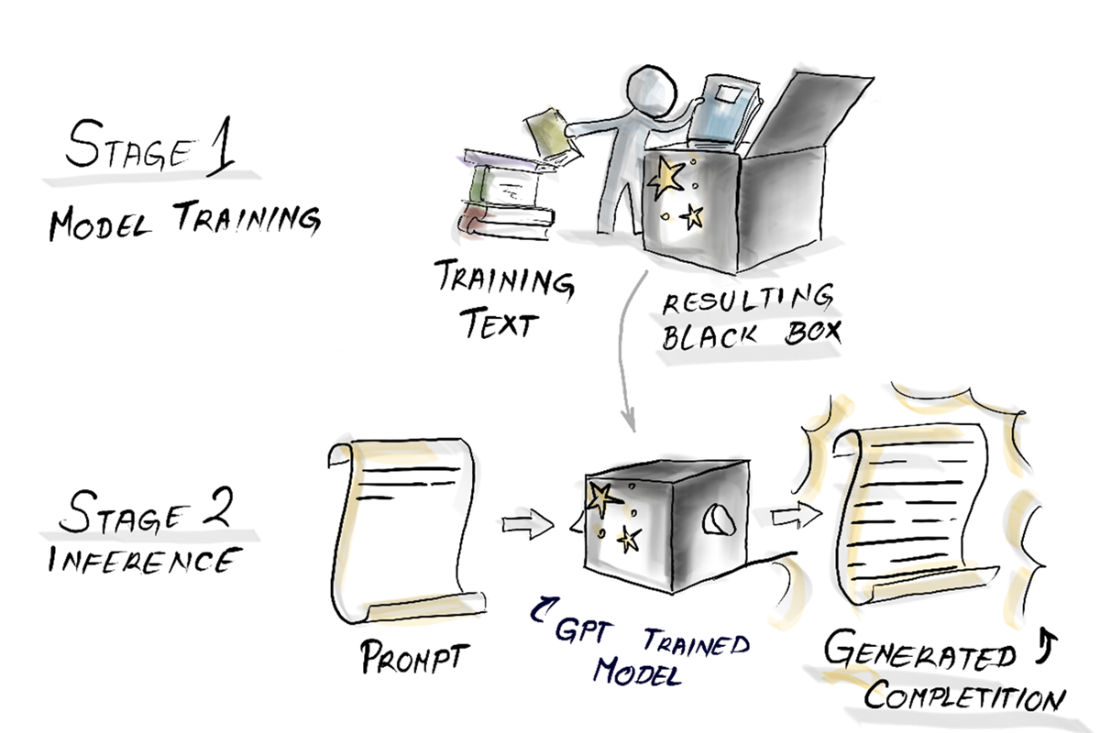
The two stages of GPT-3. First, it gets trained, and then the sentence completion is inferred.
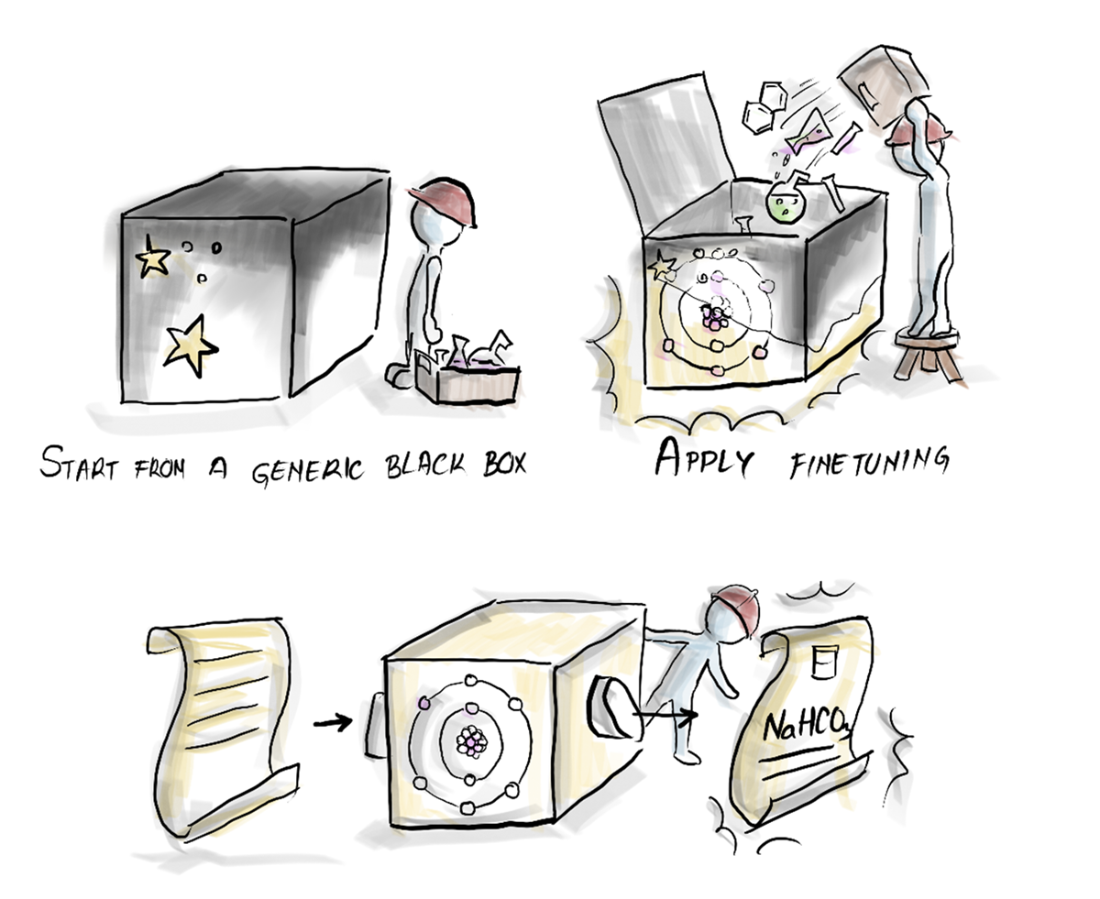
Enhancing a pre-trained model through fine-tuning.
FAQ
What makes GenAI programming different from traditional programming?
Traditional apps follow explicit, deterministic code paths. GenAI apps route part of the workflow through an LLM—an inherently probabilistic “black box” driven by natural-language prompts. You trade strict control for powerful but non-deterministic behavior and must design around that.Why can’t we predict or fully explain an LLM’s exact output?
LLMs generate text by estimating probabilities rather than executing fixed rules. Their deep neural networks are not explanatory: you can’t trace a specific output to a simple, human-readable rule. The result is inherently non-deterministic and opaque.If LLMs are stateless and pre-trained, how do apps like ChatGPT seem to remember and learn?
They don’t truly remember or learn during inference. The application supplies memory by re-sending relevant conversation history on each call, and it supplies “new knowledge” by attaching external context to the prompt. The underlying LLM remains stateless and fixed.How do I add memory to a GenAI application?
Store prior turns (user messages and model outputs), optionally summarize them to fit the context window, and prepend the relevant history to each new prompt. This makes each call self-contained so the LLM can “remember” without having state.How can I provide up-to-date or private knowledge to the model?
Inject it into the prompt at call time. For small corpora, you can attach full text; otherwise, search your knowledge base for relevant snippets and include only those. This overcomes the model’s static, pre-trained knowledge and knowledge cutoff.What is Retrieval-Augmented Generation (RAG)?
