1 Understanding Large Language Models
Large language models are deep neural networks that have transformed natural language processing by moving beyond narrowly scoped, task-specific systems to broadly capable generators and analyzers of text. Trained on vast corpora, they capture rich context and subtle patterns, enabling applications from translation and summarization to question answering, coding assistance, and conversational agents. While they appear to “understand” language through coherent, context-aware output, this refers to statistical competence rather than human-like comprehension; their power stems from scale—both in model parameters and data—and from advances in deep learning.
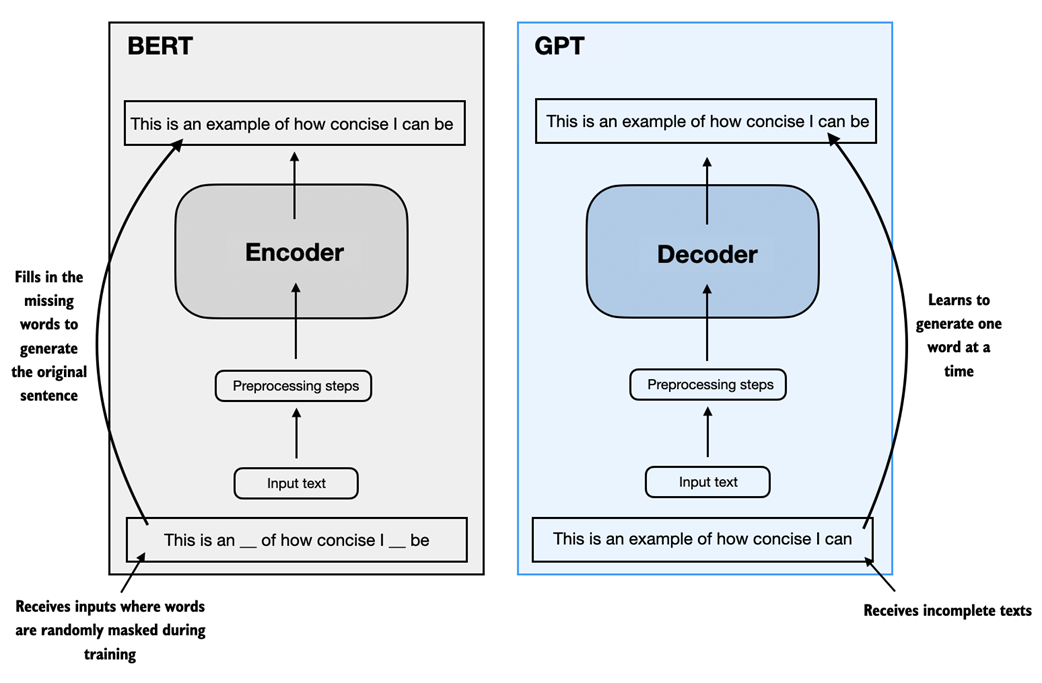
The core enabler is the transformer architecture and its self-attention mechanism, which selectively focuses on relevant parts of input sequences to model long-range dependencies. Two major families illustrate how transformers are used: encoder-based models like BERT, optimized for understanding tasks via masked word prediction, and decoder-only models like GPT, which are autoregressive generators trained with next-word prediction. Despite this simple pretraining objective, GPT-style models exhibit zero-shot and few-shot generalization and emergent abilities such as translation, benefiting from exposure to diverse, large-scale datasets. Pretraining produces a general foundation model that can be adapted efficiently through finetuning, making LLMs practical despite the high compute costs of training from scratch.
The chapter also motivates building LLMs to deepen understanding and to unlock benefits such as domain specialization, privacy, on-device deployment, and full control over updates. It outlines a hands-on path: prepare text data and implement attention; pretrain a compact GPT-like model for education; evaluate capabilities; and then finetune for instruction following or classification. While industrial-scale pretraining is expensive, open pretrained weights and careful engineering allow meaningful experimentation on consumer hardware, providing the skills to adapt and deploy models tailored to real-world needs.
