Overview
7 Fine-Tuning LLMs for Improved Performance
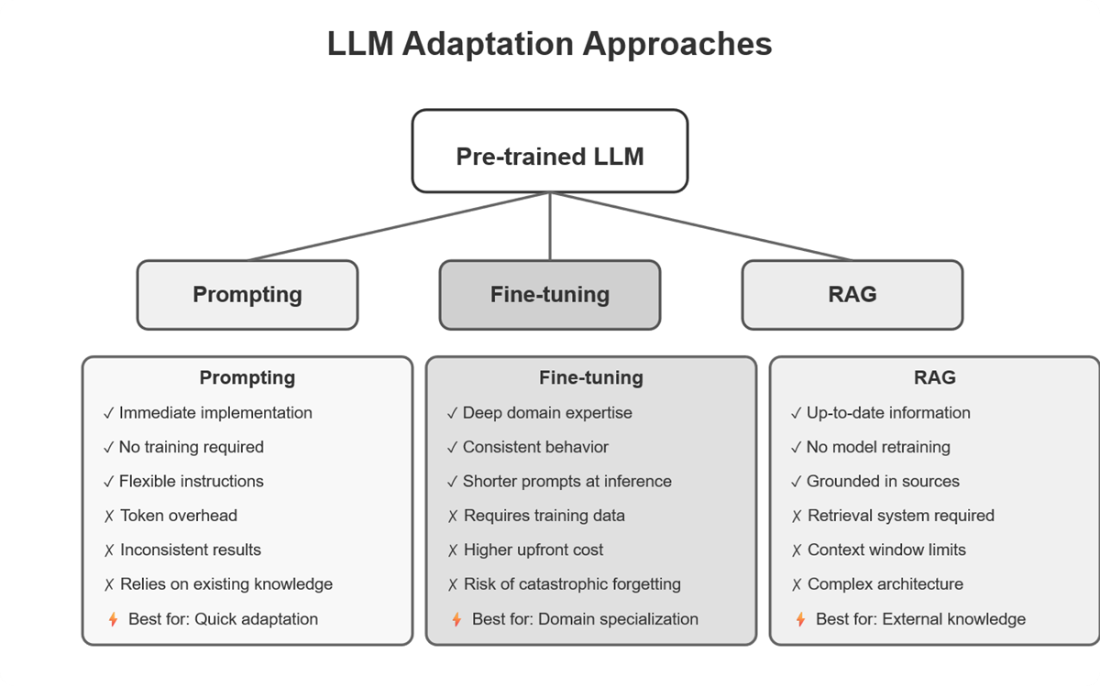
Modern LLMs are powerful generalists but often miss the mark in specialized domains or demanding workflows. This chapter explains how to choose among prompting, Retrieval-Augmented Generation (RAG), and fine-tuning, using a pragmatic decision framework: start by testing whether improved prompting meets the bar; if knowledge changes frequently, prefer RAG; and when you need consistent style, strict formats, or deep domain behavior, fine-tune. It also highlights a common production pattern that combines a fine-tuned core for reliable reasoning with RAG for up-to-date facts, yielding systems that are both accurate and current.
