4 Mixture-of-Experts (MoE) in DeepSeek: Scaling intelligence efficiently
Mixture-of-Experts (MoE) replaces the Transformer’s dense feed-forward networks with a pool of smaller, specialized “experts,” and activates only a few per token via a learned router. This sparsity lets models amass far more total parameters without proportional compute, because most experts stay idle for any given token. During pretraining, experts naturally specialize (e.g., grammar, domains, patterns), so the router can dispatch tokens to the most relevant specialists and then merge their outputs, achieving high capacity at low per-token cost.
Mechanically, the router computes expert scores per token with a linear projection, applies top-k selection to enforce sparsity, normalizes the kept scores with softmax, and forms the final representation as a weighted sum of the chosen experts’ outputs—preserving the input/output shape expected by the Transformer. A central challenge is load imbalance: some experts can become hotspots while others “die.” Traditional remedies include an auxiliary loss that penalizes variance in expert importance, a load-balancing loss that aligns expert probabilities with actual routed token fractions, and a capacity factor that hard-limits tokens per expert to prevent overloads.
DeepSeek advances MoE along three fronts. First, fine-grained expert segmentation uses many smaller experts to curb knowledge hybridity and sharpen specialization without increasing total capacity. Second, shared expert isolation splits the layer into dense shared experts (holding common, reusable knowledge) and routed experts (freed to specialize deeply), with outputs summed alongside the residual path. Third, auxiliary-loss-free load balancing introduces a dynamic, per-expert bias on router logits that is updated each step to nudge routing toward underused experts and away from overloaded ones—decoupling balance from the main training objective. A from-scratch implementation demonstrates these ideas in practice, and empirical results show lower validation loss and higher throughput than a standard MoE, validating both efficiency and effectiveness.
Our four-stage journey to build the DeepSeek model. This chapter focuses on the highlighted component, DeepSeek-style Mixture-of-Experts (MoE), the second major innovation in the core architecture.
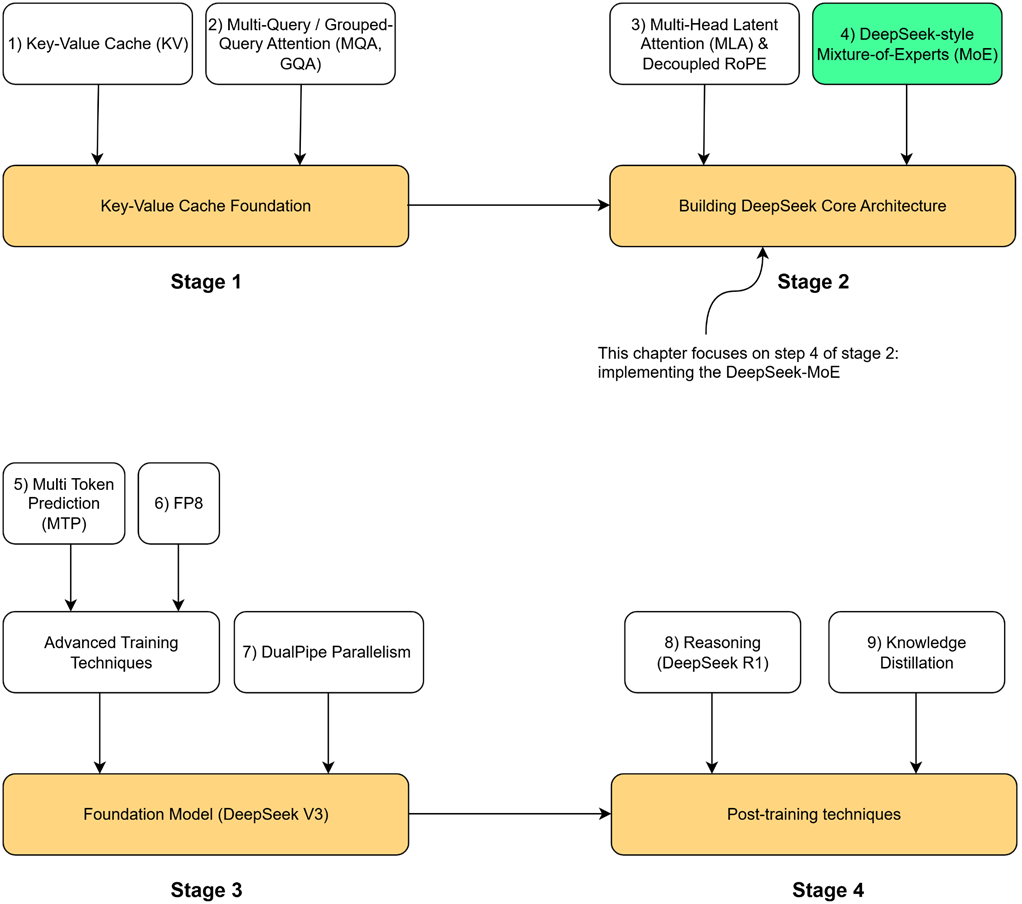
The standard Feed-Forward Network (FFN) in a Transformer block, featuring an expansion-contraction architecture.
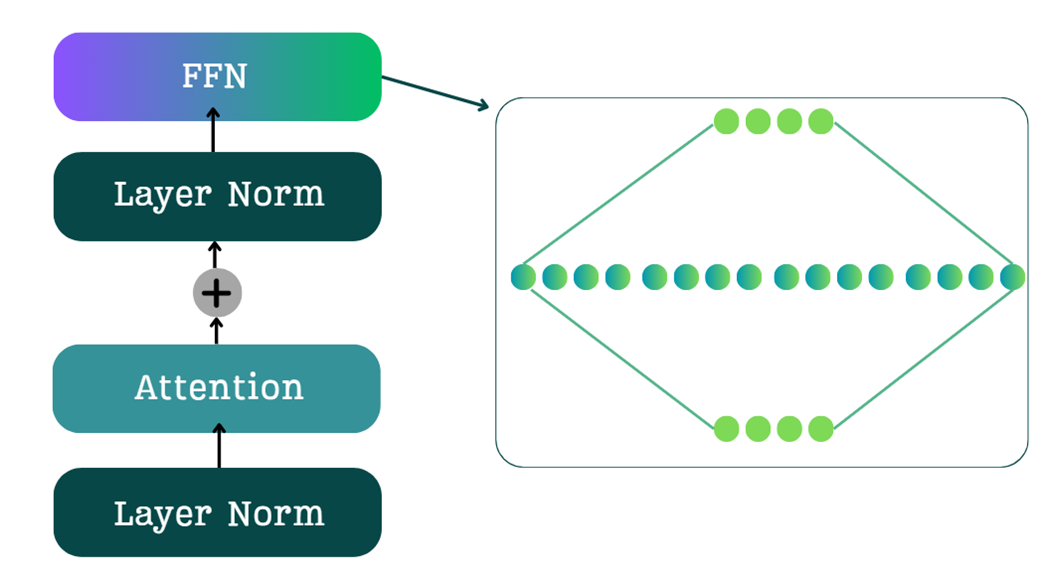
The architectural change of MoE. The single, dense FFN is replaced by a collection of four smaller, specialized expert networks.
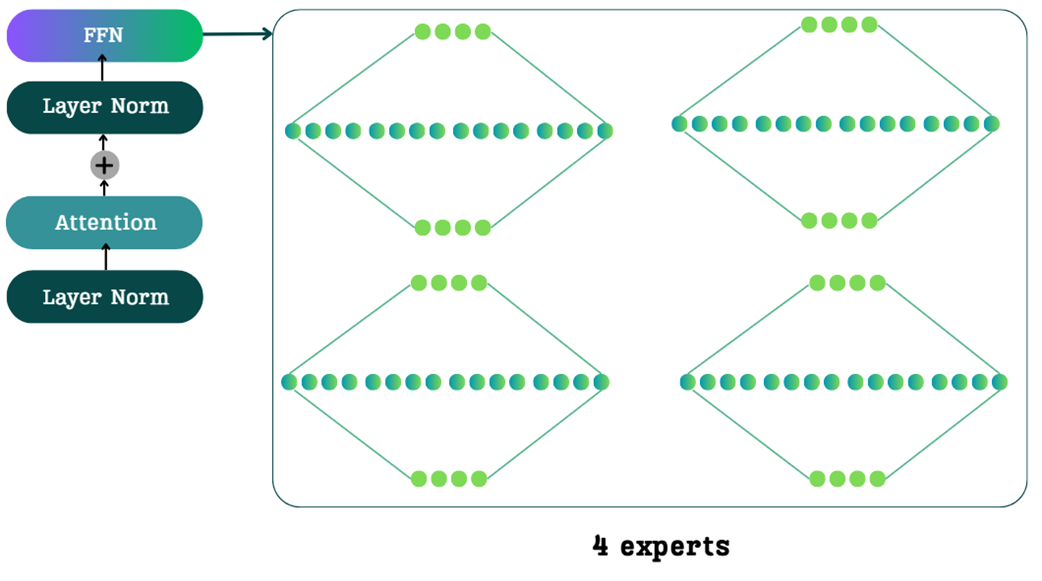
An example of expert routing in a Mixture-of-Experts model. For the input "What is 1+1?", the router must decide which specialized experts to activate. The routing mechanism might prioritize grammatical components (like the question mark and the verb "is"), highlighting how routing is a nuanced decision based on learned patterns.
