1 Introduction to DeepSeek
Large language models now write, reason, and code at near-human levels, and this book invites a technically curious reader to build one from the ground up. Centering on DeepSeek, an open-source model that marked a turning point by matching the performance of leading proprietary systems at a fraction of the cost, the chapter sets the motivation: learn modern LLMs by reconstructing their core ideas in code. The goal is both practical mastery and deeper understanding, aligning with the broader spirit of democratizing AI through transparent methods and hands-on learning.
The chapter outlines the pillars behind DeepSeek’s leap: architectural swaps that replace standard attention with Multi-Head Latent Attention to relieve speed and memory pressure, and feed-forward blocks with a Mixture-of-Experts to scale capacity efficiently. It introduces a new training objective, Multi-Token Prediction, to speed learning and inference, and FP8 quantization to push computational efficiency. Beyond architecture, the training pipeline overlaps tasks to keep hardware saturated, and post-training blends supervised fine-tuning, reinforcement learning, and rejection sampling to instill strong reasoning—culminating in DeepSeek-R1. Finally, knowledge distillation compresses capabilities into smaller, practical checkpoints spanning roughly 1.5B to 70B parameters.
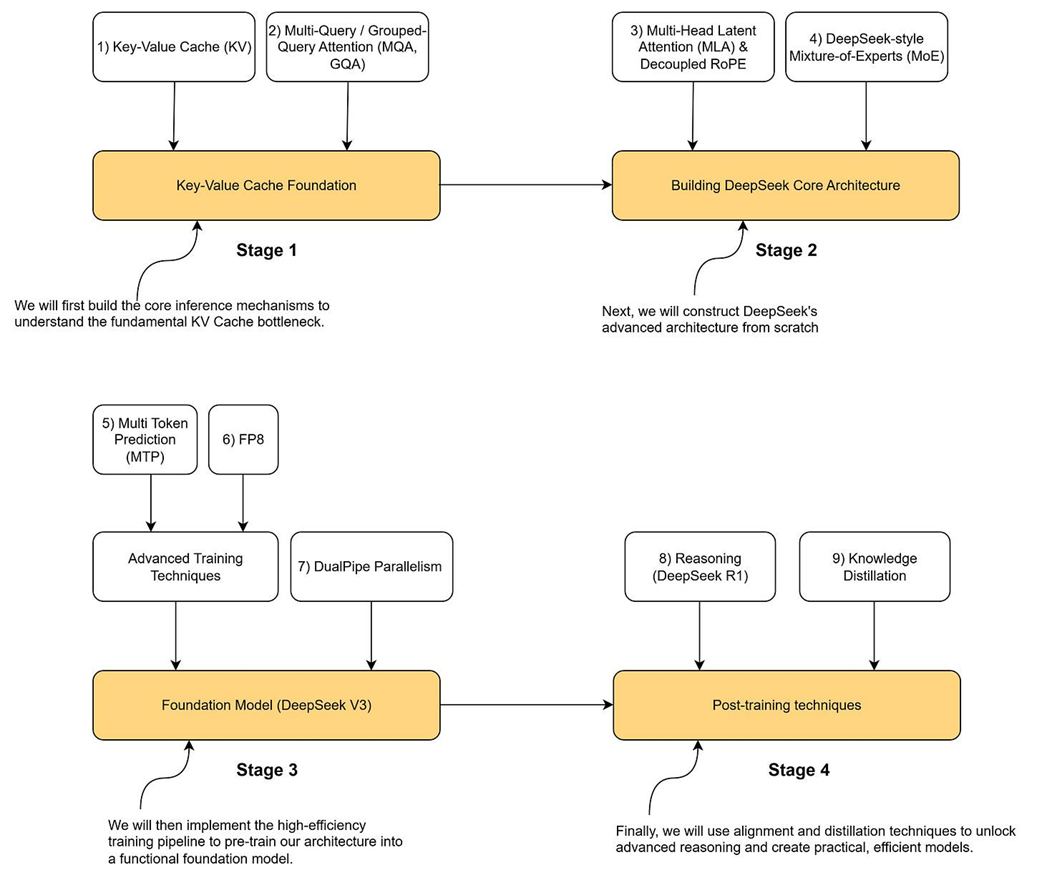
Readers are given a four-stage roadmap: foundational inference concepts (including the KV cache), core architecture (MLA and MoE), advanced training (MTP, FP8, and parallelism), and post-training (supervised fine-tuning, RL, and distillation). The book focuses on principles and reproducible implementations rather than proprietary data, exact weights, or production deployment. Prerequisites include Python, basic deep learning, and a working grasp of transformers; experiments are designed to run on consumer hardware, from CPUs to single GPUs with 8–12GB of VRAM, with larger GPUs simply enabling richer explorations. The promise is a clear, step-by-step path to understanding—and building—a mini-DeepSeek that captures the essence of state-of-the-art LLM design.
