1 Meet Apache Airflow
Modern organizations depend on timely, high‑quality data, and the chapter opens by framing data pipelines as the means to turn diverse operations—ingestion, transformation, model training, and delivery—into reliable, repeatable processes. It introduces Apache Airflow as an orchestration “conductor” that coordinates work across systems to produce trustworthy results, then sets expectations for a pragmatic, hands‑on journey: first understanding pipelines as graphs, then situating Airflow among workflow managers, and finally assessing whether Airflow fits your needs and how to get started.
The chapter explains why representing pipelines as directed acyclic graphs (DAGs) clarifies task dependencies, enforces correct ordering, and avoids deadlocks. This structure naturally yields a simple scheduling algorithm—run tasks when their upstreams are complete—and unlocks practical advantages over monolithic scripts: parallelizing independent branches, rerunning only failed tasks, and gaining a clear operational view. It also contrasts workflow managers at a high level, noting key trade‑offs such as “workflows as code” versus static definitions and the breadth of built‑in capabilities like scheduling and monitoring, emphasizing that tool selection should align with your requirements.
Airflow’s core value propositions are then surveyed: defining flexible, code‑driven DAGs (primarily in Python), rich integrations through providers, robust scheduling semantics, and a runtime architecture (DAG Processor, Scheduler, Workers, Triggerer, API server) that executes and observes pipelines. The web UI supports monitoring, troubleshooting with logs, retries, and selective reruns, while scheduling semantics enable incremental processing and backfilling for historical recomputation. The chapter closes with guidance on fit: Airflow excels for batch or event‑triggered workflows, time‑bucketed processing, and engineering‑driven teams seeking extensibility and open‑source stability (with managed options available); it is less suited to real‑time streaming or teams preferring purely graphical, low‑code tools, and it does not natively cover areas like comprehensive lineage/versioning. The remainder of the book progresses from foundations to advanced patterns and deployment practices.
For this weather dashboard, weather data is fetched from an external API and fed into a dynamic dashboard.
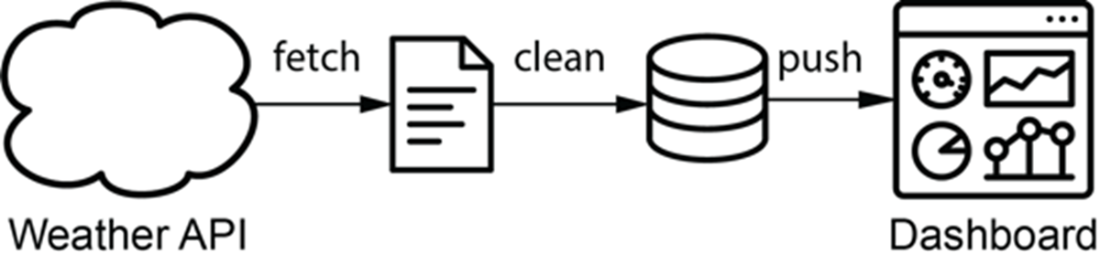
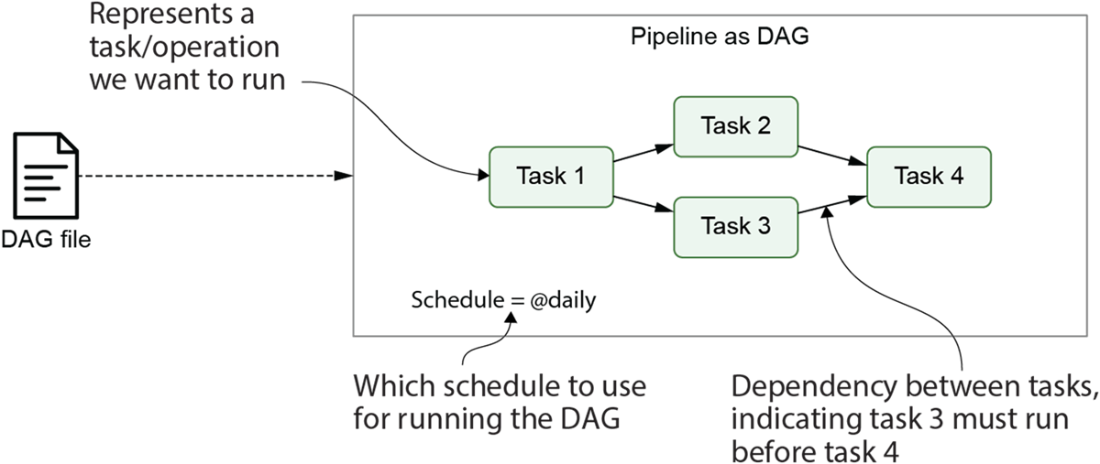
Graph representation of the data pipeline for the weather dashboard. Nodes represent tasks and directed edges represent dependencies between tasks (with an edge pointing from task 1 to task 2, indicating that task 1 needs to be run before task 2).