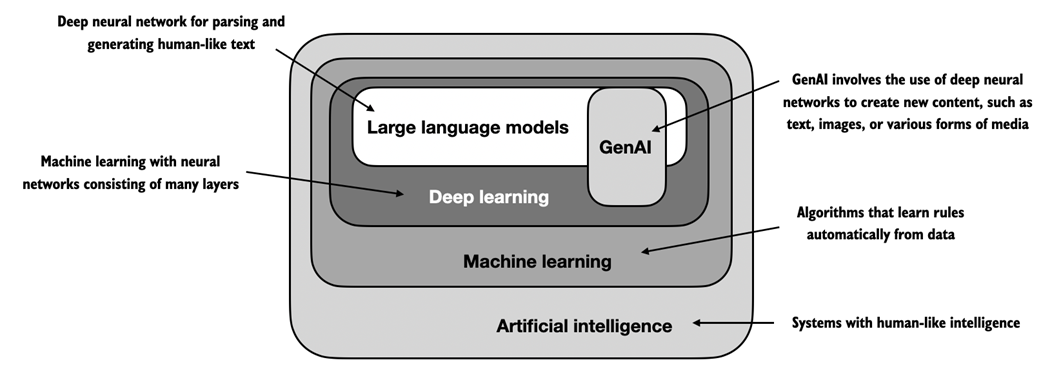
As this hierarchical depiction of the relationship between the different fields suggests, LLMs represent a specific application of deep learning techniques, leveraging their ability to process and generate human-like text. Deep learning is a specialized branch of machine learning that focuses on using multi-layer neural networks. And machine learning and deep learning are fields aimed at implementing algorithms that enable computers to learn from data and perform tasks that typically require human intelligence.
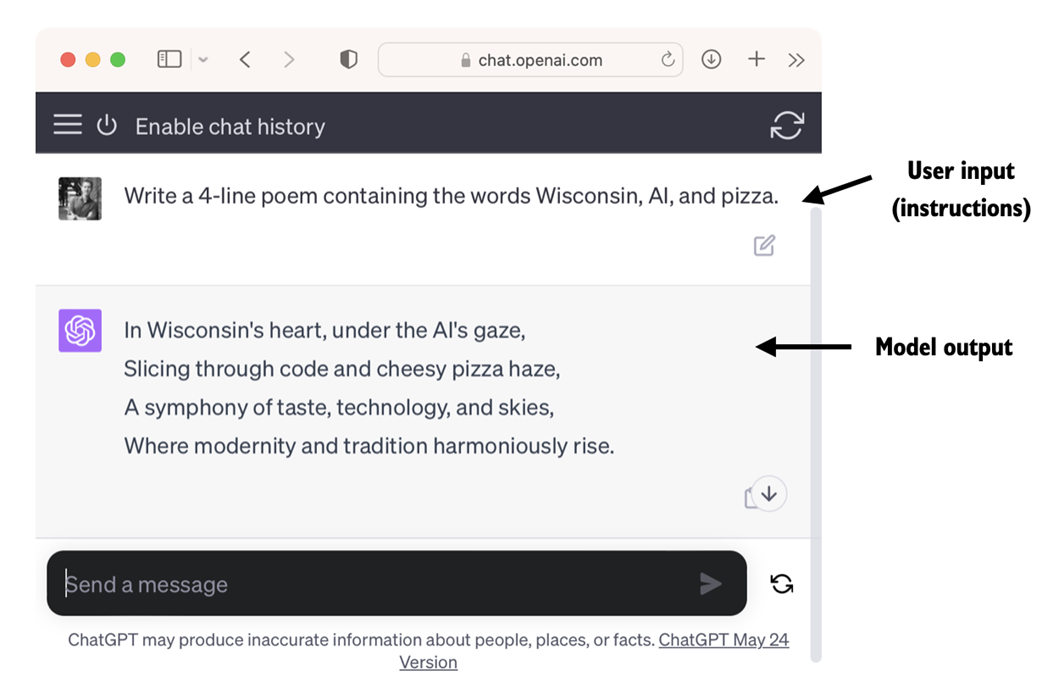
LLM interfaces enable natural language communication between users and AI systems. This screenshot shows ChatGPT writing a poem according to a user's specifications.
