Overview
1 Deploying Large Language Models Reliably in the Real World
Large language models have progressed rapidly from the Transformer breakthrough to systems that read, write, and reason with striking fluency, but turning demos into dependable products remains hard. This chapter sets the stage: despite impressive capabilities and industry momentum, many pilots fail to deliver ROI because reliability, efficiency, and responsibility are treated as afterthoughts. The book positions itself as a practical guide to close that gap—focusing on engineering techniques that make LLMs accurate, trustworthy, and durable in production.
It highlights the real-world impact across domains—legal research acceleration (e.g., contract analysis), customer service automation at scale, faster software development with AI coding assistants, and enterprise “agentic” systems woven into core workflows—while surfacing why deployments break in practice. LLMs are probabilistic, can hallucinate, carry hidden bias, and increasingly take actions with real-world consequences. The chapter reframes success around rigorous evaluation and operations, not just capability demos: reliability must be measured, monitored, and continuously improved.
The chapter then outlines a toolkit for dependable systems: retrieval-augmented generation, structured reasoning prompts, semantic search, confidence and uncertainty signaling, and source attribution to curb hallucinations; proactive bias programs with adversarial tests, fairness metrics, dataset curation, and CI-style audits; and efficiency strategies such as distillation, quantization, caching, hybrid routing, and comprehensive quality monitoring. For agentic AI, it stresses least-privilege permissions and layered safety controls. With regulation, public trust, and ROI on the line, the book offers hands-on projects and end-to-end workflows—using accessible tools like Python and API-based models—to help teams build systems that stay reliable from day one to day 1,000.
Summary
- LLMs have immense potential to transform industries. Their applications span content creation, customer service, healthcare, and more.
- Core challenges like hallucinations, bias, efficiency and performance must be addressed to successfully use LLMs in production.
- Agentic AI systems that take real-world actions introduce new categories of risk requiring sophisticated reliability engineering.
- Mitigating bias is crucial to prevent perpetuating harmful assumptions and ensure fair, equitable treatment.
- Improving efficiency is vital to making large models economically and environmentally viable at scale.
- Curbing hallucination risks is key to keep outputs honest and grounded in facts.
- Performance optimization ensures LLMs meet speed responsiveness demands, and quality of real-world applications.
- Multi-agent systems require coordination protocols, error handling, and monitoring to prevent cascading failures.
- This book covers promising solutions to these challenges that will enable safely harnessing LLMs to create groundbreaking innovations across healthcare, science, education, entertainment, and more while building vital public trust.
FAQ
Why do so many LLM pilots fail to deliver ROI?
Most pilots stumble when moving from demo to production. An MIT study found 95% of generative AI pilots fail to deliver ROI due to hallucinations, flaky outputs, brittle toolchains, and weak evaluations. Without reliability engineering, systems that look magical in the lab become unreliable in the real world.How do LLMs work, and what changed with Transformers?
LLMs predict the most likely next token based on patterns learned from massive text corpora. The 2017 Transformer architecture enabled models to capture long-range context, and scaling to billions+ parameters unlocked strong abilities in generation, comprehension, reasoning, and translation. Crucially, they’re probabilistic—so identical inputs can yield different outputs.Where are LLMs driving impact today—and what risks come with it?
- Law: JPMorgan’s COIN automates ~360k hours of contract review; risk: fabricated citations. - Customer service: Klarna’s assistant replaces work of ~700 agents and saves ~$40M/year; Intercom’s bot resolves 67% of inquiries; risk: incorrect policy info. - Development: GitHub Copilot speeds coding by ~55%; risk: buggy/insecure suggestions. - Enterprise AI: Salesforce Einstein runs 1B+ predictions/day, boosting revenue 25–35%; risk: biased outputs in high-stakes contexts.What is “hallucination,” and how can we minimize it?
Hallucination is when a model produces confident, plausible, but false content—like fabricated legal cases that look real. Mitigations include retrieval-augmented generation (RAG) and semantic search for grounding, chain-of-thought prompting for stepwise reasoning, confidence/uncertainty signaling, and source attribution. Treat it like a security threat: assume it will happen and deploy layered defenses.How should teams detect and mitigate bias in LLM systems?
Bias often hides in correlations learned from historical data, yielding unequal outcomes across demographics. Build bias checks into the pipeline: adversarial tests, clear fairness metrics, routine audits, and curated, representative datasets. Automate bias testing in CI/CD and create feedback loops to rapidly catch and correct issues.How can we improve LLM efficiency and cost without losing quality?