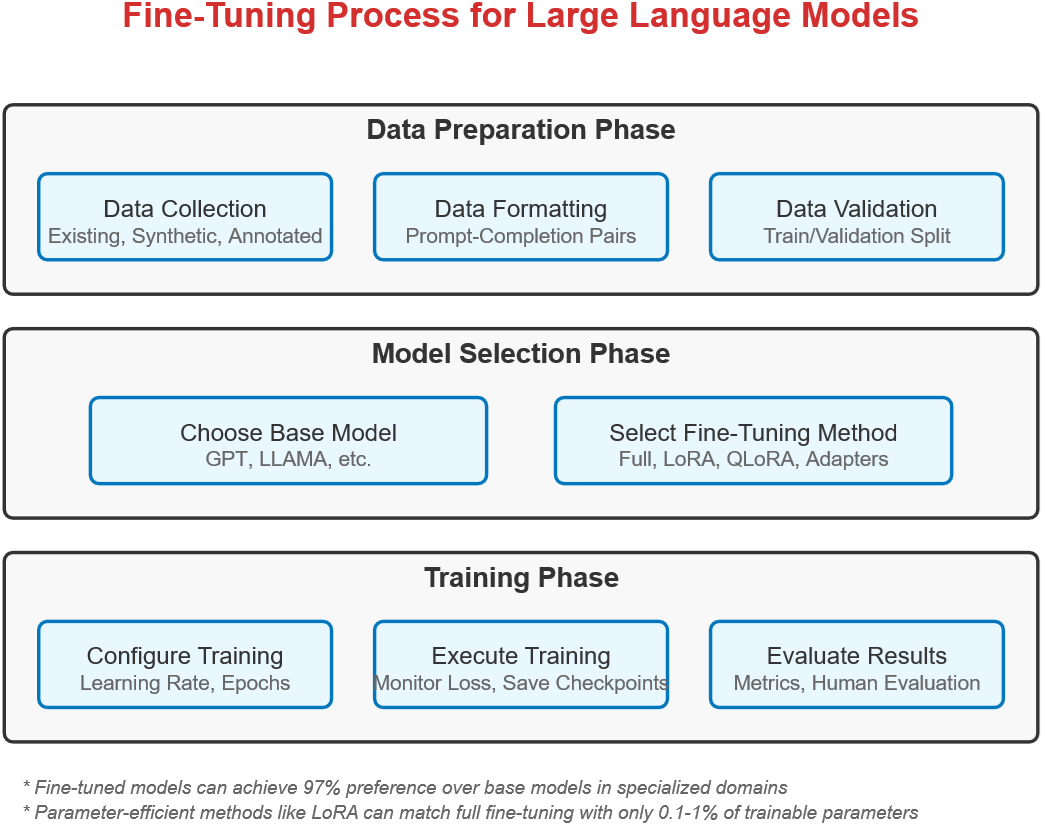
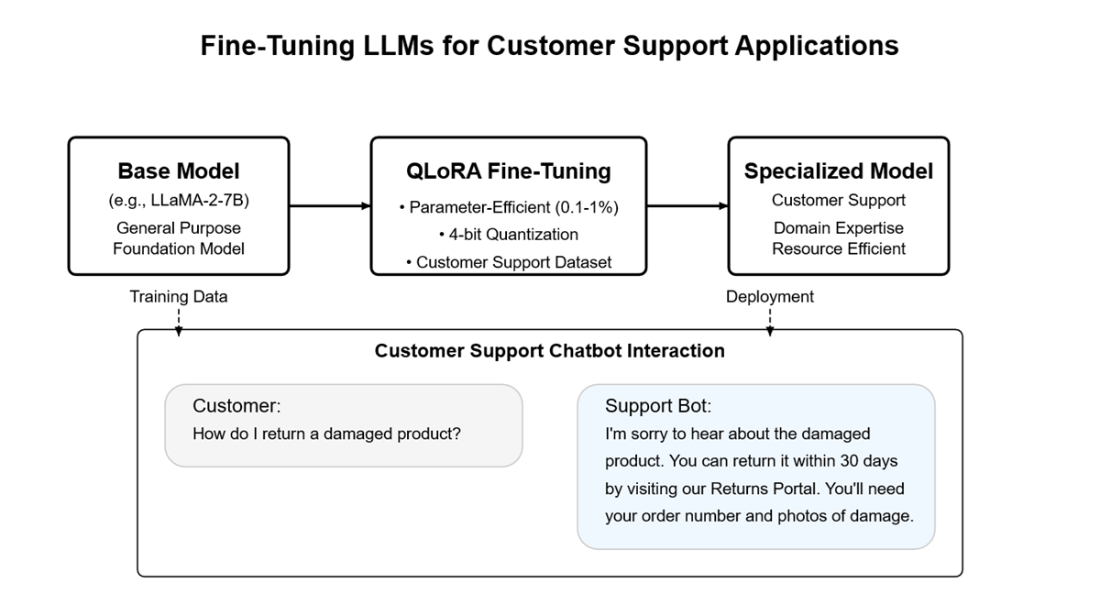
Through case studies in medicine (Med-PaLM 2), finance (BloombergGPT and FinGPT), and code generation (Codex), the chapter shows that domain specialization reliably boosts performance—provided the data is high quality. It details the fine-tuning workflow across three phases—data preparation, model selection, and training—emphasizing representative, well-formatted datasets, careful splits, and avoidance of leakage and bias. Both closed-source (e.g., managed APIs) and open-source paths are covered, along with trade-offs between full fine-tuning and parameter-efficient methods like LoRA and QLoRA. A hands-on project builds a customer support assistant with LLaMA-2-7B using QLoRA on consumer hardware, illustrating practical setup, formatting conventions, and sensible hyperparameters.
