1 Getting started with MLOps and ML engineering
This chapter introduces the gap between building models and operating them reliably in production, positioning MLOps as the discipline that closes it. It sets expectations for a hands-on journey that turns readers into confident ML engineers by focusing on the complete life cycle, practical patterns, and the skills companies value. Rather than theory-heavy content, the chapter frames the book as an incremental, project-driven guide that emphasizes reproducibility, automation, and real-world decision-making across diverse ML use cases.
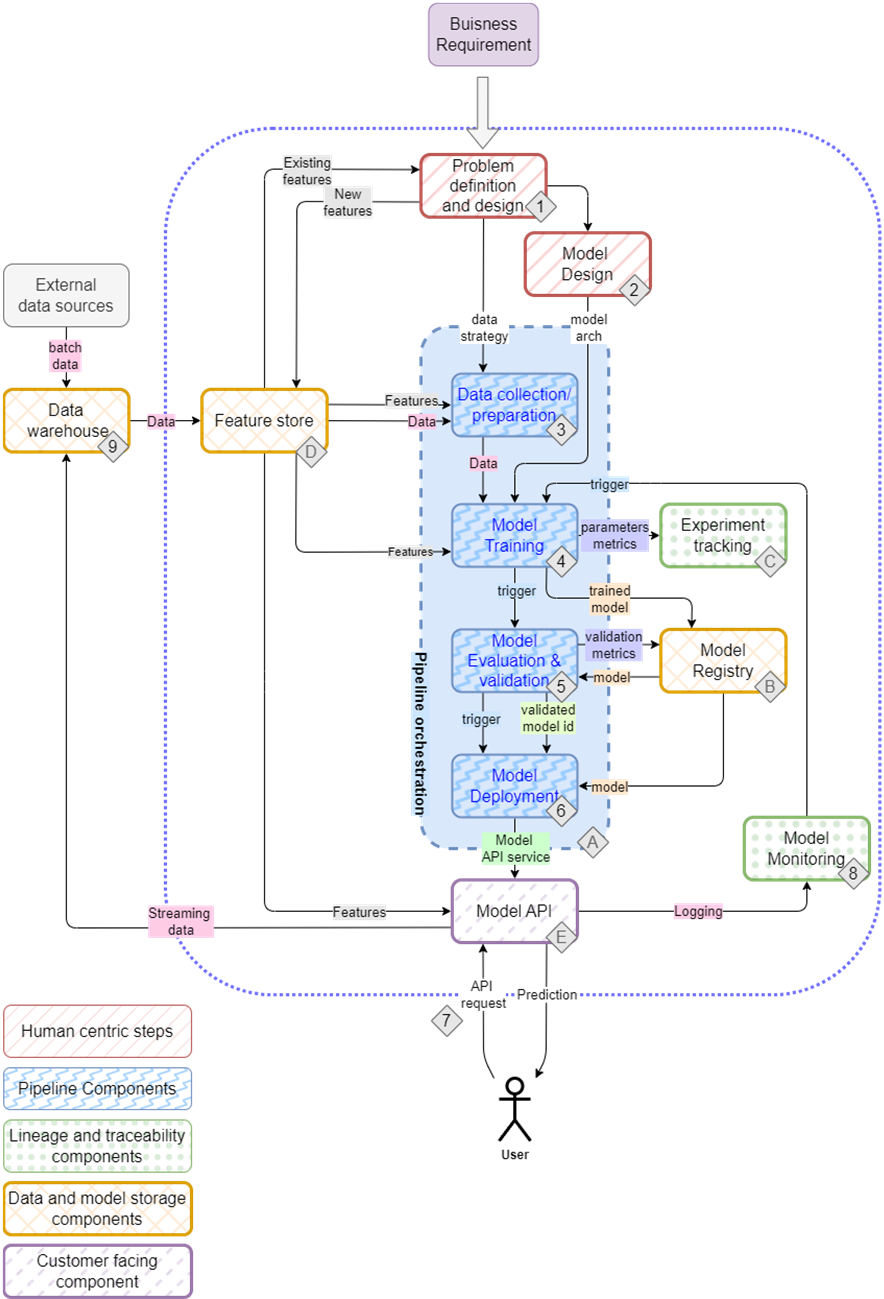
The chapter first maps the ML life cycle as an iterative process: problem formulation, data collection and preparation (often with labor-intensive labeling), data versioning for reproducibility, model training, evaluation, and stakeholder-driven validation. It then contrasts this experimentation loop with the dev/staging/production phase, where pipelines are fully automated and triggered via CI, culminating in deployable services (commonly REST APIs). Production concerns include containerization, scalability, performance testing, versioned releases with rollback strategies, and monitoring that spans system metrics, data/model drift, and business KPIs. Retraining is treated as a first-class, automatable step, scheduled or triggered by performance thresholds.