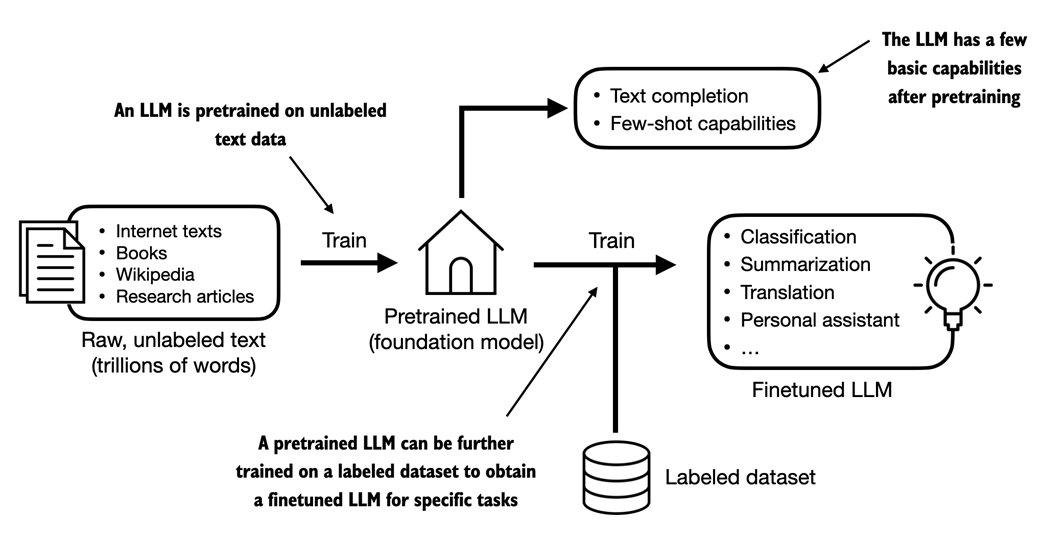
Pretraining an LLM involves next-word prediction on large text datasets. A pretrained LLM can then be finetuned using a smaller labeled dataset.
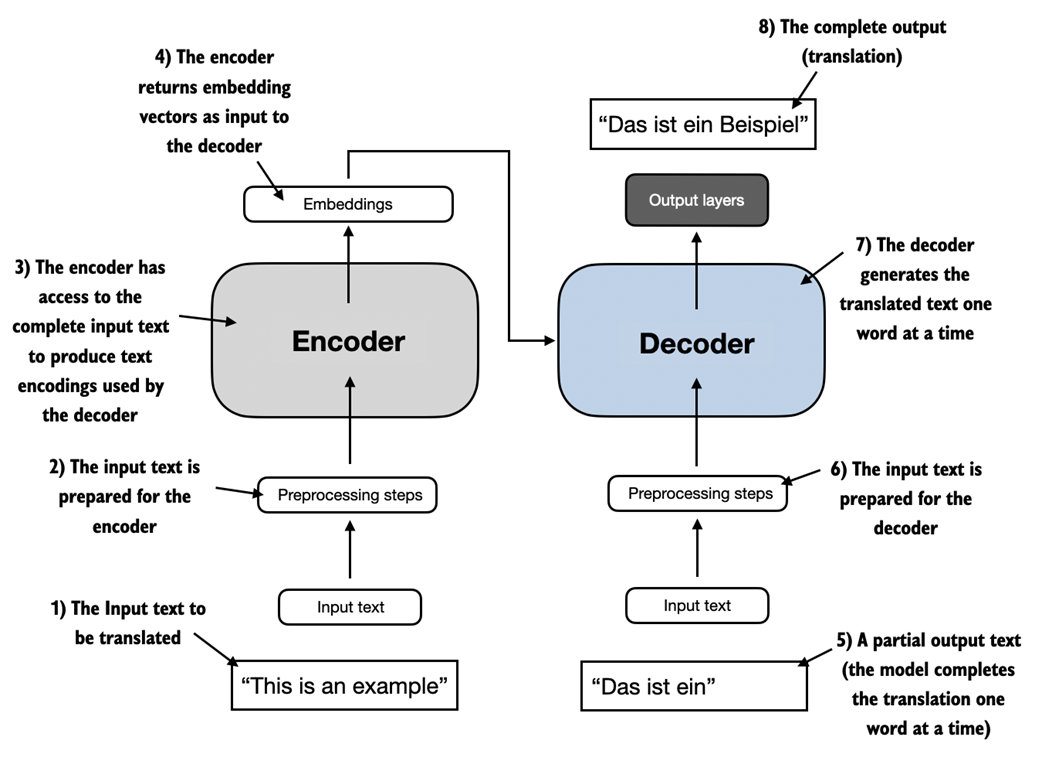
A simplified depiction of the original transformer architecture, which is a deep learning model for language translation. The transformer consists of two parts, an encoder that processes the input text and produces an embedding representation (a numerical representation that captures many different factors in different dimensions) of the text that the decoder can use to generate the translated text one word at a time. Note that this figure shows the final stage of the translation process where the decoder has to generate only the final word ("Beispiel"), given the original input text ("This is an example") and a partially translated sentence ("Das ist ein"), to complete the translation.
A visual representation of the transformer's encoder and decoder submodules. On the left, the encoder segment exemplifies BERT-like LLMs, which focus on masked word prediction and are primarily used for tasks like text classification. On the right, the decoder segment showcases GPT-like LLMs, designed for generative tasks and producing coherent text sequences.