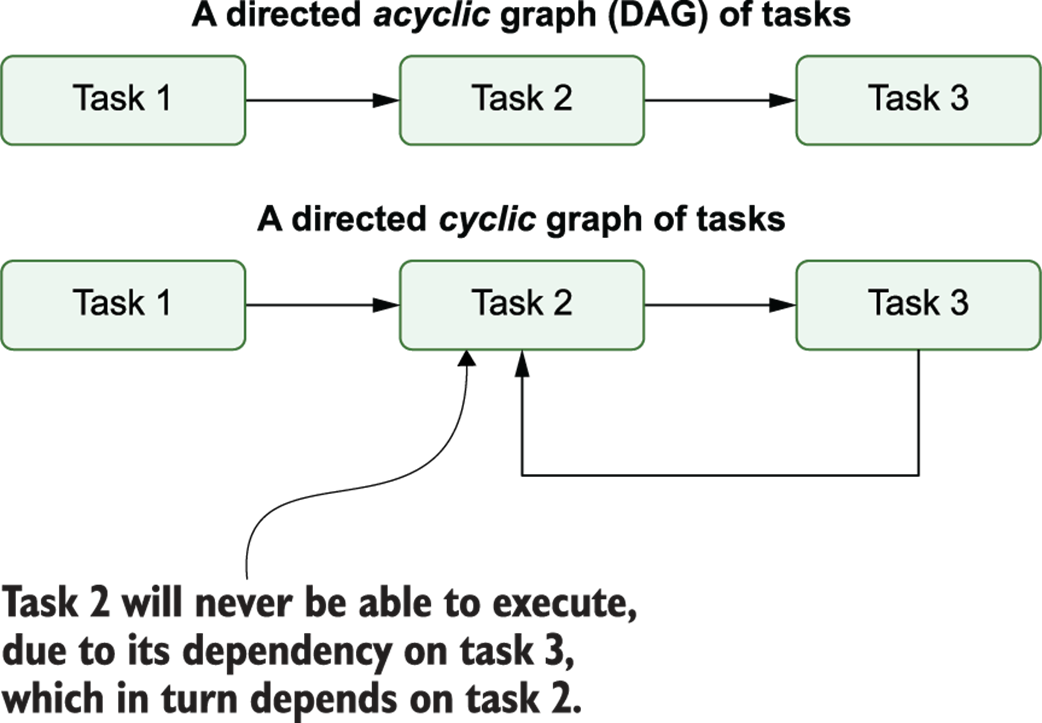
Cycles in graphs prevent task execution due to circular dependencies. In acyclic graphs (top), there is a clear path to execute the three different tasks. However, in cyclic graphs (bottom), there is no longer a clear execution path due to the interdependency between tasks 2 and 3.