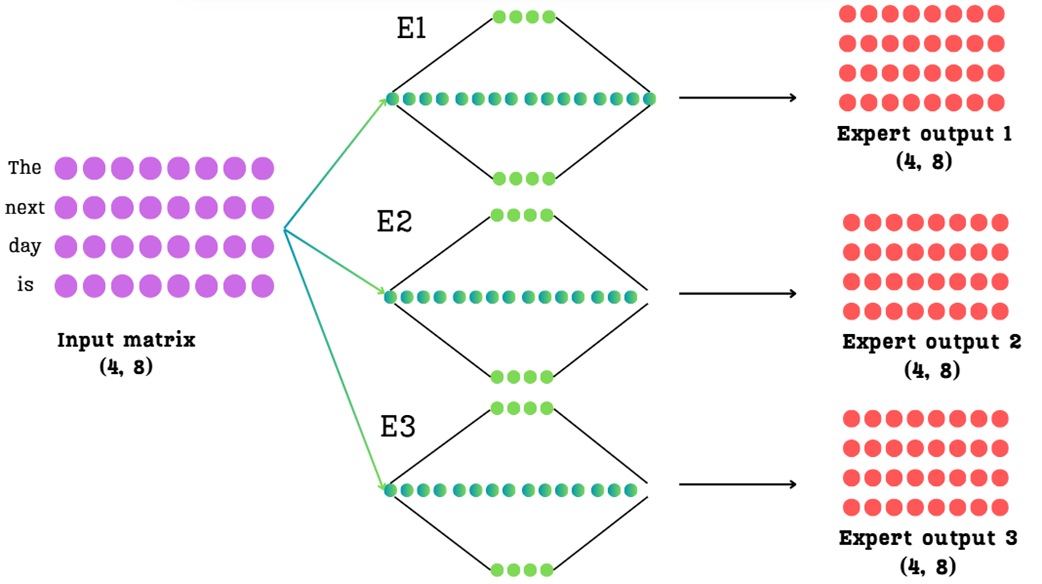
The initial challenge of MoE. The input matrix is passed through each of the three expert networks in parallel, resulting in three separate expert output matrices.
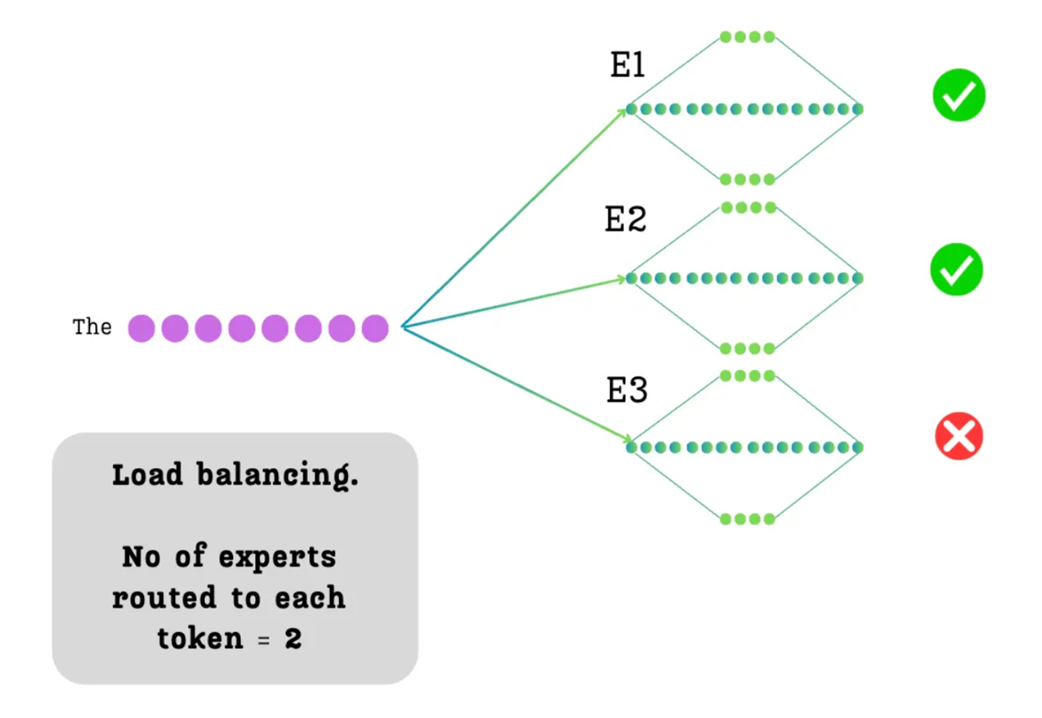
The principle of sparsity or load balancing. For each token, we decide to route it to only a subset (k=2) of the available experts.
The routing mechanism. The input matrix is multiplied by a learned routing matrix to produce an expert selector matrix, which contains a raw score for each expert for each token.

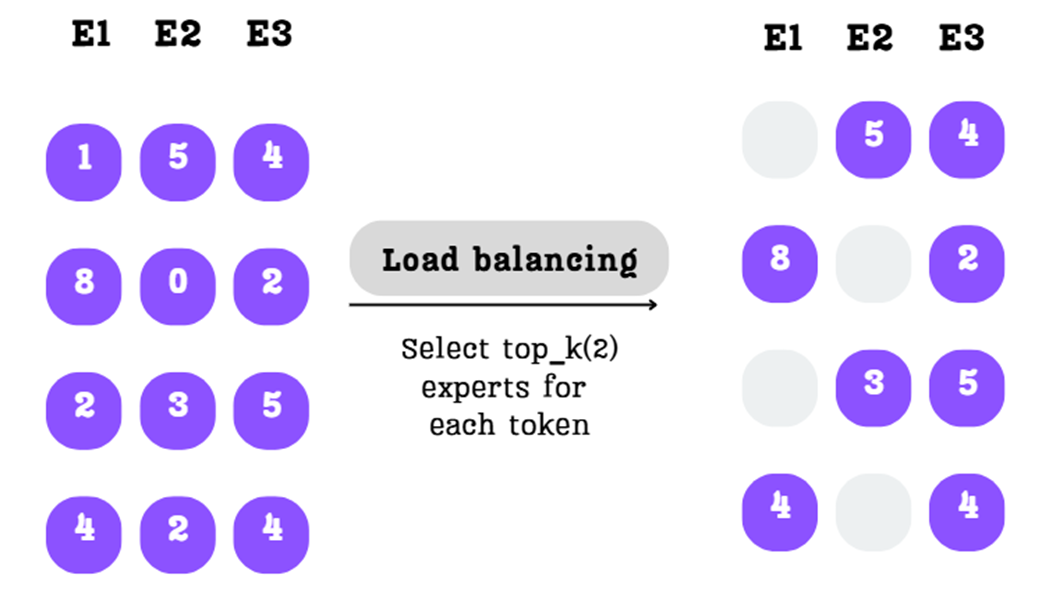
The top-k selection process. For each row, only the two highest scores are kept, and the rest are masked out.
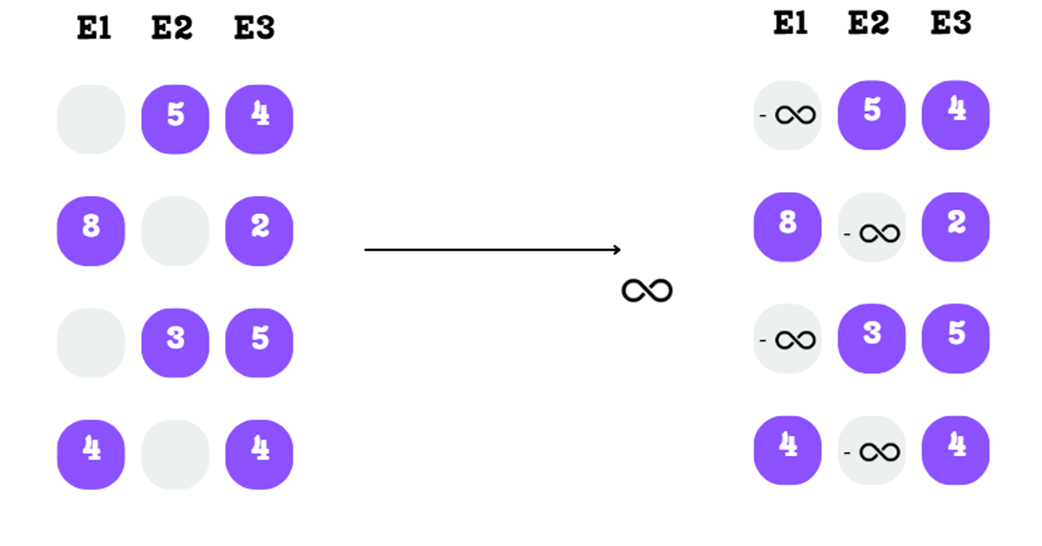
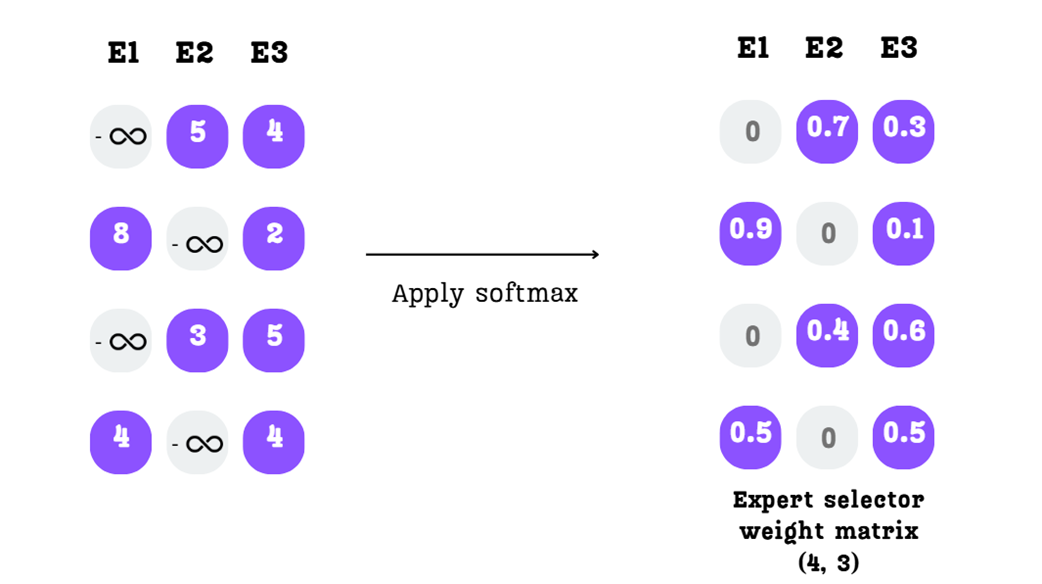
The masked scores are replaced with negative infinity in preparation for the softmax function.