A simple interaction with the DeepSeek chat interface.

The title and abstract of the DeepSeek-R1 research paper.

A detailed view of a standard Transformer block, the foundational architecture used in models like LLaMA and the GPT series. It is composed of a multi-head attention block and a feed-forward network (NN).
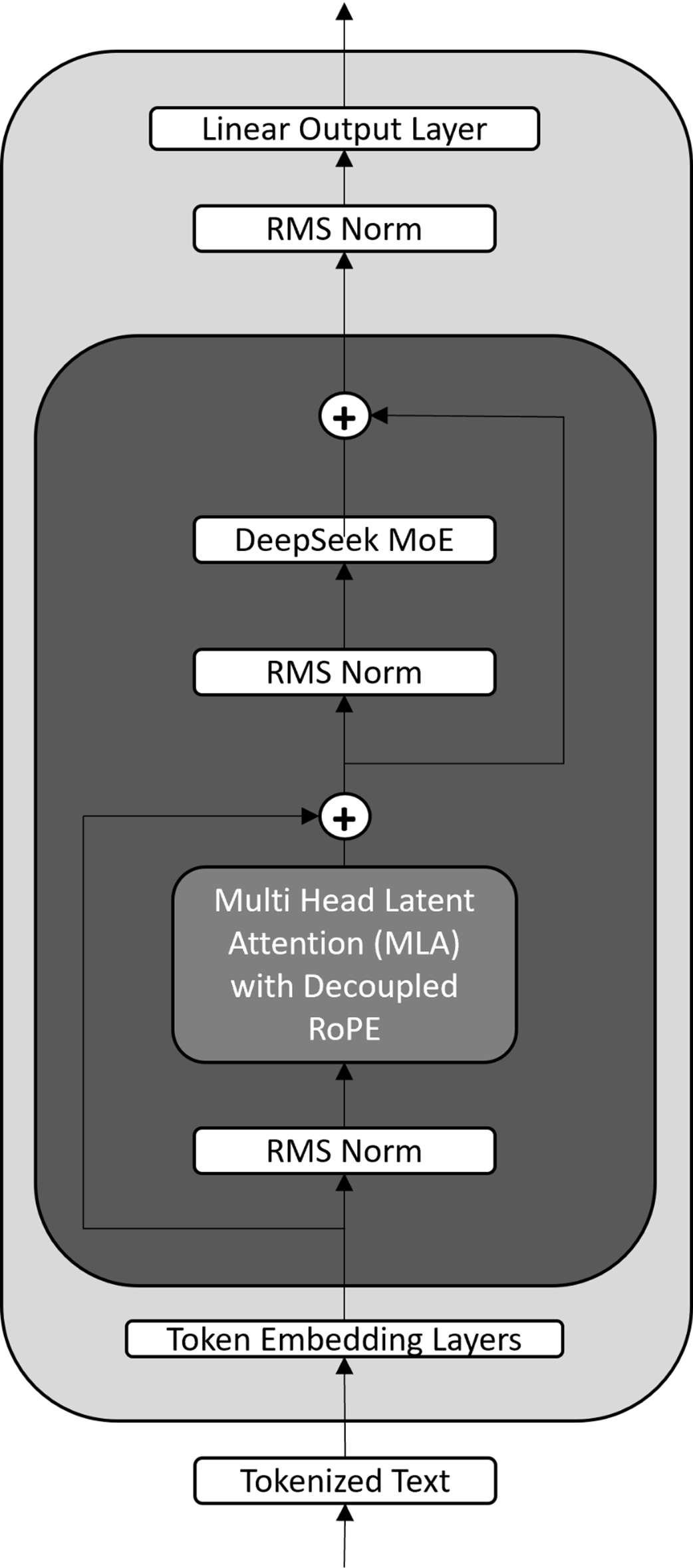
A simplified view of the DeepSeek model architecture. It modifies the standard Transformer by replacing the core components with Multi-Head Latent Attention (MLA) and a Mixture-of-Experts (MoE) layer. This design also utilizes RMS Norm (Root Mean Square Normalization) and a specialized Decoupled RoPE (Rotary Position Embedding).