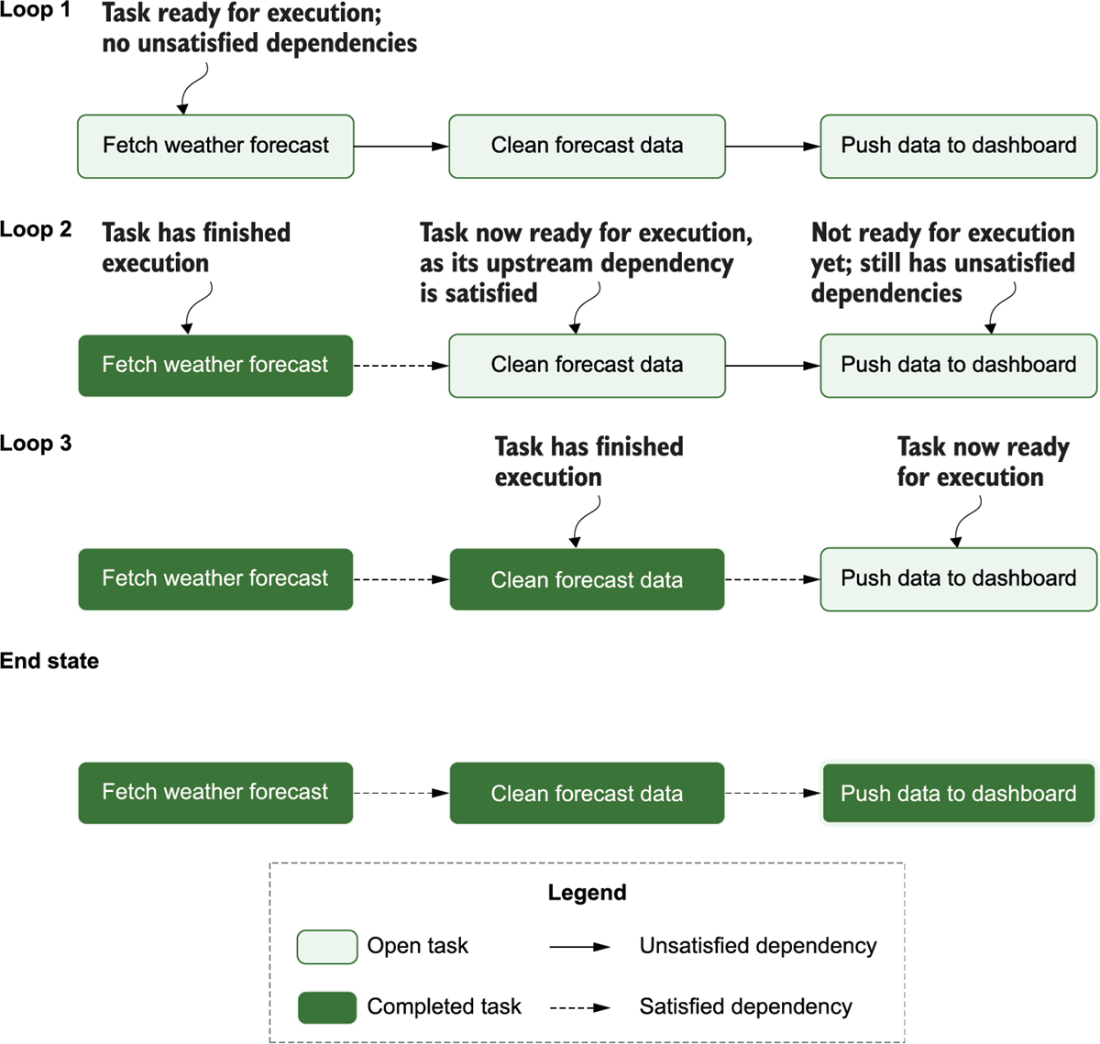
Using the DAG structure to execute tasks in the data pipeline in the correct order: depicts each task’s state during each of the loops through the algorithm, demonstrating how this leads to the completed execution of the pipeline (end state)
Overview of the umbrella demand use case, in which historical weather and sales data are used to train a model that predicts future sales demands depending on weather forecasts
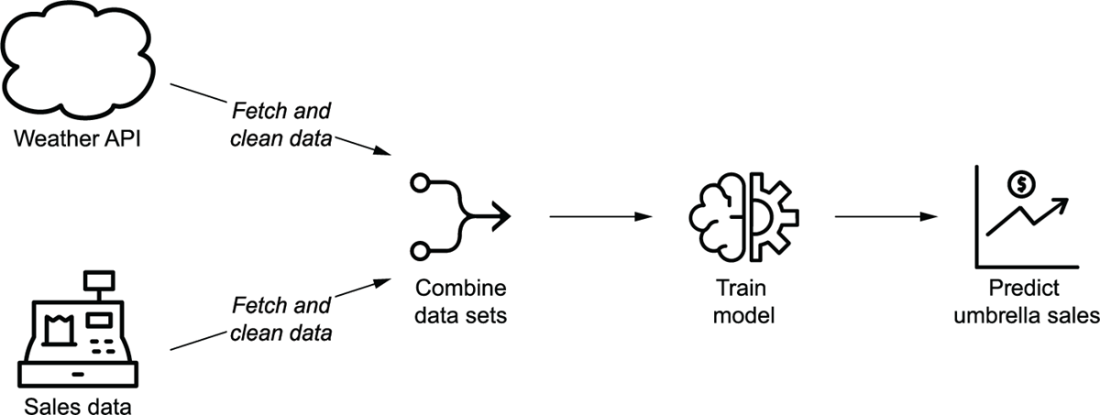
Independence between sales and weather tasks in the graph representation of the data pipeline for the umbrella demand forecast model. The two