The softmax function converts the scores into a final expert selector weight matrix.
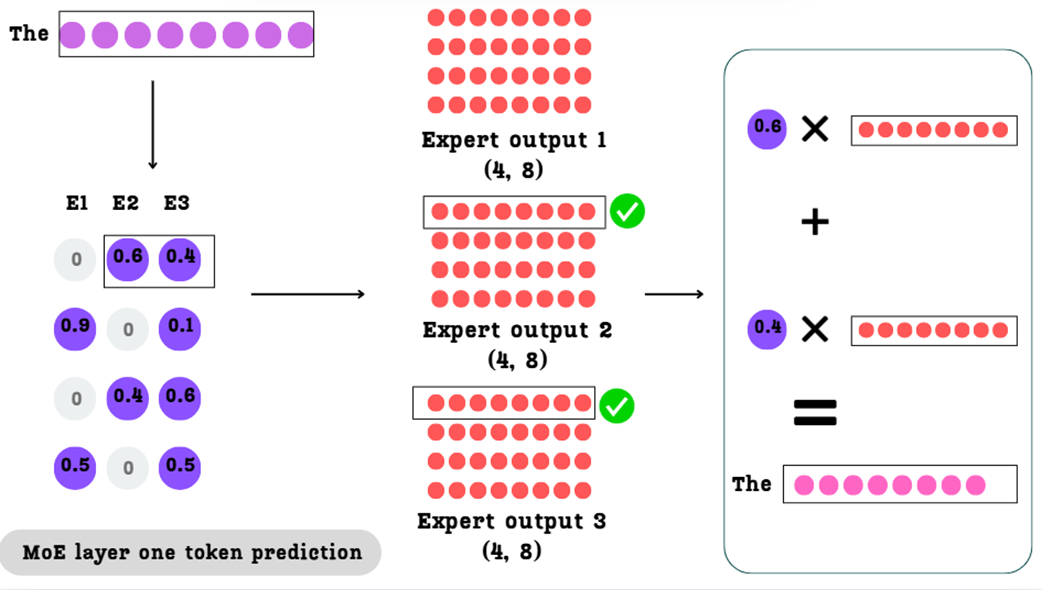
Calculating the final output for a single token. The weights from the selector matrix are used to create a weighted sum of the corresponding expert outputs.
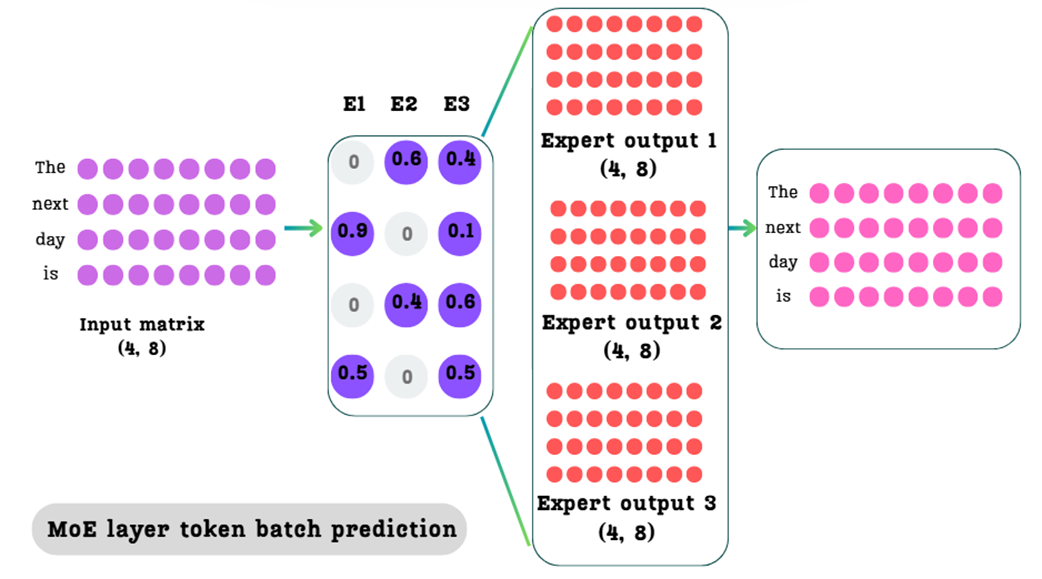
The complete MoE process for a batch of tokens. The expert selector weight matrix guides the weighted summation of the expert outputs to produce a single, final output matrix of the same shape as the input.
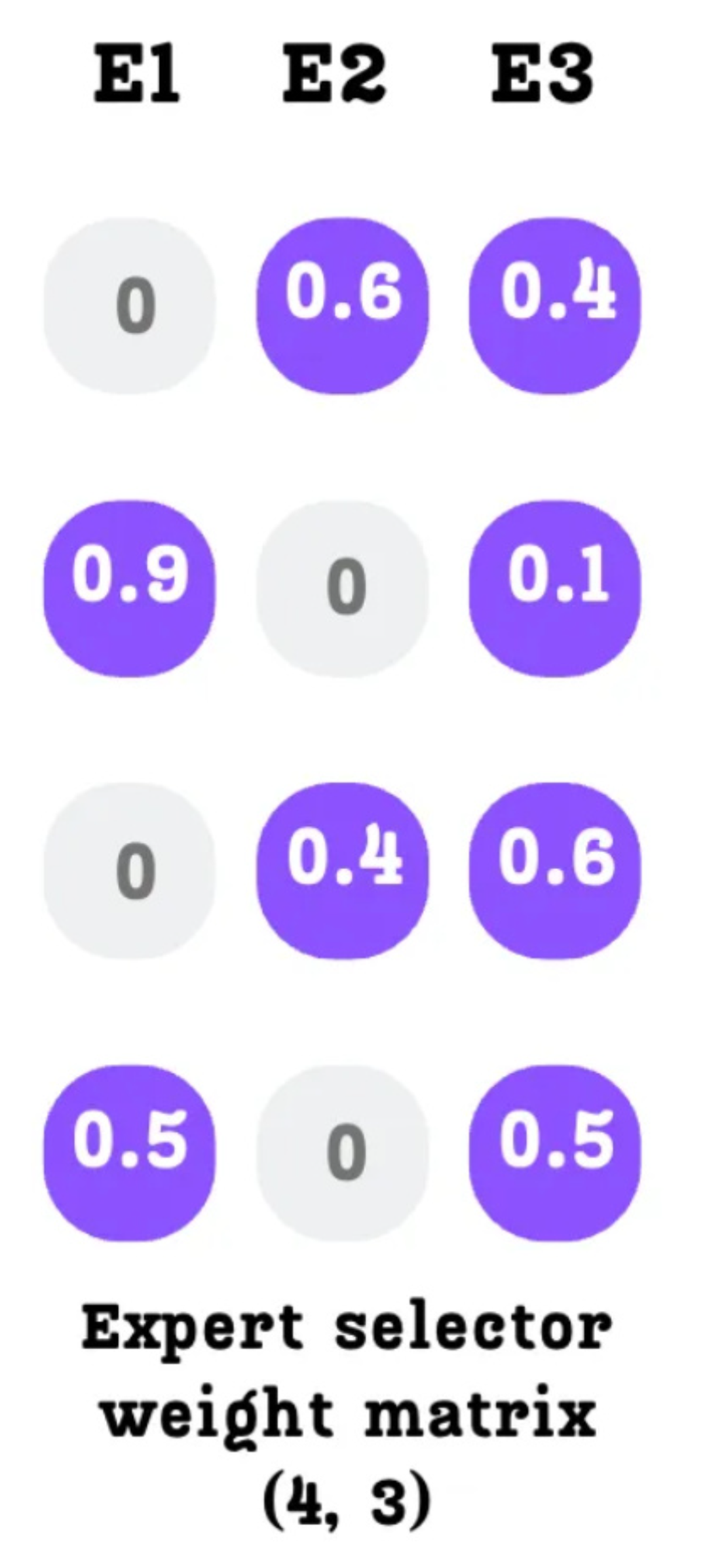
The Expert Selector Weight Matrix. Each row corresponds to a token, and each column corresponds to an expert.