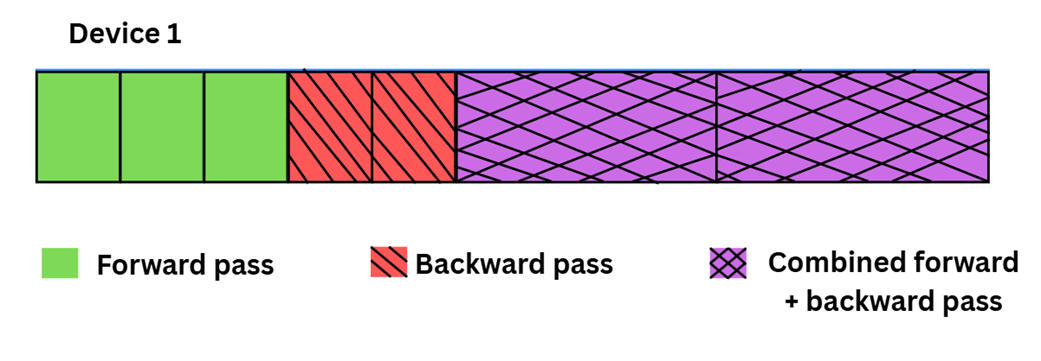
An illustration of the DualPipe training pipeline on a single device. By overlapping the forward pass (the initial blocks), backward pass (the hatched blocks), and combined computations, this scheduling strategy minimizes GPU idle time and maximizes hardware utilization during large-scale training.
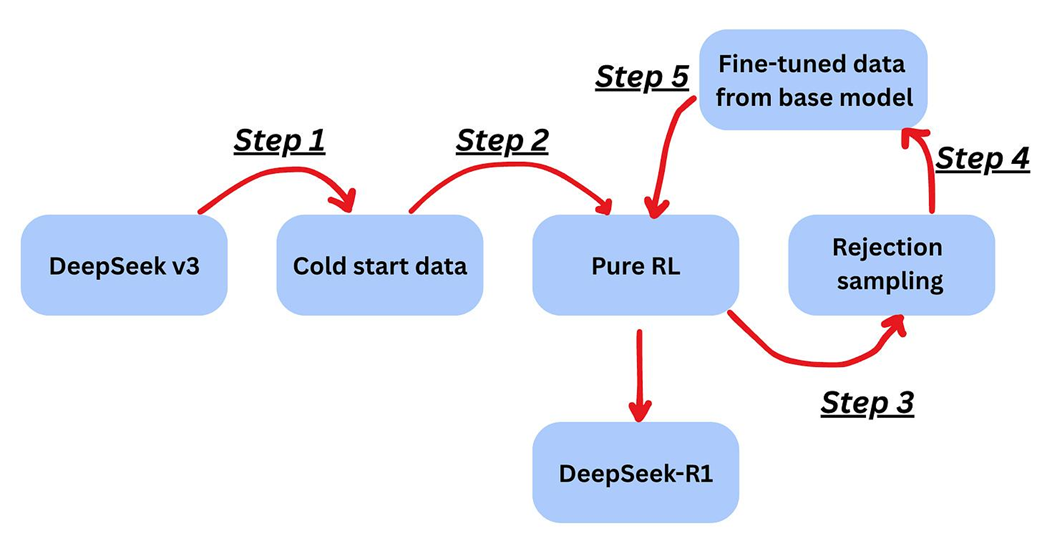
The multi-step post-training pipeline used to create DeepSeek-R1 from the DeepSeek-V3 base model. This process involves a combination of reinforcement learning (Pure RL), data generation (Rejection sampling), and fine-tuning to instill advanced reasoning capabilities.