sets of fetch/cleaning tasks are independent as they involve two different data sets (the weather and sales data sets). This independence is indicated by the lack of edges between the two sets of tasks.

Airflow pipelines are defined as DAGs using Python code in DAG files. Each DAG file typically defines one DAG, which describes the different tasks and their dependencies. Besides this, the DAG also defines a schedule interval that determines when the DAG is executed by Airflow.
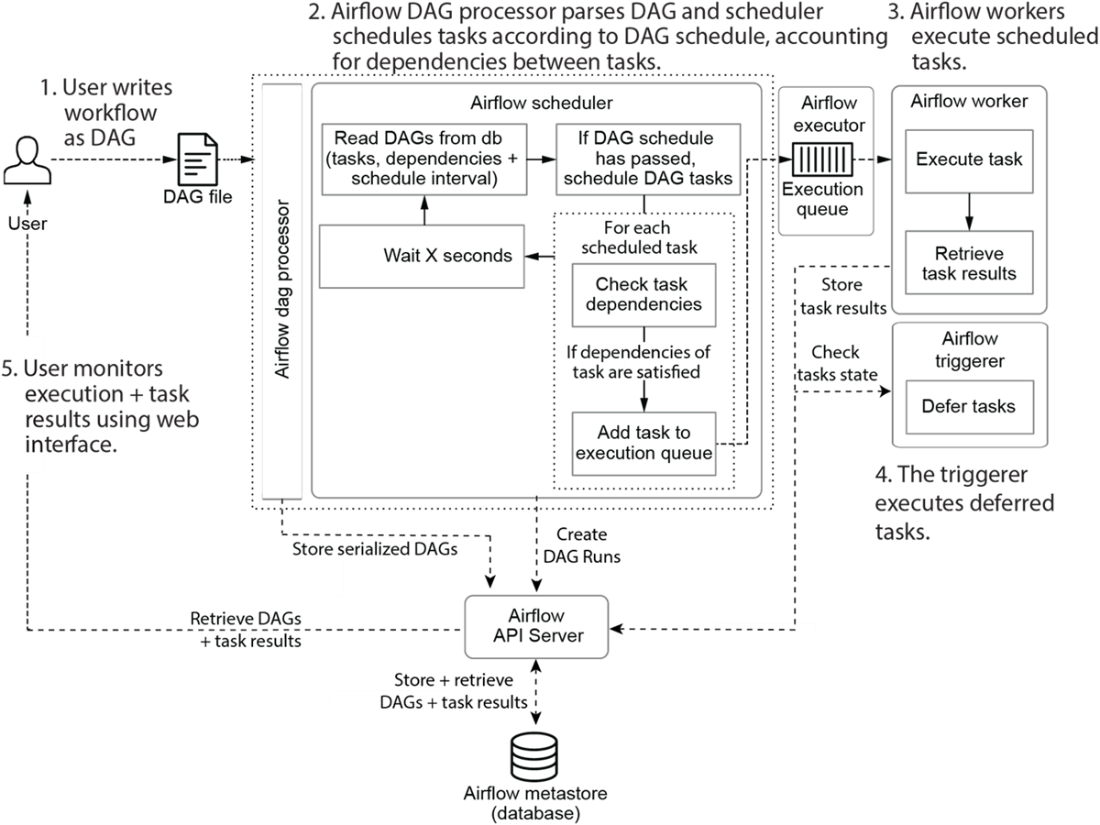
The main components involved in Airflow are the Airflow API server, scheduler, DAG processor, triggerer and workers.