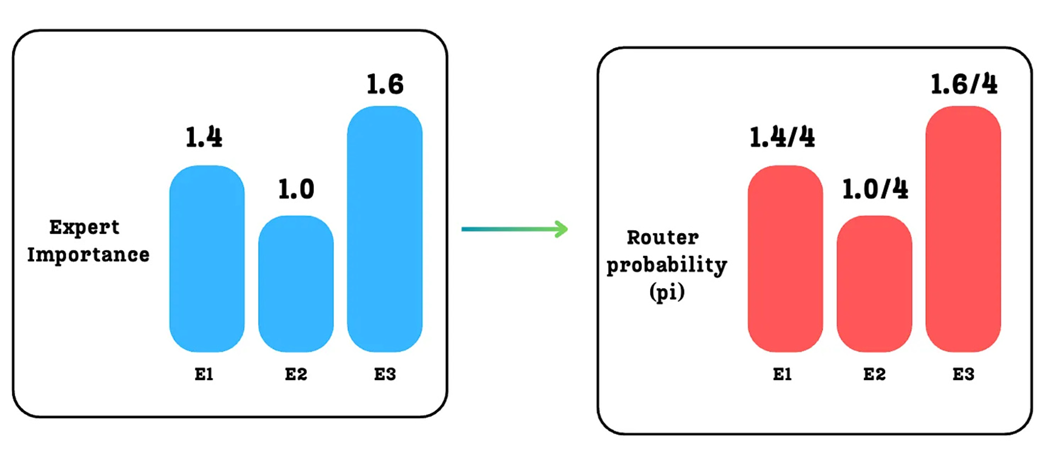
Calculating Expert Importance by summing the probabilities down each column.
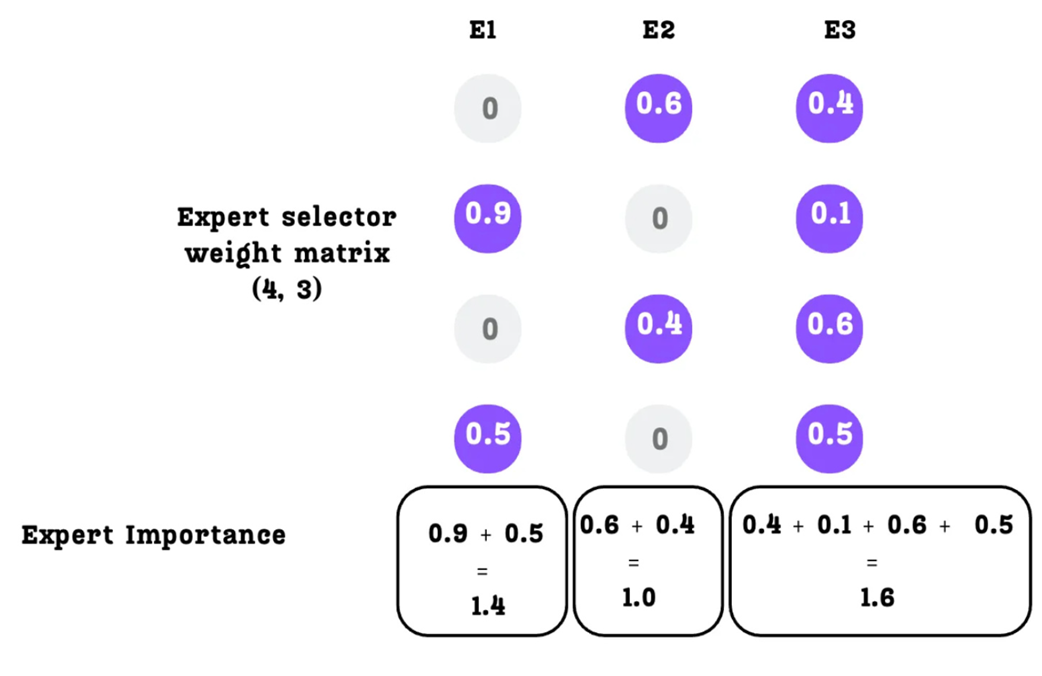
The Auxiliary Loss is calculated from the Coefficient of Variation of the Expert Importance scores.
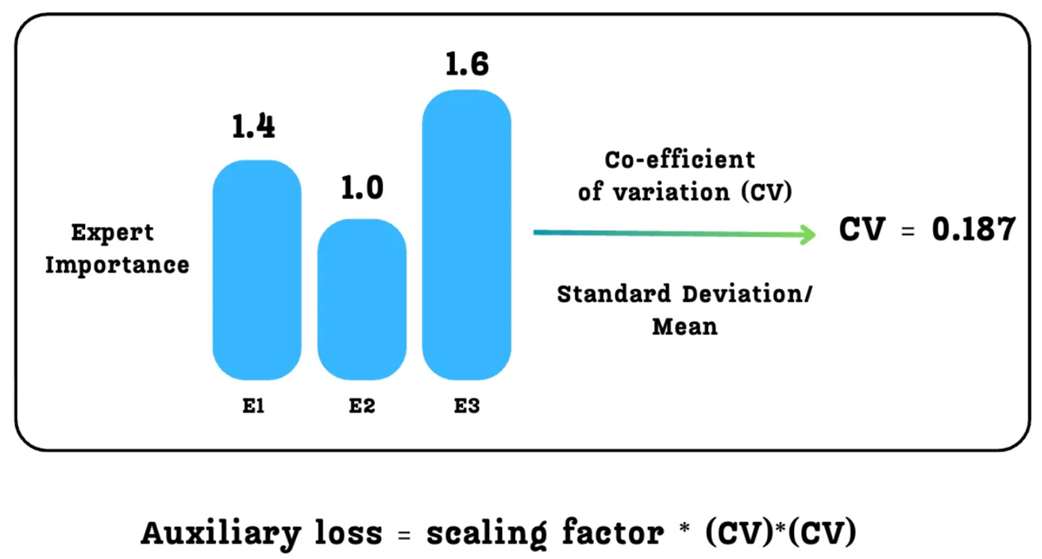
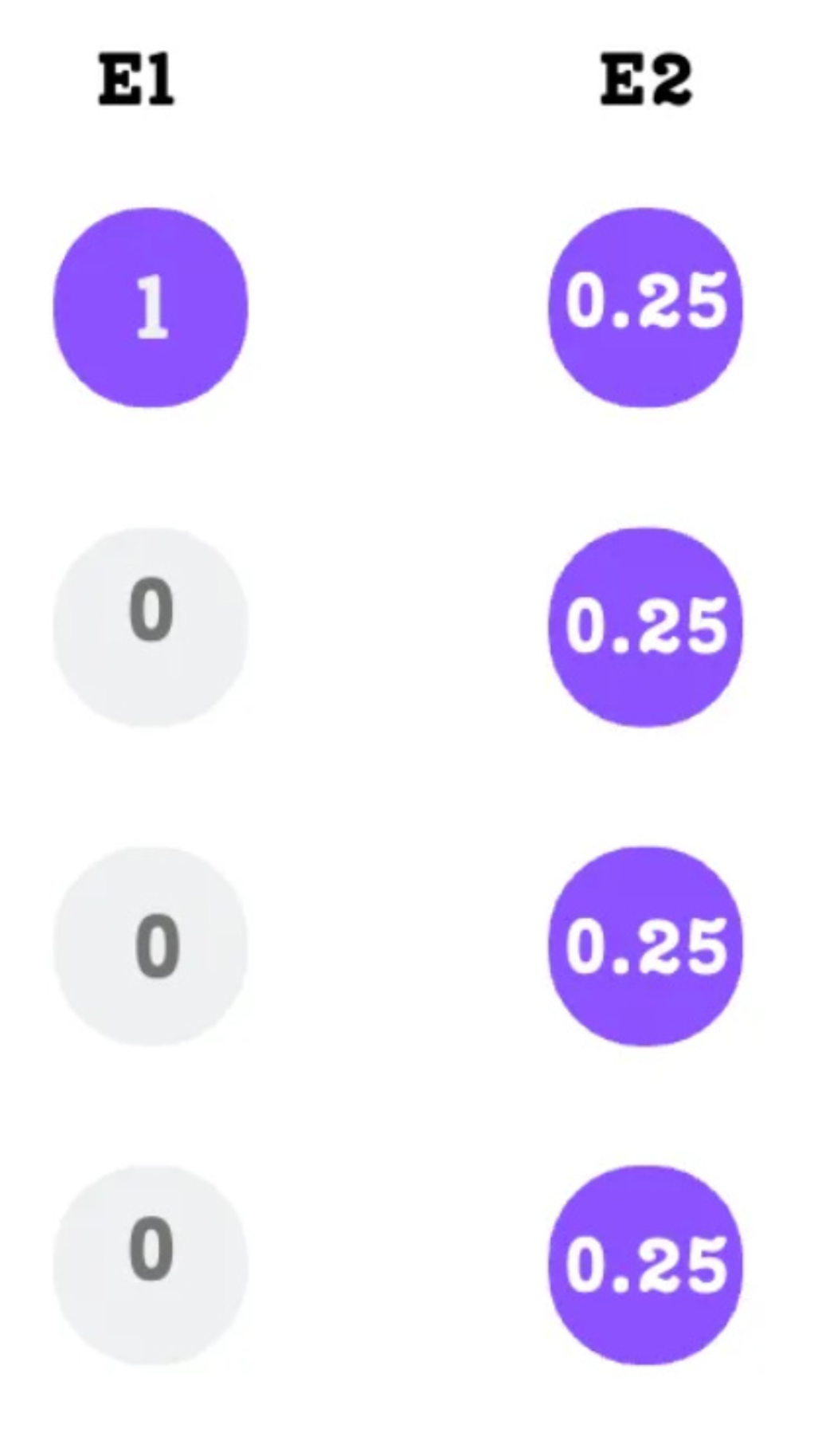
An example demonstrating that equal expert importance does not guarantee a balanced token load.