To execute all this, the chapter outlines the core skill set (solid software engineering, practical ML fluency, data engineering, and a bias toward automation) and introduces an incremental path to building an ML platform. Kubeflow and its Pipelines provide orchestration; additional components such as feature stores and model registries prevent training-serving skew and enable promotion flows; CI/CD, container registries, and Kubernetes operationalize deployment. Tool choices are pragmatic and context-driven, and the “build vs buy” discussion encourages assembling a platform at least once to understand constraints and integrations. The chapter previews three projects—an OCR system, a movie recommender, and a RAG-powered documentation assistant—showing how the same MLOps foundations extend to LLMOps with vector databases, guardrails, and cost-aware operations.
The experimentation phase of the ML life cycle

The dev/staging/production phase of the ML life cycle
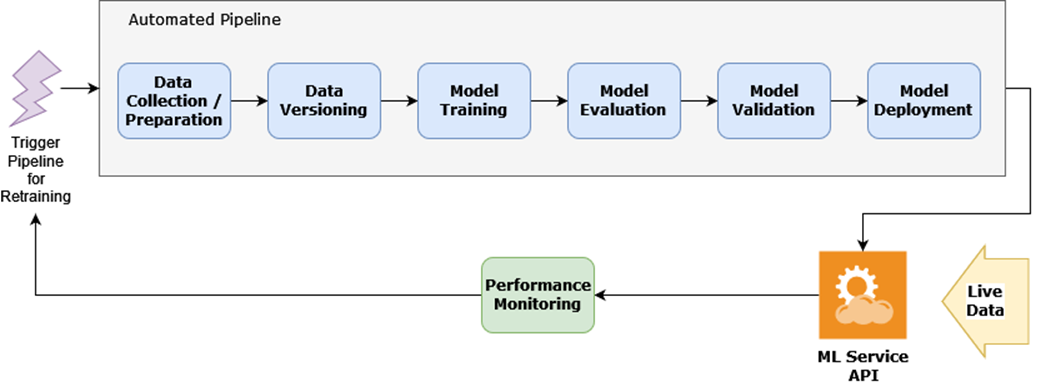