RAG retrieves relevant documents from an external store (e.g., company policies, fresh web data) and augments the prompt with those snippets before generation. Benefits include more accurate, current, and grounded answers with fewer hallucinations.How do GPT-style models generate text, in simple terms?
They tokenize input, map tokens to high-dimensional embeddings, compute context with deep transformer networks (attention + position), produce a probability distribution over next tokens, select one, append it, and repeat—building text autoregressively.What are tokens, embeddings, and the context window?
- Tokens: the text units the model reads/writes (words, subwords, punctuation).- Embeddings: numeric vectors capturing token meaning (GPT-3 uses 12,288 numbers per token and ~50k tokens).
- Context window: the max tokens processed at once (GPT-3 ~2,048; modern models are larger). It limits how much history and knowledge you can include.
What’s the difference between pre-training, inference, fine-tuning, and RLHF?
- Pre-training: learns language patterns from huge text (e.g., ~45 TB) to set billions of parameters (GPT-3: 175B).- Inference: applies those fixed parameters to your prompt to generate text (knowledge cutoff applies).
- Fine-tuning: supervised passes on specific examples to specialize the model.
- RLHF: improves responses via human feedback and preference ranking.
Beyond the LLM, what else do production GenAI apps need?
- Memory management (conversation state).- Knowledge retrieval (e.g., RAG) for fresh/private data.
- Tool use and action-taking via APIs (send emails, fetch data).
- Prompt engineering to control tone/objectives.
- Multi-agent designs where specialized agents collaborate.
Tools like LangFlow help assemble these components.
 AI Applications Made Easy ebook for free
AI Applications Made Easy ebook for free