Calculating the Router Probability (pi) for each expert.
Calculating the Fraction of Tokens Dispatched (fi) for each expert.
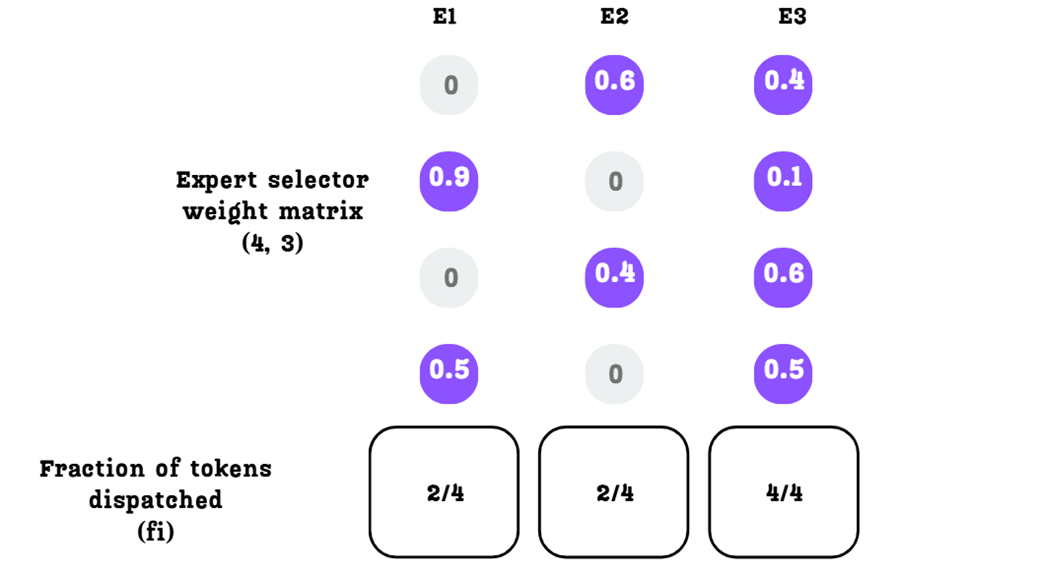
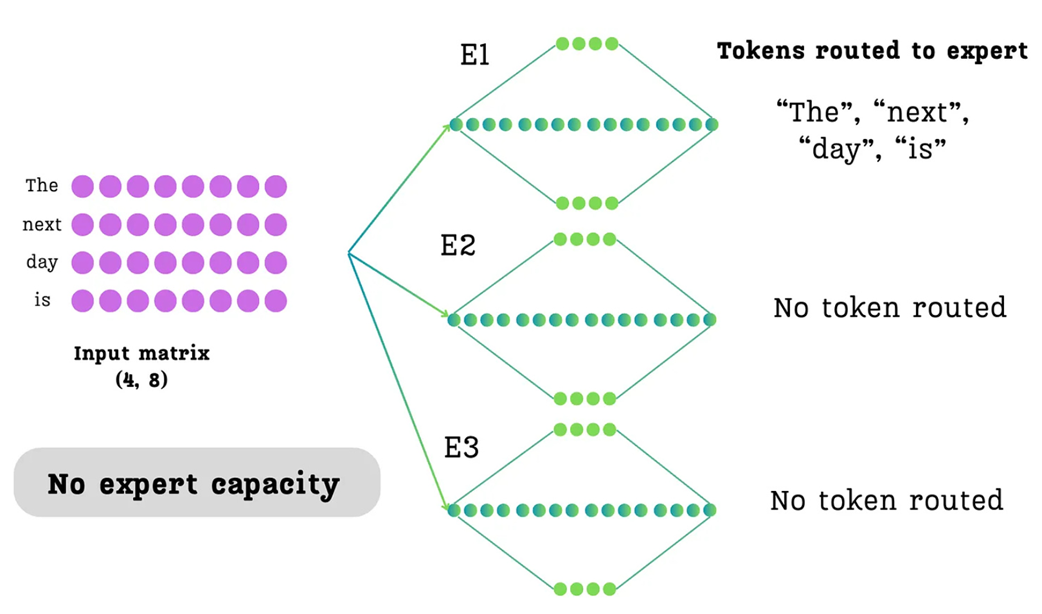
An illustration of imbalanced routing without an expert capacity. In this scenario, the router has sent all tokens in the batch to Expert 1, leaving the other experts idle. This overloading of a single expert is the problem that expert capacity is designed to prevent.
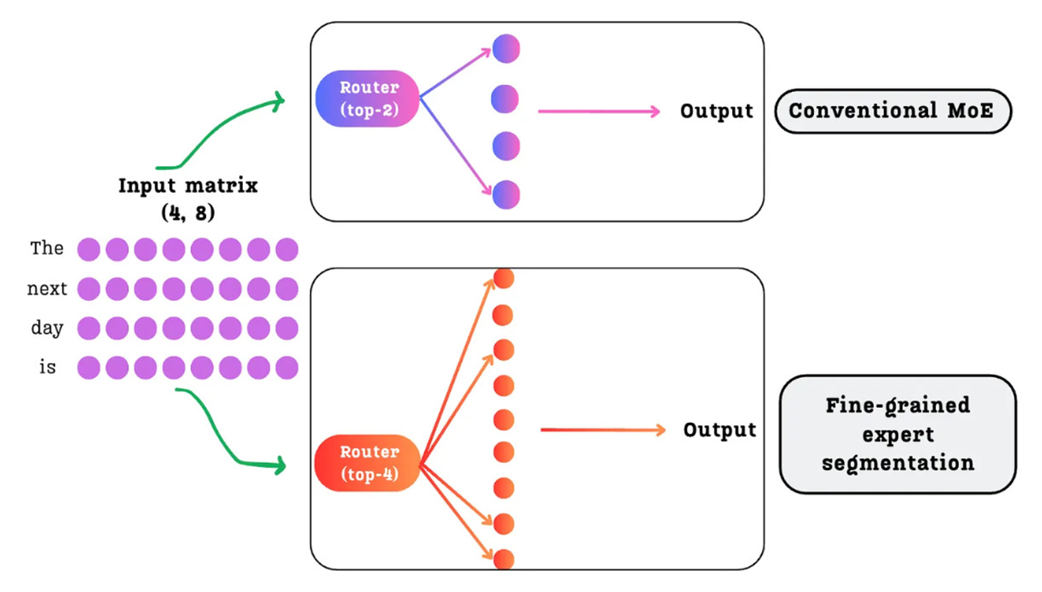
A comparison between a conventional MoE with a few large experts (top) and DeepSeek's fine-grained approach with many smaller experts (bottom).