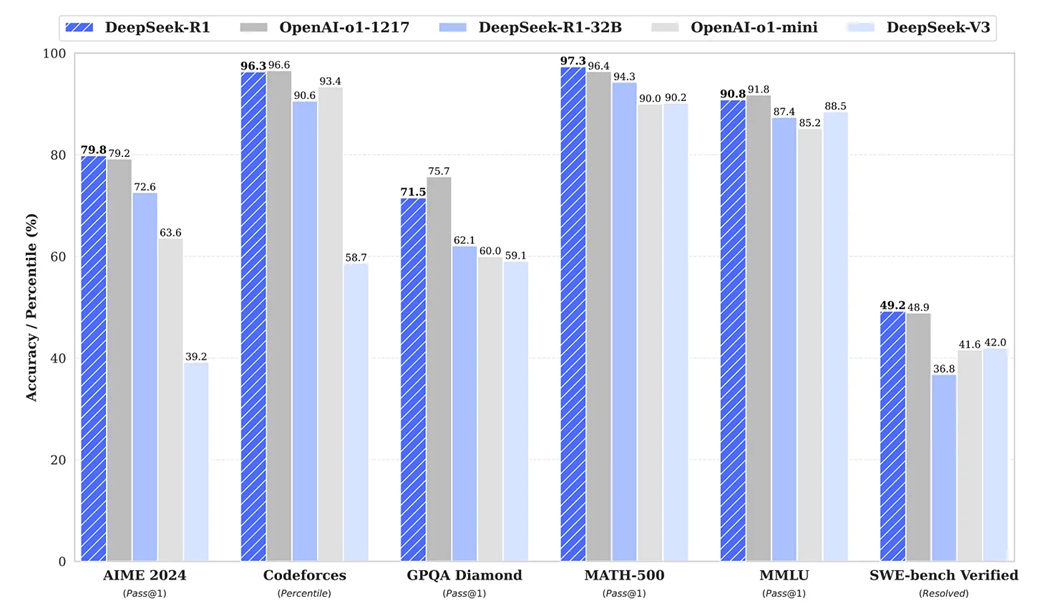
Benchmark performance of DeepSeek-R1 against other leading models (as of January 2025).
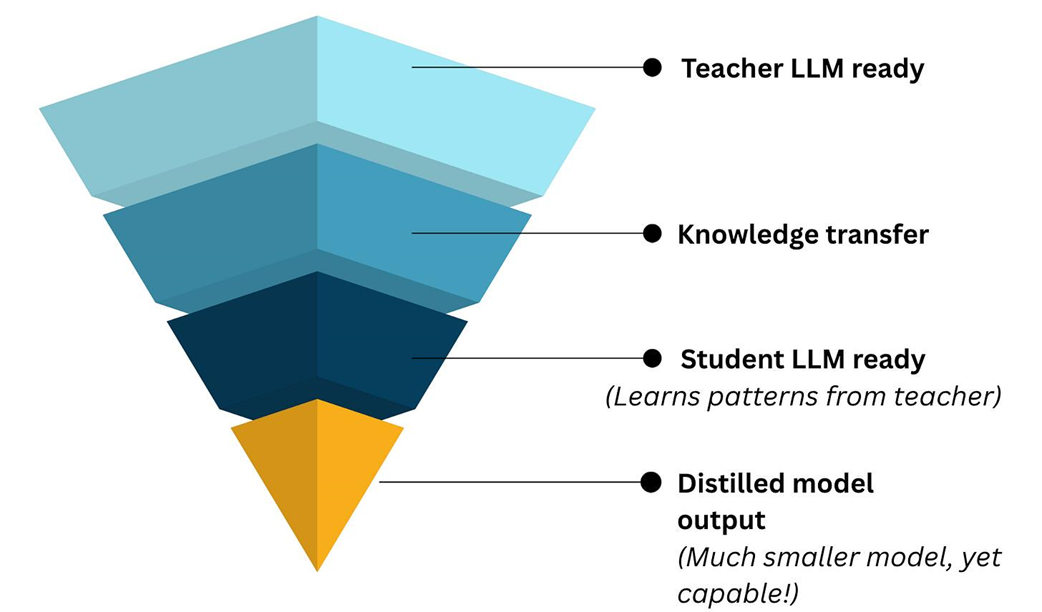
The concept of knowledge distillation. A large, powerful "teacher" model (like DeepSeek-R1) is used to generate training data to teach a much smaller, more efficient "student" model, transferring its capabilities without the high computational cost.
The four-stage roadmap for building a mini-DeepSeek model in this book. We will progress from foundational concepts (Stage 1) and core architecture (Stage 2) to advanced training (Stage 3) and post-training techniques (Stage 4), implementing each key innovation along the way.
Summary
- Large Language Models (LLMs) have become a dominant force in technology, but the knowledge to build them has often been confined to a few large labs.
- DeepSeek marked a pivotal moment by releasing open-source models with performance that rivaled the best proprietary systems, demonstrating that cutting-edge AI could be developed and shared openly.