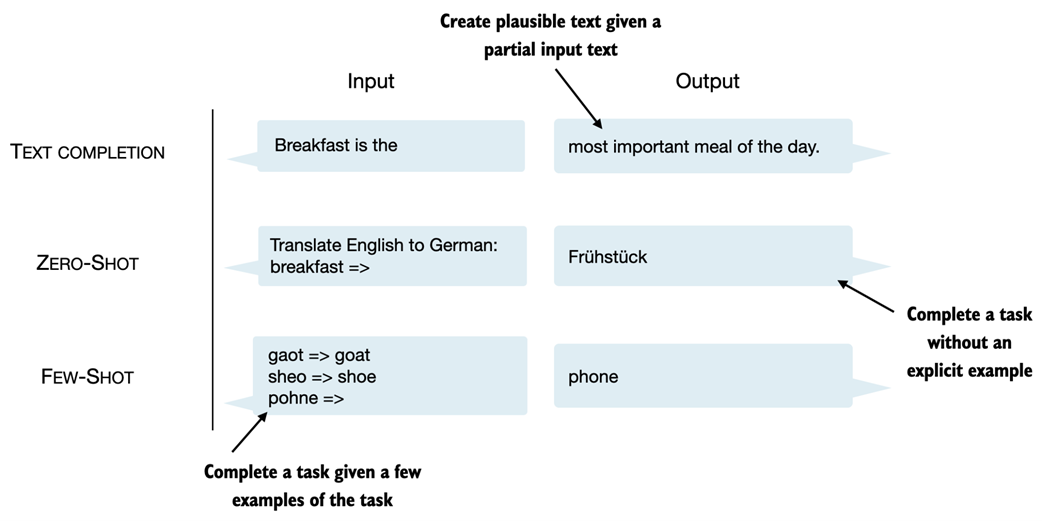
In addition to text completion, GPT-like LLMs can solve various tasks based on their inputs without needing retraining, finetuning, or task-specific model architecture changes. Sometimes, it is helpful to provide examples of the target within the input, which is known as a few-shot setting. However, GPT-like LLMs are also capable of carrying out tasks without a specific example, which is called zero-shot setting.
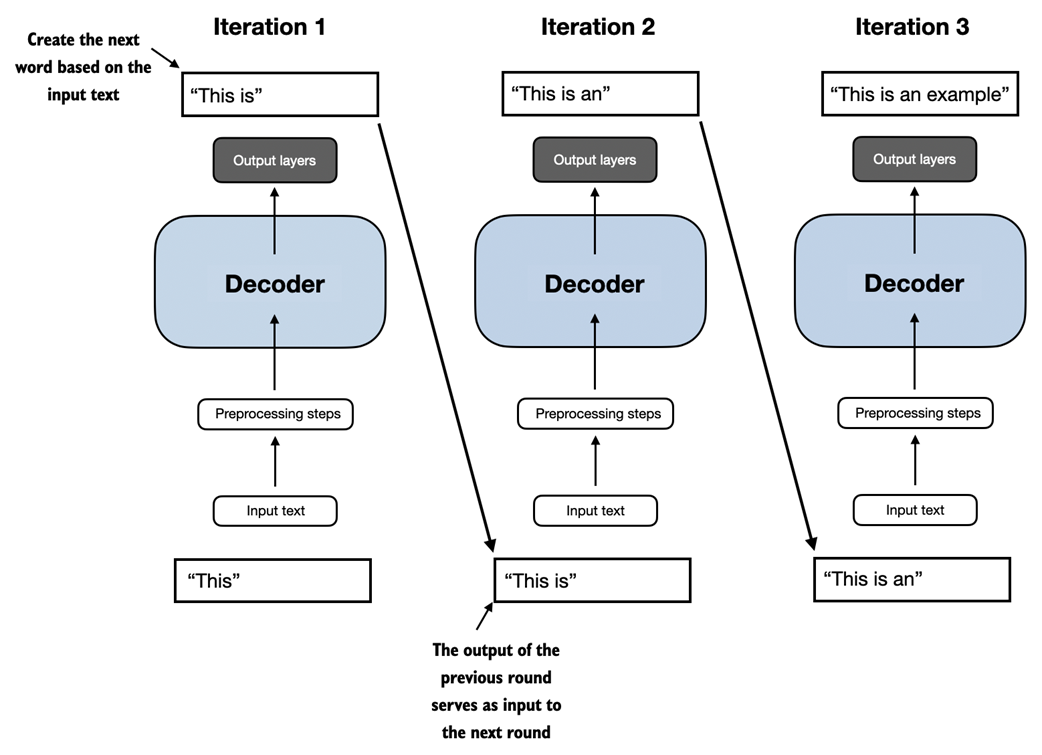
In the next-word pretraining task for GPT models, the system learns to predict the upcoming word in a sentence by looking at the words that have come before it. This approach helps the model understand how words and phrases typically fit together in language, forming a foundation that can be applied to various other tasks.