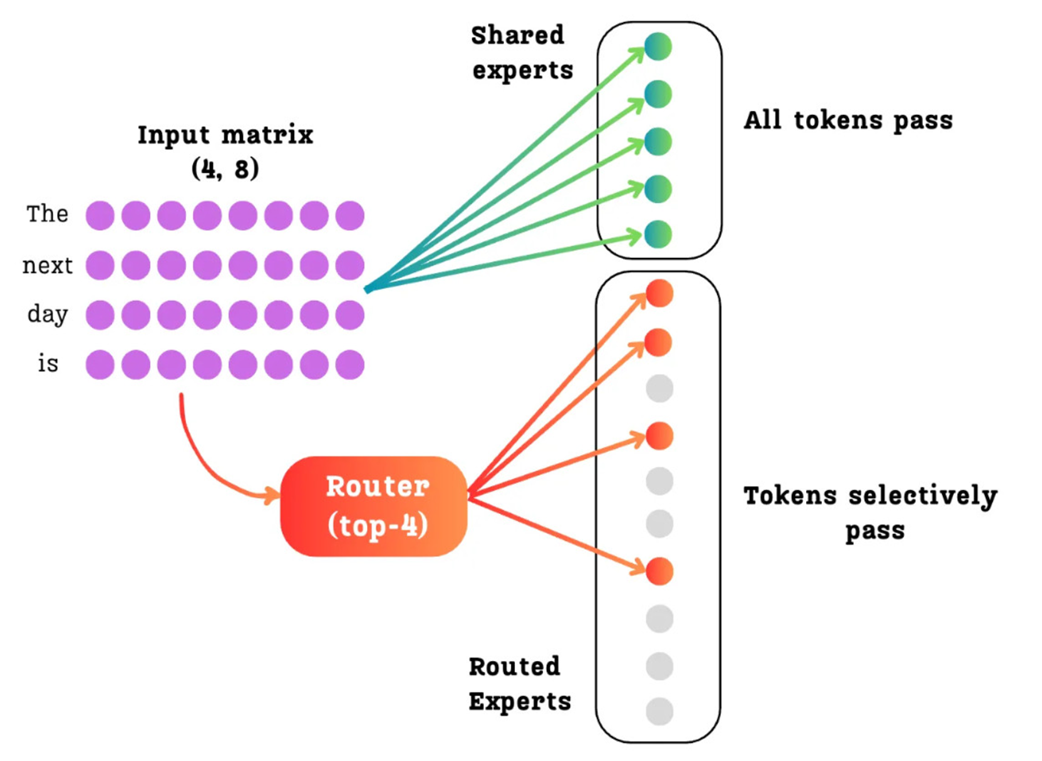
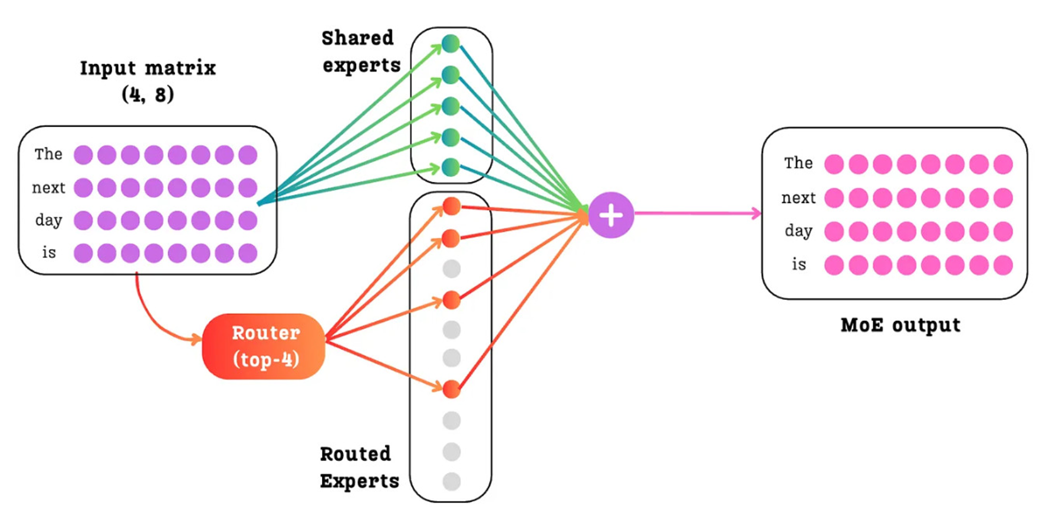
The DeepSeekMoE architecture with Shared and Routed Experts. All tokens are processed by the dense Shared Experts, while the router selectively sends each token to a sparse subset of the Routed Experts.
The final output of the DeepSeekMoE layer is the sum of the outputs from the dense shared experts and the sparse routed experts.
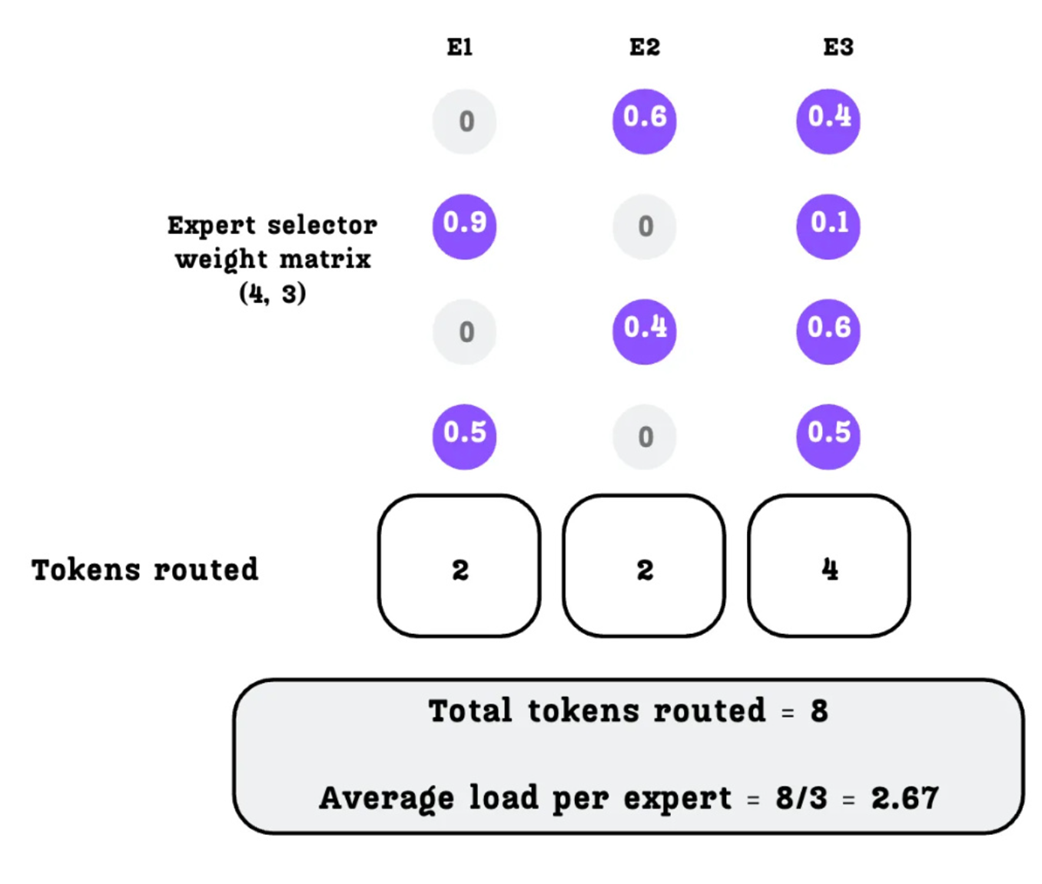
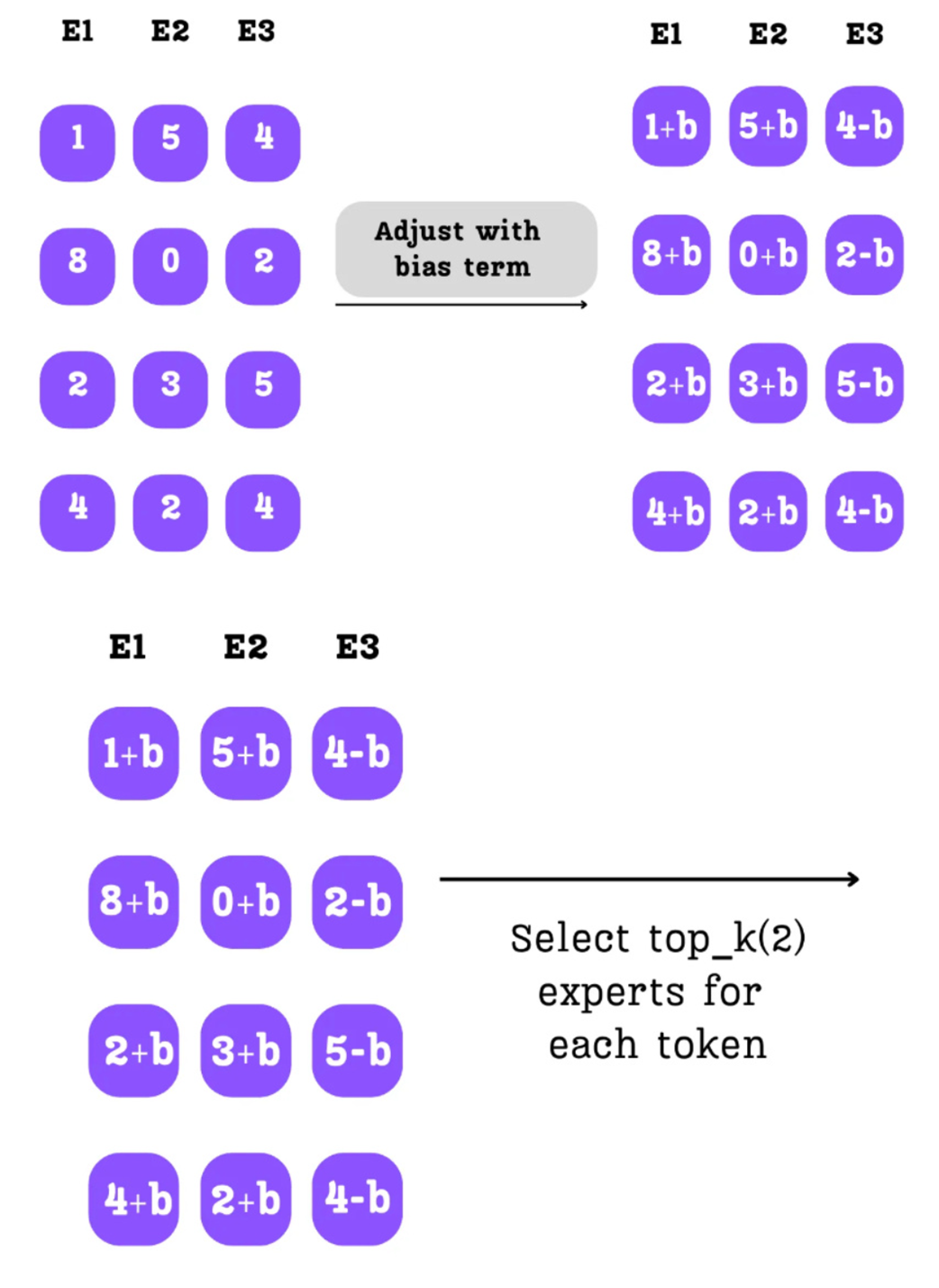
Calculating the number of tokens routed to each expert based on the top-k selection.