MLOps is a mix of different skill sets
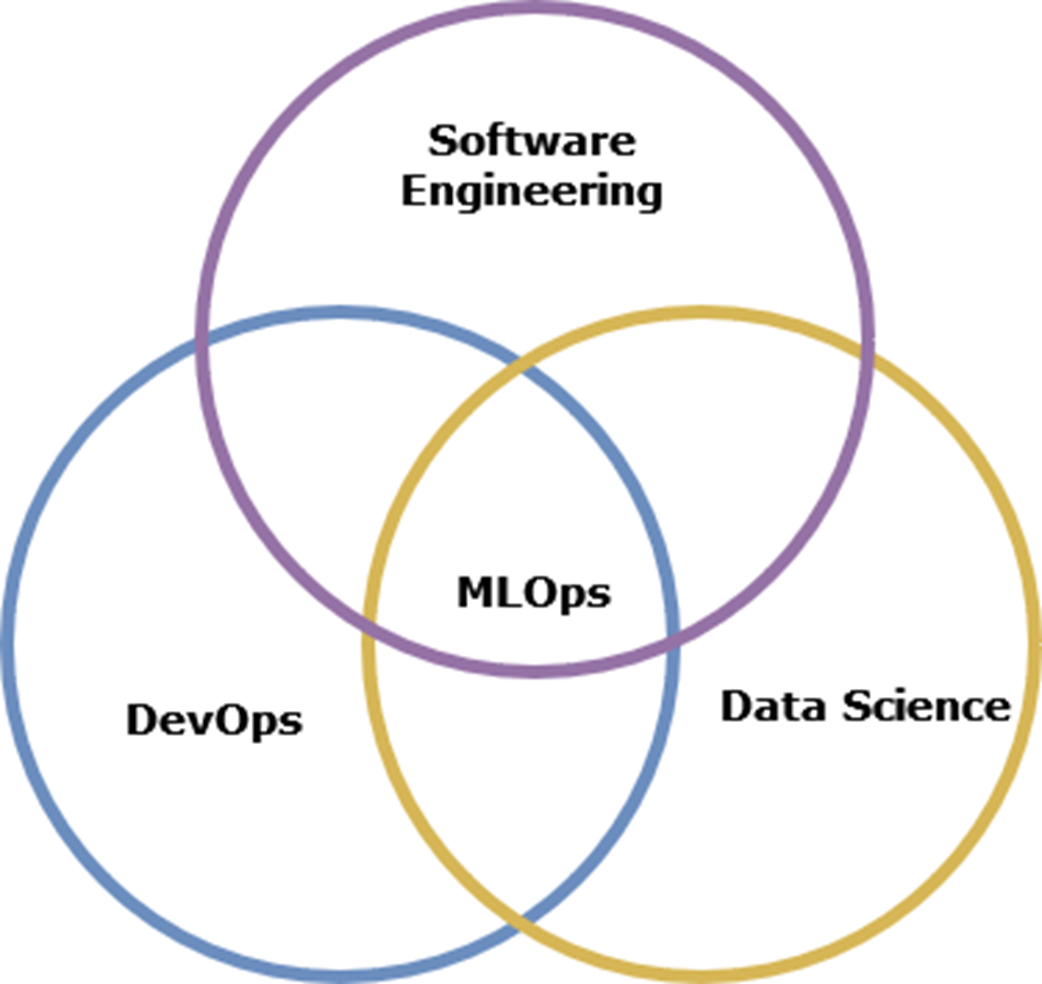
The mental map of an ML setup, detailing the project flow from planning to deployment and the tools typically involved in the process
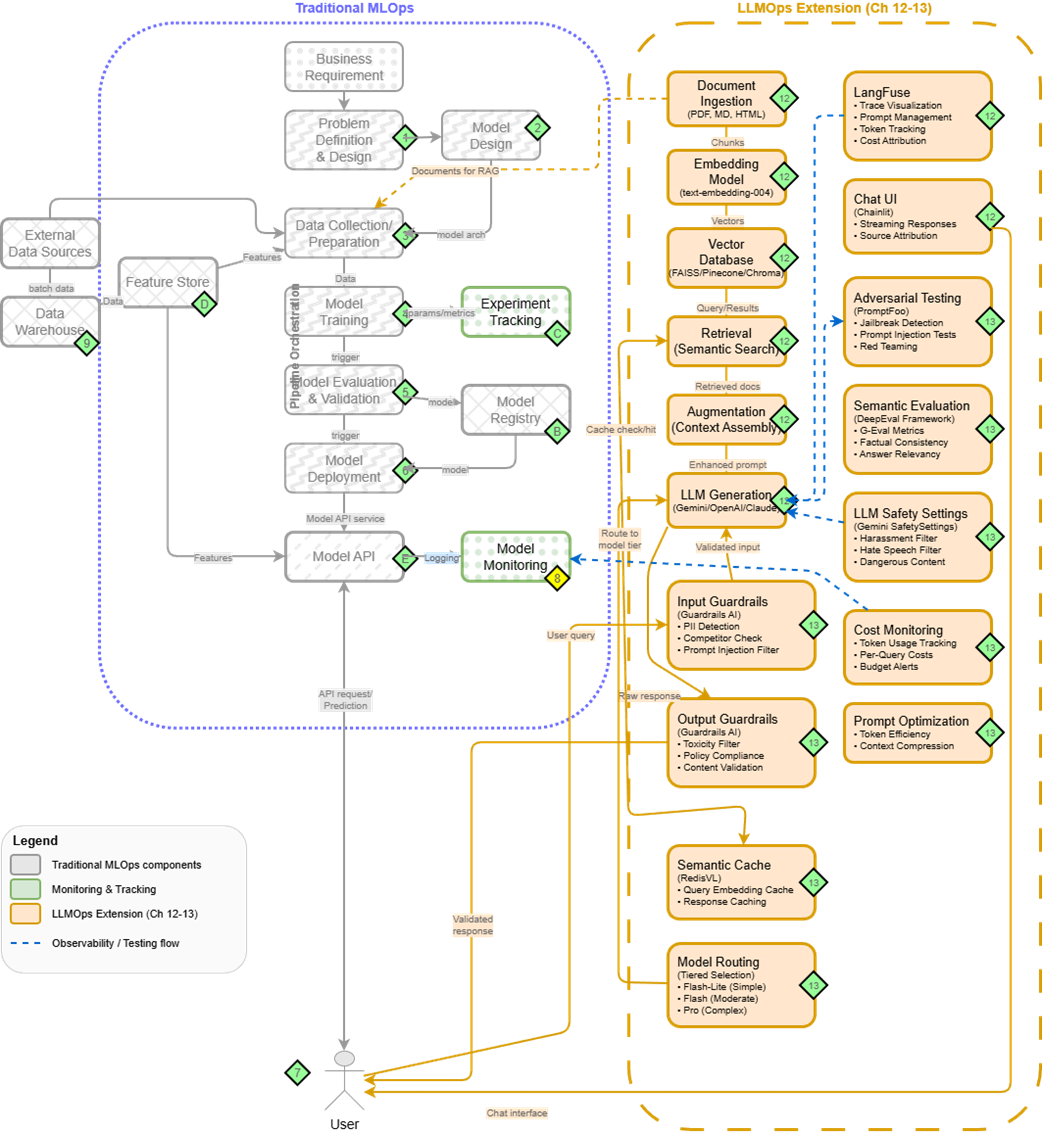
Traditional MLOps (right) extended with LLMOps components (left) for production LLM systems. Chapters 12-13 explore these extensions in detail.
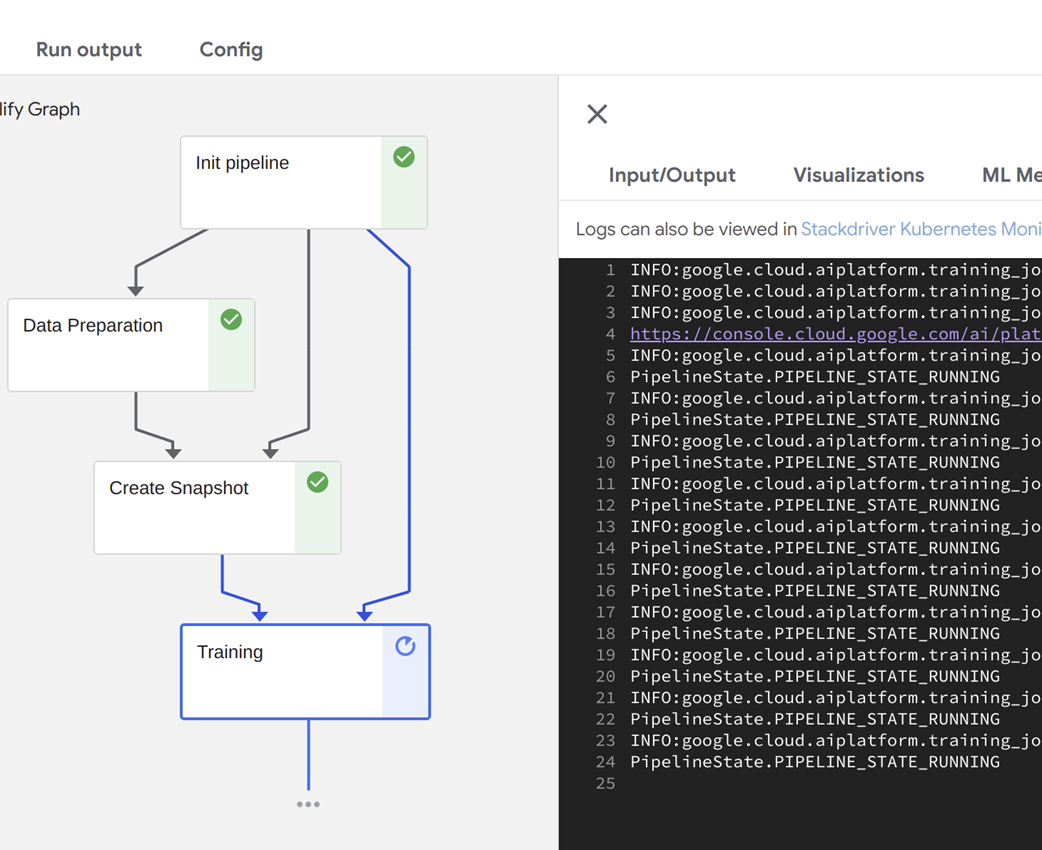
An automated pipeline being executed in Kubeflow.