Developing and executing pipelines as DAGs using Airflow. Once the user has written the DAG, the DAG Processor and scheduler ensure that the DAG is run at the right moment. The user can monitor progress and output while the DAG is running at all times.
The login page for the Airflow web interface. In the code examples accompanying this book, a default user “airflow” is provided with the password “airflow”.
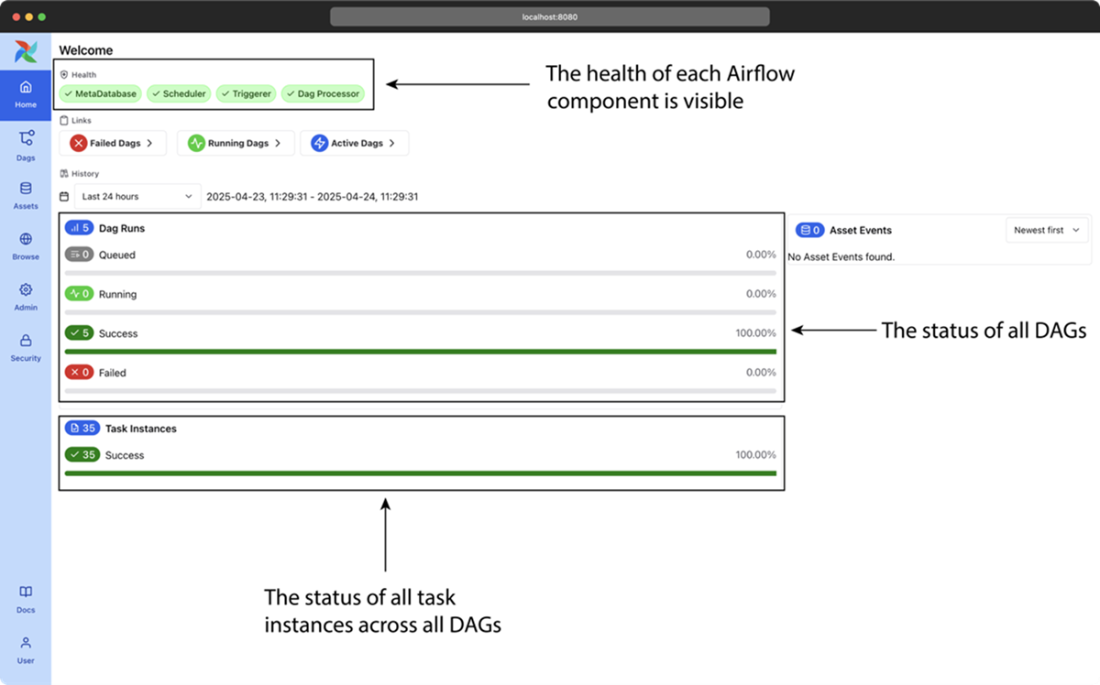
The main page of Airflow’s web interface, showing a high-level overview of all DAGs and their recent results.
The DAGs page of Airflow’s web interface, showing a high-level overview of all DAGs and their recent results.