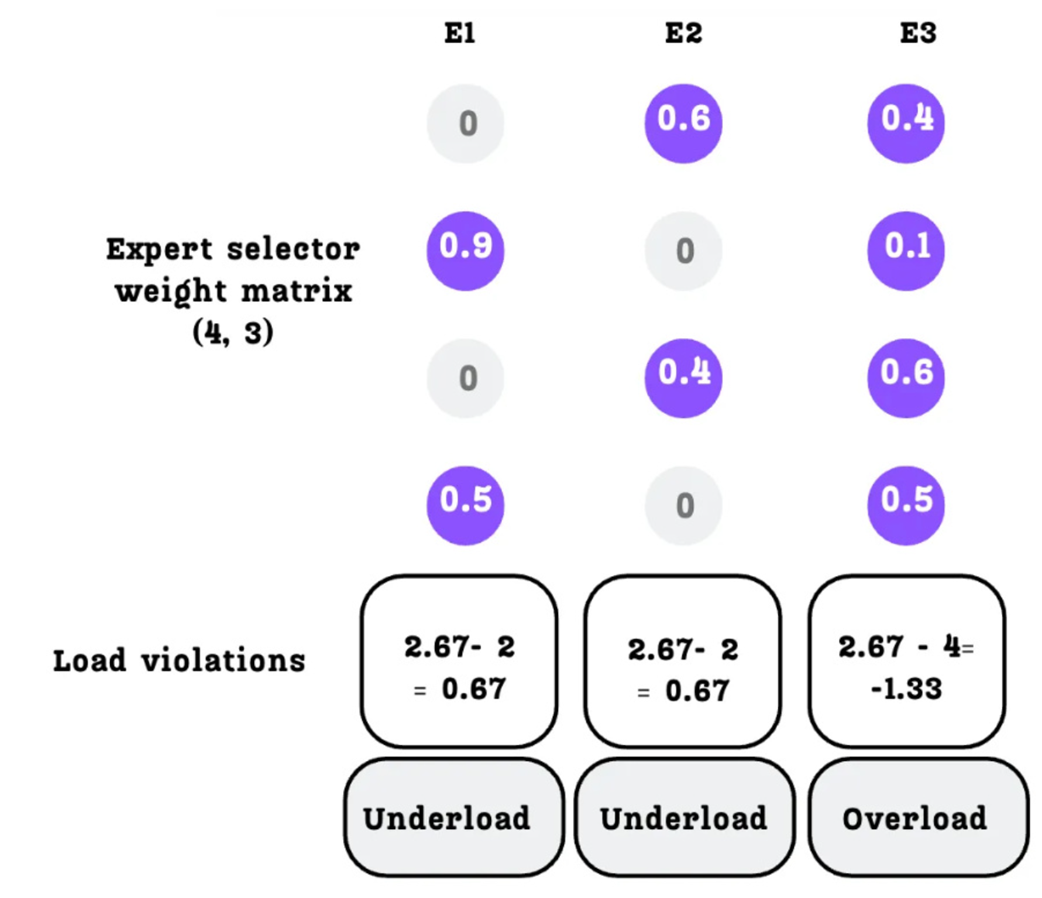
Calculating the load violation for each expert.
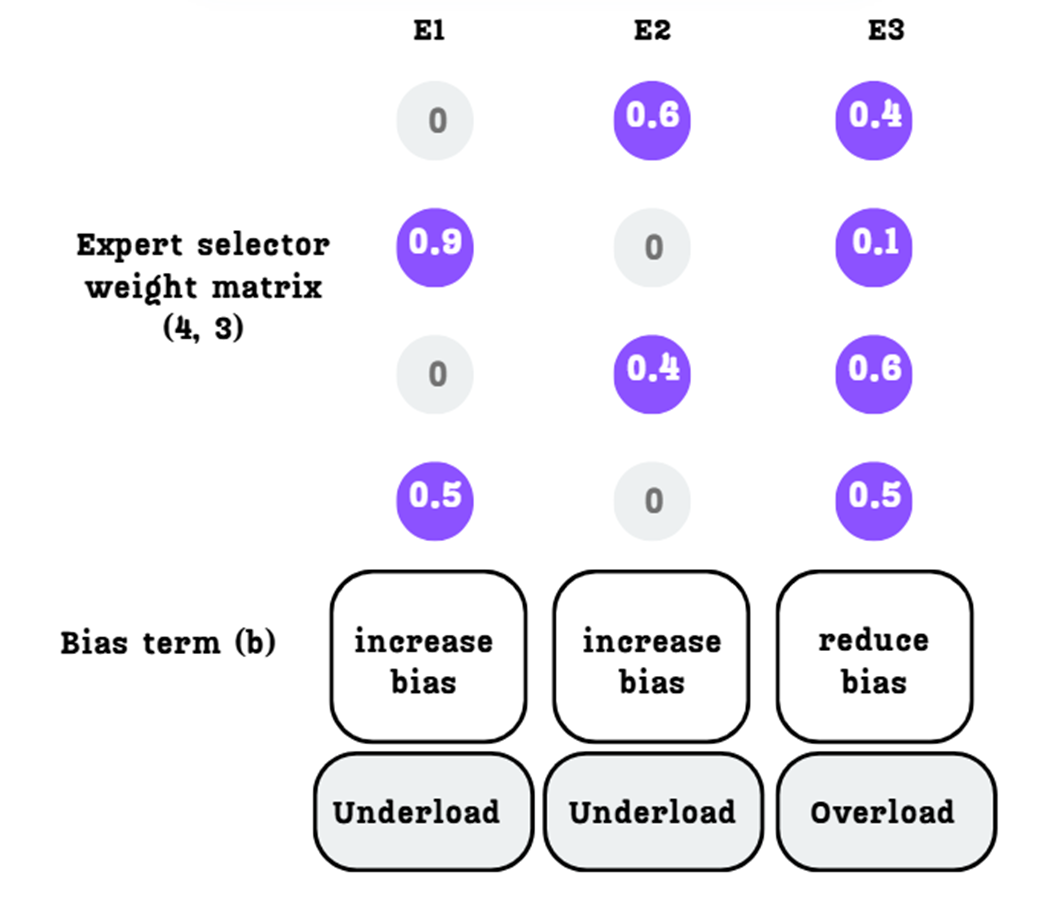
The direction of the bias update based on the expert's load status.
The bias term is added to the raw router logits before the top-k selection process.
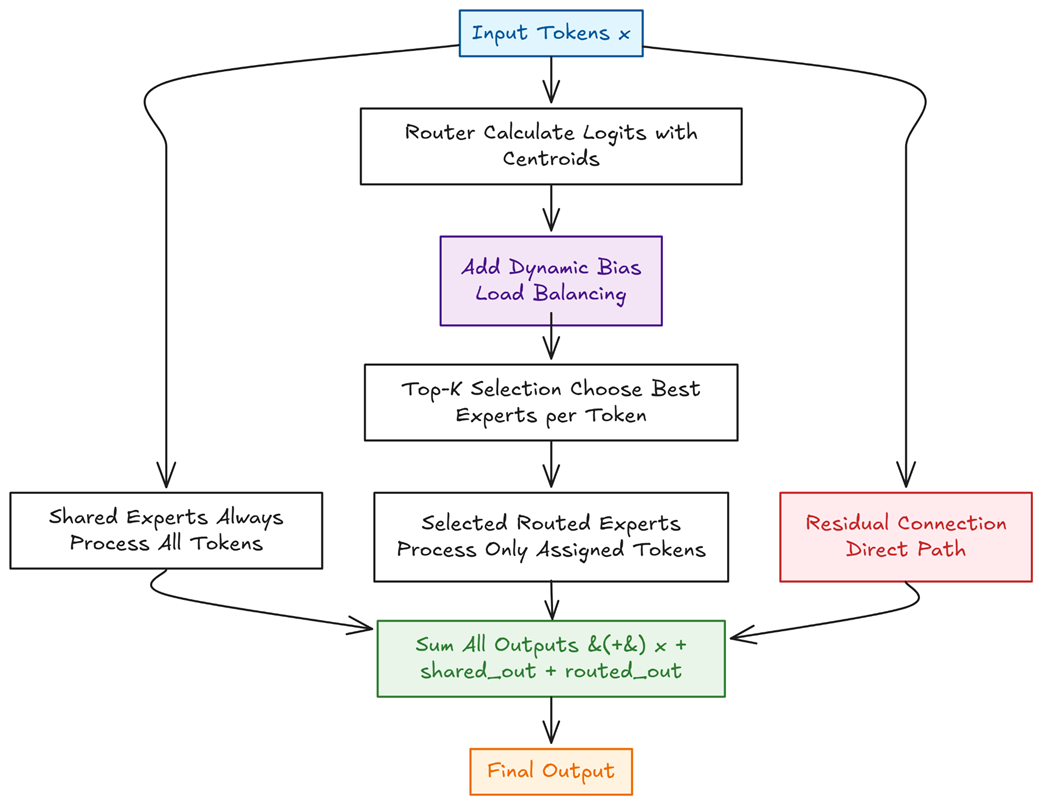
The complete forward pass of the DeepSeekMoE module, showing the three parallel data paths: the dense shared expert path, the sparse routed expert path with dynamic load balancing, and the residual connection.