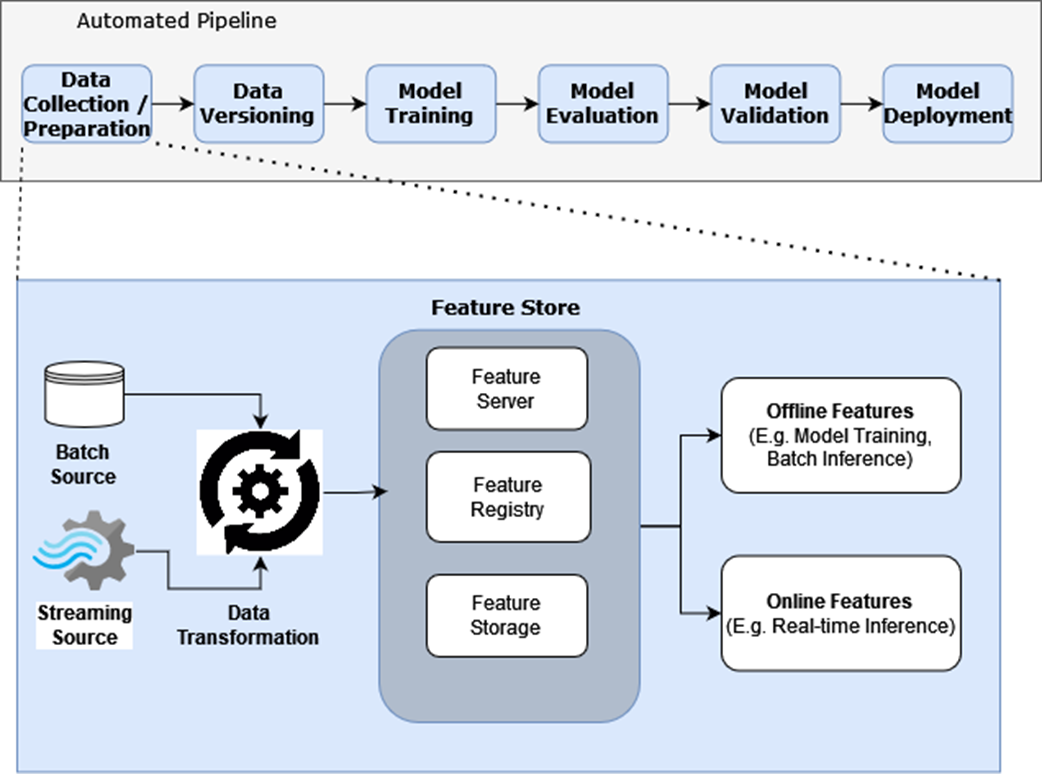
Feature Stores take in transformed data (features) as input, and have facilities to store, catalog, and serve features.