The graph view in Airflow’s web interface, showing an overview of the tasks in an individual DAG and the dependencies between these tasks
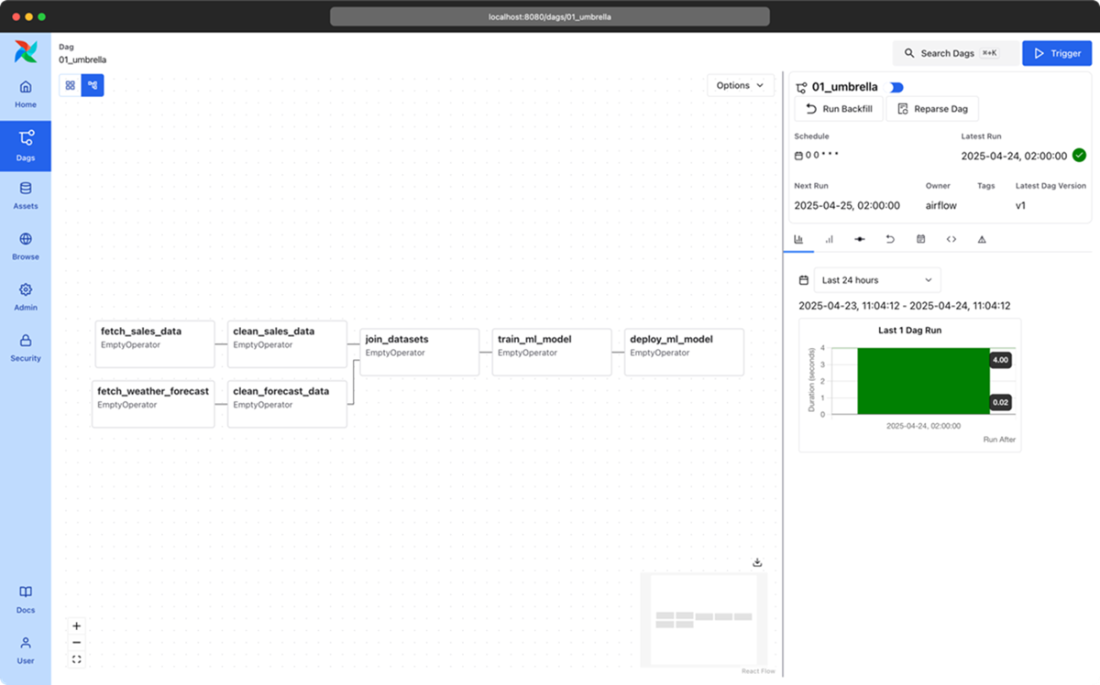
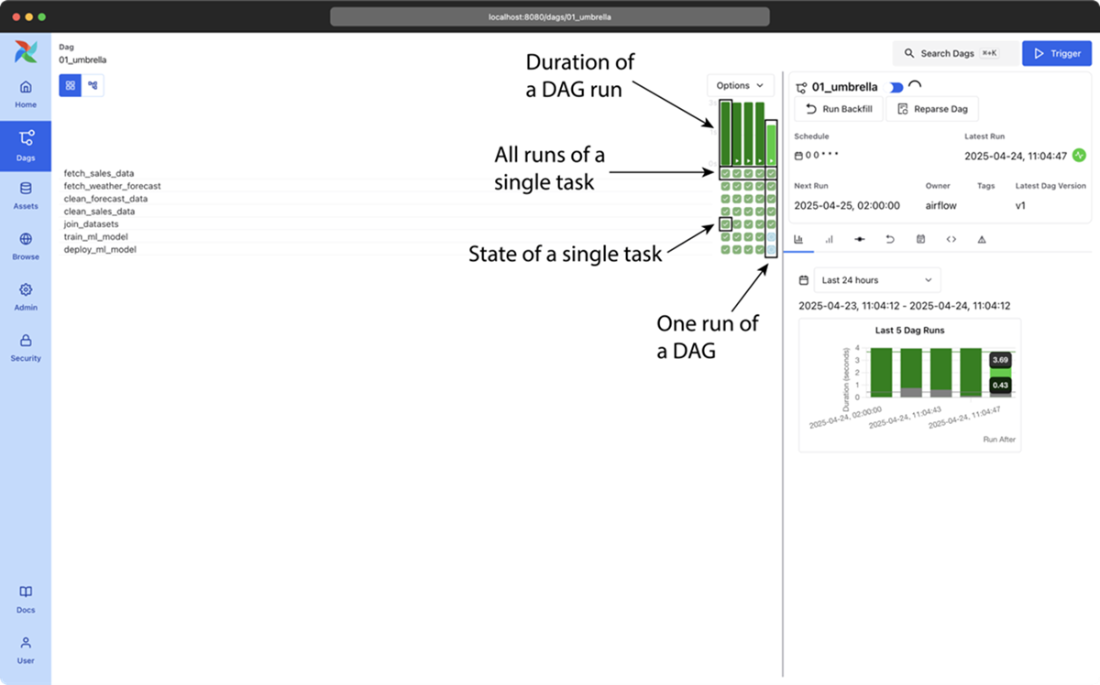
Airflow’s grid view, showing the results of multiple runs of the umbrella sales model DAG (most recent + historical runs). The columns show the status of one execution of the DAG and the rows show the status of all executions of a single task. Colors (which you can see in the e-book version) indicate the result of the corresponding task. Users can also click on the task “squares” for more details about a given task instance, or to manage the state of a task so that it can be rerun by Airflow, if desired.x
Summary
- Directed Acyclic Graphs (DAGs) are a visual tool used to represent data workflows in data processing pipelines. A node in a DAG denote the task to be performed, and edges define the dependencies between them. This is not only visually more understandable but also aids in better representation, easier debugging + rerunning, and making use of parallelism compared to single monolithic scripts.
- In Airflow, DAGs are defined using Python files. Airflow 3.0 introduced the option of using other languages. In this book we will focus on Python. These scripts outline the order of task execution and their interdependencies. Airflow parses these files to construct and understand the DAG's structure, enabling task orchestration and scheduling.
- Although many workflow managers have been developed over the years for executing graphs of tasks, Airflow has several key features that makes it uniquely suited for implementing efficient, batch-oriented data pipelines.
- Airflow excels as a workflow orchestration tool due to its intuitive design, scheduling capabilities, and extensible framework. It provides a rich user interface for monitoring and managing tasks in data processing workflows.