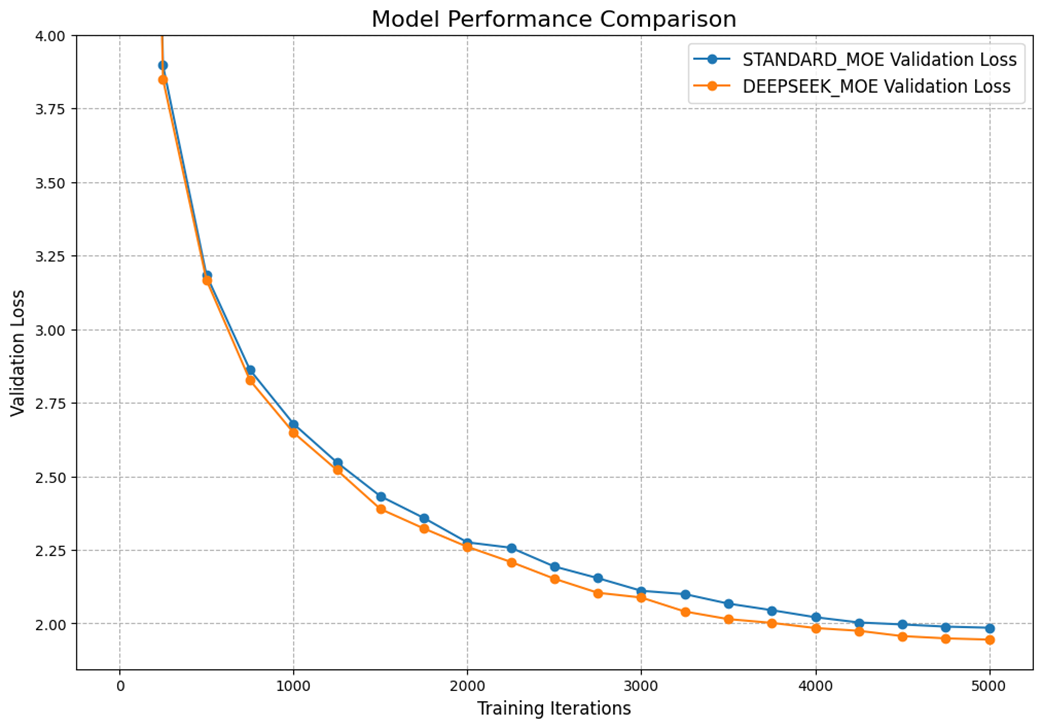
A comparison of the validation loss curves for the Standard MoE and DeepSeek-MoE models. Despite having a similar number of parameters, the DeepSeek-MoE architecture consistently achieves a lower loss, indicating superior learning. Both models were trained for 5,000 iterations.
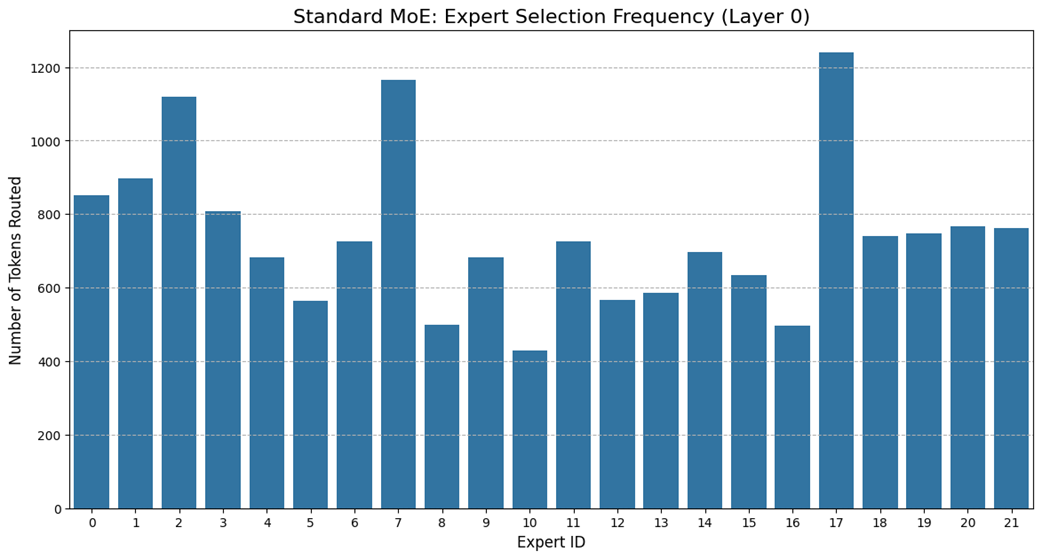
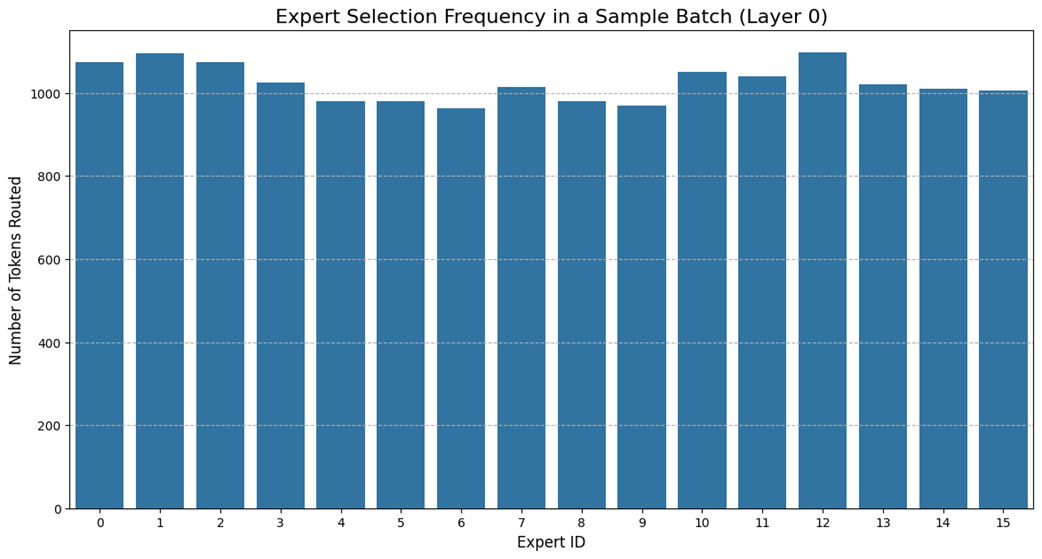
Expert selection frequency for the Standard-MoE model in a sample batch. The uneven distribution highlights the problem of imbalanced routing.
Expert selection frequency for the DeepSeek-MoE model in a sample batch. The distribution is remarkably uniform, demonstrating the effectiveness of the dynamic bias mechanism.
Summary
- Dense Feed-Forward Networks (FFNs) in standard Transformers are computationally expensive, as all of their parameters are activated for every single token, creating a bottleneck for both training and inference.
- Mixture of Experts (MoE) replaces the single, dense FFN with a committee of smaller, specialized "expert" networks.
- The efficiency of MoE comes from sparsity: for any given token, a routing mechanism activates only a small subset of the total experts (e.g., the top 2), leaving the rest dormant and their computations unperformed.
- During pre-training, experts learn to specialize in handling specific types of information (e.g., punctuation, verbs, or Python code), which is why activating only a few is effective.
- The routing mechanism is a small, learnable linear layer that generates scores for each expert. A top-k selection identifies the most relevant experts, and a softmax function converts their scores into weights for combining their outputs.
- Imbalanced routing, where some experts are over-utilized and others are ignored, leads to inefficient learning and performance degradation.
- Traditional MoE models use an Auxiliary Loss term to penalize imbalance, but this can interfere with the primary training objective of learning the language.
- DeepSeek's first innovation, Fine-Grained Expert Segmentation, uses a massive number of smaller experts to solve the problem of Knowledge Hybridity, allowing for deeper specialization.
- DeepSeek's second innovation, Shared Expert Isolation, uses a small set of dense "generalist" experts to learn common knowledge, solving the problem of Knowledge Redundancy and freeing up the routed "specialist" experts.
- DeepSeek's third innovation, Auxiliary-Loss-Free Load Balancing, dynamically adjusts router scores with a bias term, enforcing balance without interfering with the main training loss and resolving the core trade-off of traditional balancing methods.
 Build a DeepSeek Model (From Scratch) ebook for free
Build a DeepSeek Model (From Scratch) ebook for free