The chapter then moves from training to evaluation and deployment: validating with held-out data, monitoring checkpoints, and testing for tone, structure, reduced hallucinations, and adherence to policy. For real-world scalability, it introduces knowledge distillation—training a smaller student model to imitate a stronger teacher’s outputs—delivering major gains in cost and latency while preserving task quality. Best practices include starting with a strong teacher, collecting diverse, representative prompts and responses, evaluating frequently against realistic benchmarks, and retraining as needs evolve. Together, fine-tuning, RAG, and distillation form a practical toolkit for building reliable, efficient, and domain-accurate AI systems.
Summary
- Fine-tuning is a powerful method for adapting LLMs to specialized tasks when prompting and RAG alone aren’t sufficient.
- Prompting is quick and easy for basic tasks, while RAG is ideal for dynamic, factual information retrieval. Fine-tuning provides deep domain customization by updating the model’s weights.
- A hybrid of RAG + fine-tuning often provides the best of both worlds: live knowledge access and consistent reasoning.
- Successful fine-tuning depends on high-quality, well-formatted training data. Use prompt-completion pairs or structured chat examples.
- Parameter-efficient techniques like LoRA and QLoRA allow you to fine-tune large models on modest hardware with strong results.
- You can fine-tune both open-source models (e.g., LLaMA 2) and proprietary ones (e.g., OpenAI's GPT-4o) depending on your use case.
- Knowledge distillation enables you to train a smaller model to mimic a larger fine-tuned model—reducing cost and latency for deployment.
- Fine-tuning opens the door to building domain-aware assistants, structured generation tools, and highly customized LLM applications.
FAQ
How do I choose between prompting, RAG, and fine-tuning?
Use this quick decision flow: 1) Prompting test: improve your prompt and try 10 real cases; if ≥8 meet quality, stop at prompting (fastest, cheapest). 2) Data freshness: if facts change (daily/weekly/monthly), use RAG to fetch up-to-date info at query time. 3) Consistency and domain nuance: if you need strict style/format adherence or deep domain behavior on stable knowledge, fine-tune. In production, a hybrid often wins: fine-tune for behavior and use RAG for fresh facts.What exactly is fine-tuning and what gains can I expect?
Fine-tuning updates model weights on domain- or task-specific data so the model becomes a specialist. It improves precision, tone/style control, format compliance, and reduces hallucinations in your domain. Evidence: OpenAI reported that 50–100+ high-quality examples yield clear gains, and a few hundred can dramatically improve task performance versus zero-shot base models. Trade-offs: higher cost/effort, and knowledge becomes static until retrained.What are the core phases of the fine-tuning workflow?
Three phases: 1) Data Preparation: collect, clean, balance, annotate, and format representative examples. 2) Model Selection: pick a base model and a method (full FT, LoRA, QLoRA) that fits your hardware and goals. 3) Training and Evaluation: configure hyperparameters, run jobs, monitor metrics/checkpoints, validate to avoid overfitting, and prepare for deployment.How should I collect and curate high-quality training data?
- Use real, domain-specific text you have rights to (e.g., support logs, FAQs, legal/contracts, code). - Add human annotation where needed (labels, rankings, style corrections). - Prioritize quality over quantity; involve domain experts. - Remove incorrect facts and sensitive data; mitigate bias and ensure coverage across user intents/classes. - Match real deployment inputs/outputs (tone, jargon, formats).How do I format training examples and respect token limits?
- Match your platform’s expected format: prompt–completion pairs or chat-style messages. - Keep prompts and outputs consistent (role tags, JSON schemas, stop sequences). - Stay well under the model’s context length; split long docs into smaller examples. - For OpenAI, use JSONL with consistent roles and, if needed, explicit stop tokens. Consistent formatting strongly improves reliability.How do I evaluate, monitor, and avoid overfitting?
- Create a validation set (10–20%) with the same distribution as training; prevent data leakage. - Track validation loss/metrics during training; stop or select the best checkpoint when validation worsens. - For managed APIs, supply validation files and inspect per-epoch checkpoints. - Evaluate qualitative behavior too: tone, format adherence, factuality, and hallucination rates on real-world scenarios.Full fine-tuning vs LoRA vs QLoRA: which should I pick?