- This book will guide you through a hands-on process of building a mini-DeepSeek model, focusing on its key technical innovations to provide a deep, practical understanding of modern LLM architecture and training.
- The core innovations we will implement are divided into four stages: (1) KV Cache Foundation, (2) Core Architecture (MLA & MoE), (3) Advanced Training Techniques (MTP & FP8), and (4) Post-training (RL & Distillation).
- By building these components yourself, you will gain not just theoretical knowledge but also the practical skills to implement and adapt state-of-the-art AI techniques.
FAQ
Why is DeepSeek presented as a turning point in open-source AI?
DeepSeek demonstrated that an openly available model can rival top proprietary systems. Its R1 model, released in early 2025, matched or exceeded leading models (e.g., OpenAI’s o1-1217) on tough reasoning benchmarks like AIME 2024 and competitive coding, while being trained at a fraction of the cost. It also pushed openness by releasing weights and detailing methods.What will I build and learn in this book?
You will build a mini-DeepSeek model from scratch, learning the core architectural ideas (Multi-Head Latent Attention and Mixture-of-Experts), the training objective (Multi-Token Prediction), efficiency techniques (FP8 quantization, DualPipe scheduling), and post-training methods (reinforcement learning and distillation). The focus is on understanding and implementing each component step by step.How does DeepSeek’s architecture differ from a standard Transformer?
While built on the Transformer foundation, DeepSeek replaces standard multi-head attention with Multi-Head Latent Attention (MLA) and the feed-forward network with a Mixture-of-Experts (MoE) layer. It also uses RMSNorm and a decoupled RoPE variant. These changes target speed/memory bottlenecks and scaling/model capacity challenges.What is Multi-Head Latent Attention (MLA) and why does it matter?
MLA is DeepSeek’s attention mechanism that tackles the speed and memory bottleneck of standard attention, especially on long sequences. It reduces the heavy compute/memory pressure while maintaining quality, enabling more efficient inference and training. The book starts from standard attention and builds up to MLA to show how and why it works.What is the Mixture-of-Experts (MoE) layer in DeepSeek?
MoE replaces the standard feed-forward block with multiple “experts.” A router sends tokens to a subset of experts, increasing model capacity without activating all parameters for every token. This design scales model capability efficiently and balances computational load across experts.What is Multi-Token Prediction (MTP)?
MTP is a training objective that predicts multiple future tokens at once. By supervising several steps ahead, it accelerates learning and can speed up inference, improving overall training efficiency compared to single-token prediction.What is FP8 quantization and how does it help?
FP8 quantization compresses weights and activations into an 8-bit floating-point format. This reduces memory footprint and speeds up computation while preserving model quality, making large models more practical to train and serve.How does the training pipeline (DualPipe) maximize hardware utilization?
DualPipe overlaps the forward pass of the current batch with the backward pass of the previous batch. By coordinating data loading, preprocessing, and compute, the GPU stays busy with minimal idle time, improving throughput during large-scale training.What post-training steps created DeepSeek-R1 from DeepSeek-V3?
- Step 1 (Foundation): Lightly fine-tune the base model (DeepSeek-V3) with a small “cold-start” dataset.
- Step 2 (Pure RL): Apply reinforcement learning to discover effective reasoning strategies.
- Step 3 (Self-Labeling): Use rejection sampling to generate and select high-quality synthetic data.
- Step 4 (Blending Data): Combine synthetic data with supervised examples.
- Step 5 (Final RL): Finish with a broad RL phase to improve robustness and generalization.
Who is this book for, and what are the prerequisites and hardware needs?
You should be comfortable with Python, basics of backpropagation, and core PyTorch ops, with some exposure to Transformers. A CPU-only laptop can run most examples (slowly), while a single 8–12GB VRAM GPU is recommended; 24–48GB helps for larger MoE experiments. The book does not reproduce proprietary data, train 100B+ parameter models, or cover production serving and safety systems.What are the core innovations the book focuses on?
- Architecture: Multi-Head Latent Attention (MLA) and Mixture-of-Experts (MoE)
- Training: Multi-Token Prediction (MTP), FP8 quantization, and DualPipe scheduling
- Post-training: Reinforcement learning and model distillation to produce practical, smaller models
 Build a DeepSeek Model (From Scratch) ebook for free
Build a DeepSeek Model (From Scratch) ebook for free