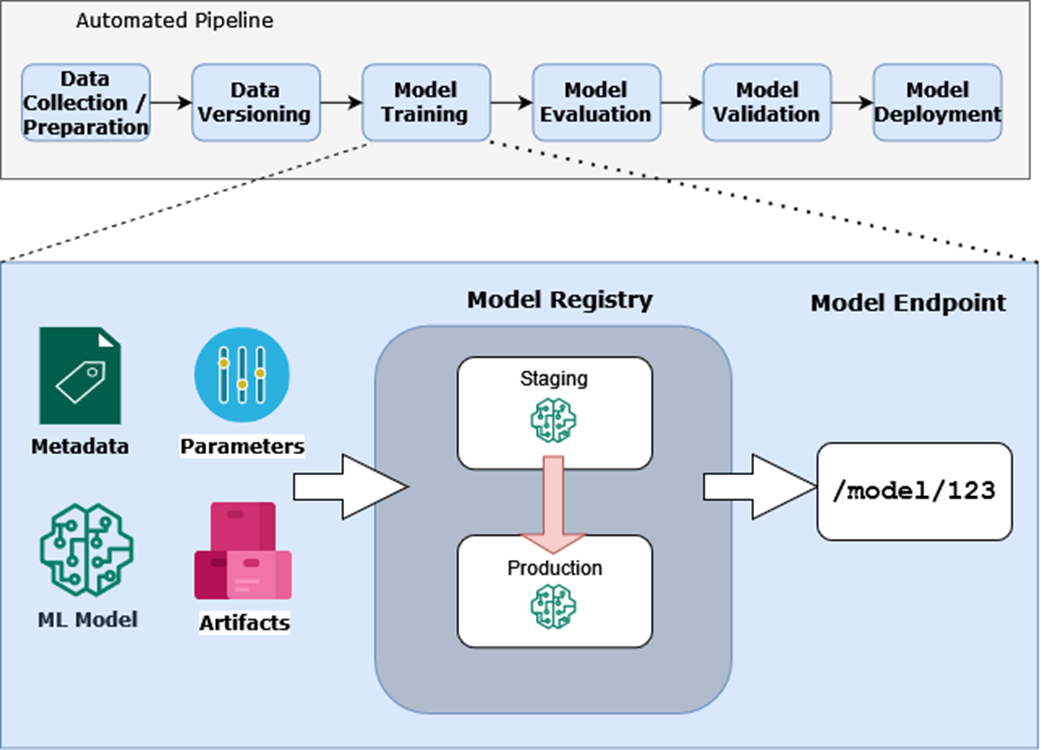
The model registry captures metadata, parameters, artifacts, and the ML model and in turn exposes a model endpoint.
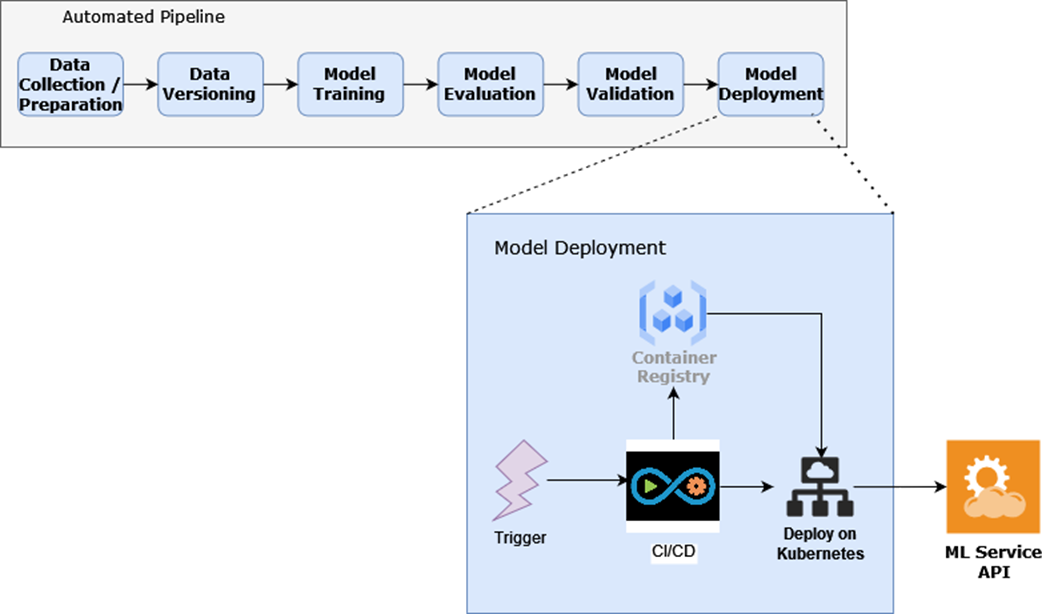
Model deployment consists of the container registry, CI/CD, and automation working in concert to deploy ML services.
Summary
- The Machine Learning (ML) life cycle provides a framework for confidently taking ML projects from idea to production. While iterative in nature, understanding each phase helps you navigate the complexities of ML development.
- Building reliable ML systems requires a combination of skills spanning software engineering, MLOps, and data science. Rather than trying to master everything at once, focus on understanding how these skills work together to create robust ML systems.
- A well-designed ML Platform forms the foundation for confidently developing and deploying ML services. We'll use tools like Kubeflow Pipelines for automation, MLFlow for model management, and Feast for feature management - learning how to integrate them effectively for production use.