The GPT architecture employs only the decoder portion of the original transformer. It is designed for unidirectional, left-to-right processing, making it well-suited for text generation and next-word prediction tasks to generate text in iterative fashion one word at a time.
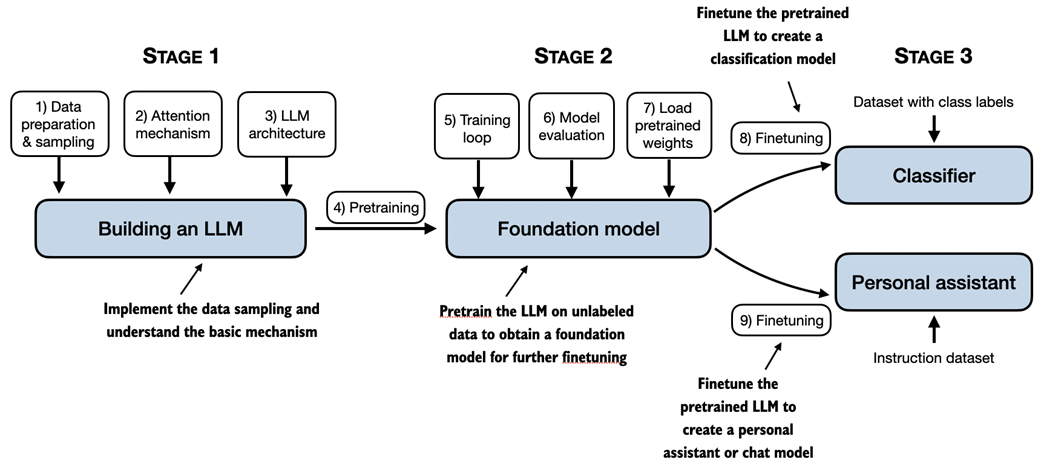
The stages of building LLMs covered in this book include implementing the LLM architecture and data preparation process, pretraining an LLM to create a foundation model, and finetuning the foundation model to become a personal assistant or text classifier.
Summary
- LLMs have transformed the field of natural language processing, which previously mostly relied on explicit rule-based systems and simpler statistical methods. The advent of LLMs introduced new deep learning-driven approaches that led to advancements in understanding, generating, and translating human language.
- Modern LLMs are trained in two main steps.
- First, they are pretrained on a large corpus of unlabeled text by using the prediction of the next word in a sentence as a "label."
- Then, they are finetuned on a smaller, labeled target dataset to follow instructions or perform classification tasks.
- LLMs are based on the transformer architecture. The key idea of the transformer architecture is an attention mechanism that gives the LLM selective access to the whole input sequence when generating the output one word at a time.
- The original transformer architecture consists of an encoder for parsing text and a decoder for generating text.
- LLMs for generating text and following instructions, such as GPT-3 and ChatGPT, only implement decoder modules, simplifying the architecture.
- Large datasets consisting of billions of words are essential for pretraining LLMs. In this book, we will implement and train LLMs on small datasets for educational purposes but also see how we can load openly available model weights.
- While the general pretraining task for GPT-like models is to predict the next word in a sentence, these LLMs exhibit "emergent" properties such as capabilities to classify, translate, or summarize texts.
- Once an LLM is pretrained, the resulting foundation model can be finetuned more efficiently for various downstream tasks.
- LLMs finetuned on custom datasets can outperform general LLMs on specific tasks.
[1] Readers with a background in machine learning may note that labeling information is typically required for traditional machine learning models and deep neural networks trained via the conventional supervised learning paradigm. However, this is not the case for the pretraining stage of LLMs. In this phase, LLMs leverage self-supervised learning, where the model generates its own labels from the input data. This concept is covered later in this chapter
[2] GPT-3, The $4,600,000 Language Model, https://www.reddit.com/r/MachineLearning/comments/h0jwoz/d_gpt3_the_4600000_language_model/
 Build a Large Language Model (From Scratch) ebook for free
Build a Large Language Model (From Scratch) ebook for free