Use model distillation (smaller “student” models that retain ~90% performance at ~10% compute), quantization (shrink models by up to ~75% with minimal quality loss), intelligent caching/precompute, and hybrid routing (small models for routine tasks, large models for hard cases). Real-world results show it’s feasible to achieve performance at sustainable cost.What should production monitoring include beyond standard metrics?
Track technical metrics (latency, error rates) and quality metrics (hallucination rate, bias incidents, user satisfaction). Comprehensive monitoring surfaces issues early, preserves trust, and prevents small degradations from becoming production outages or PR/legal risks.What is agentic AI, and how do we keep it reliable?
Agentic AI uses tools and takes real actions (send emails, update databases, make purchases). Mistakes become costly—e.g., booking the wrong city or deleting critical records. Enforce least-privilege permissions, tightly scope tool/data access, add guardrails and escalation/human review for sensitive actions, and test workflows rigorously—especially in multi-agent setups.Why do these reliability challenges matter right now?
LLMs are entering high-stakes domains (healthcare, finance, law), where errors bring regulatory, legal, and reputational consequences. Regulations (e.g., EU AI Act, pending U.S. rules) demand verifiable safety, fairness, and transparency. Reliable systems earn trust, scale faster, and produce ROI; unreliable ones invite lawsuits and public backlash.What do I need to follow along with the book’s projects?
Install Python 3+ with pip, use a code editor (e.g., VS Code or Cursor), and obtain an OpenAI API key. Most examples use API calls rather than local hosting to keep setup simple and cost low; optional cloud services and tools are introduced later, with free-tier options where possible.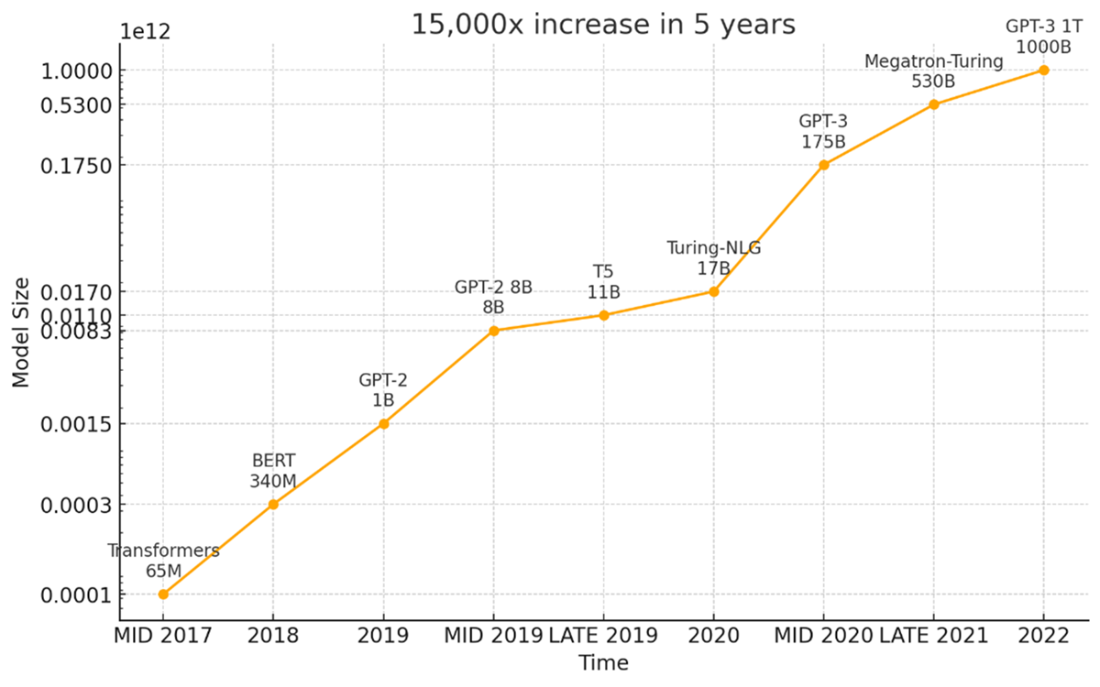
 Building Reliable AI Systems ebook for free
Building Reliable AI Systems ebook for free