- We'll apply these concepts by building two different types of ML systems: an OCR system and a Movie recommender. Through these projects, you'll gain hands-on experience with both image and tabular data, building confidence in handling diverse ML challenges.
- Traditional MLOps principles extend naturally to Large Language Models through LLMOps - adding components for document processing, retrieval systems, and specialized monitoring. Understanding this evolution prepares you for the modern ML landscape.
- The first step is to identify the problem the ML model is going to solve, followed by collecting and preparing the data to train and evaluate the model. Data versioning enables reproducibility, and model training is automated using a pipeline.
- The ML life cycle serves as our guide throughout the book, helping us understand not just how to build models, but how to create reliable, production-ready ML systems that deliver real business value.
FAQ
Why does this book emphasize MLOps and production ML systems?
Most ML projects don’t fail because the model is “bad” but because deploying, operating, and evolving ML in production is hard. This book focuses on the practices that make ML reliable at scale: automation, orchestration, monitoring, reproducibility, and sound engineering. You’ll learn to carry a model from idea to production and keep it healthy over time.
What is the ML life cycle at a high level?
The life cycle spans iterative experimentation (problem formulation, data prep, versioning, training, evaluation, validation) and a production phase (fully automated pipelines, deployment, monitoring, and retraining). It’s inherently non-linear: findings in later steps often push you back to earlier ones, especially around data.
How does the Experimentation phase differ from Dev/Staging/Production?
- Experimentation: fast iteration, partial automation, exploring data, models, and metrics.
- Dev/Staging/Production: fully automated pipelines triggered by CI or events, versioned releases, deployment as services (often REST), and ongoing monitoring.
- The focus shifts from discovery to reliability, scale, security, and governance.
What are the core steps in the Experimentation phase?
- Problem formulation: confirm ML is the right tool and define success criteria.
- Data collection and preparation: source, annotate/label, and split into train/val/test.
- Data versioning: track datasets and changes for reproducibility.
- Model training: automate runs, capture parameters and artifacts.
- Model evaluation: measure with appropriate metrics on unseen data.
- Model validation: business/stakeholder checks before promotion.
Why is data versioning essential and why is it hard?
In ML, data changes alter behavior just like code changes do. Versioning data ensures experiments are reproducible and models can be audited. It’s challenging because data comes in varied formats and sizes, and the ecosystem lacks a “Git-equivalent” standard, so teams adopt fit-for-purpose tools and processes.
What’s the difference between model evaluation and model validation?
- Evaluation: technical assessment on held-out data using metrics like precision, recall, AUC.
- Validation: confirms the model’s behavior aligns with business expectations and constraints; often performed by stakeholders beyond the model builders.
What does a robust model deployment process look like?
- Expose inference via an API (commonly REST).
- Containerize (e.g., Docker) and deploy on orchestrators (e.g., Kubernetes).
- Automate via CI/CD: build, push, and apply manifests.
- Load test, enable autoscaling, and version releases with rollback strategies.
What should be monitored in production ML systems?
- System/performance: latency, RPS, error rates, resource usage.
- Data/model health: data drift, concept drift, model quality regression.
- Business KPIs: domain-specific metrics (e.g., conversion, fraud catch-rate).
- Alerts/triggers: thresholds that can kick off retraining or rollback.
When should models be retrained, and how should it be automated?
Retrain on a schedule (e.g., monthly) or based on triggers (e.g., drift or KPI drops). Use automated pipelines to re-ingest data, train, evaluate, validate, and deploy. Full automation shortens feedback loops and keeps quality stable as data and behavior shift.
What skills and platform components does this book cover?
- Skills: solid software engineering, practical ML with common frameworks, data engineering basics, and heavy emphasis on automation/reproducibility.
- Platform: Kubeflow/Kubeflow Pipelines for orchestration, CI/CD and container registries for deployment, feature stores (to share features and prevent training-serving skew), model registries (to track runs and promote versions), and Kubernetes for scaling.
- Build vs Buy: even if you use managed platforms (e.g., SageMaker, Vertex AI), assembling a platform from scratch once builds understanding and flexibility.
- LLMOps: the same foundation extends to RAG/LLM systems with vector DBs, guardrails, and specialized monitoring later in the book.
 Build a Machine Learning Platform (From Scratch) ebook for free
Build a Machine Learning Platform (From Scratch) ebook for free