- Full fine-tuning: highest performance and flexibility, but requires large VRAM/multi-GPU and risks catastrophic forgetting. - LoRA: train small adapters (≈0.1–1% of params) for 95–99% of full-FT quality at a fraction of cost. - QLoRA: LoRA plus 4-bit quantized base weights; enables big models on limited GPUs with ~90–95% of full-FT performance. Choose full FT if you have heavy compute and need maximal adaptation; otherwise prefer LoRA/QLoRA.How do I fine-tune a closed-source model with OpenAI’s API?
Steps: 1) Prepare chat-format JSONL examples (system/user/assistant messages). 2) Upload the file with purpose=fine-tune. 3) Create a fine-tuning job (choose model, e.g., gpt-4o-mini; set n_epochs and optional validation). 4) Monitor events and checkpoints. 5) Use the returned fine-tuned model name (ft:...) in Chat Completions. Result: consistent tone/policies/behaviors without long prompts.How do I fine-tune an open-source model (e.g., LLaMA-2) with QLoRA?
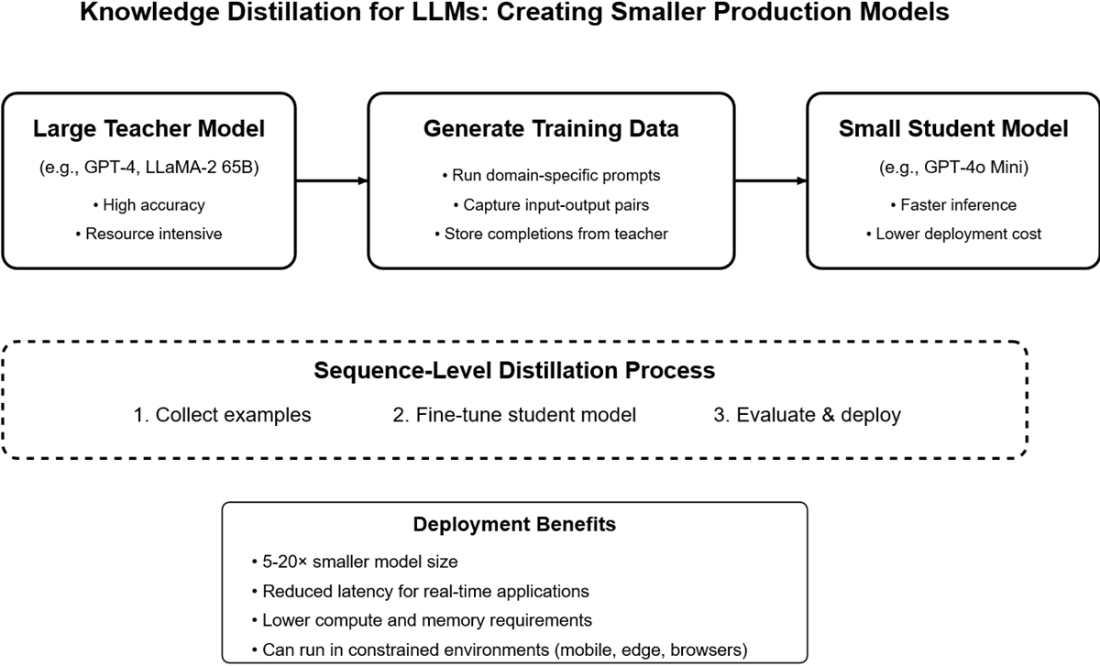
Outline: 1) Load a chat-tuned base (e.g., LLaMA-2-7B) with 4-bit quantization (bitsandbytes). 2) Add LoRA adapters (e.g., r=8, lora_alpha=16, target q_proj/v_proj, dropout=0.1). 3) Prepare a representative dataset (e.g., Bitext support) and format for the model’s instruction tokens ([INST]…[/INST]). 4) Train with SFTTrainer using small batch + gradient accumulation; fp16 for efficiency. 5) Save and deploy by loading base weights plus PEFT adapters.What is knowledge distillation and when should I use it?
Distillation trains a smaller student model to mimic a larger teacher by learning from the teacher’s input–output pairs (sequence-level distillation; no logits needed). Steps: collect teacher completions, define an eval benchmark, fine-tune the student (e.g., GPT‑4o Mini), then evaluate and iterate. Use it to cut cost and latency (often 5–20× smaller), and to deploy on constrained environments while preserving quality.

 Building Reliable AI Systems ebook for free
Building Reliable AI Systems ebook for free