- Airflow is comprised of five key components:
- DAG Processor: Reads and parses the DAGs and stores the resulting serialized version of these DAGs in the Metastore for use by (among others) the scheduler
- Scheduler: Reads the DAGs parsed by the DAG Processor, determines if their schedule intervals have elapsed, and queues their tasks for execution.
- Worker: Execute the tasks assigned to them by the scheduler.
- Triggerer: It handles the execution of deferred tasks, which are waiting for external events or conditions.
- API Server: Among other things, presents a user interface for visualizing and monitoring the DAGs and their execution status. The API Server also acts as the interface between all Airflow components
- Airflow enables the setting of a schedule for each DAG, specifying when the pipeline should be executed. In addition, Airflow’s built-in mechanisms are able to manage task failures, automatically.
- Airflow is well-suited for batch-oriented data pipelines, offering sophisticated scheduling options that enable regular, incremental data processing jobs. On the other hand, Airflow is not the right choice for streaming workloads or for implementing highly dynamic pipelines where DAG structure changes from one day to the other.
FAQ
What is Apache Airflow and what problem does it solve?
Airflow is an open-source platform for authoring, scheduling, and monitoring workflows as Directed Acyclic Graphs (DAGs). It orchestrates tasks across multiple systems so data pipelines run reliably and in the right order, helping teams manage growing data volumes efficiently.What is a DAG and why must it be acyclic?
A DAG is a graph where nodes are tasks and directed edges express dependencies. “Acyclic” means no loops; this prevents circular dependencies that would deadlock execution (e.g., A depends on B while B depends on A), ensuring there’s always a valid order to run tasks.How does a DAG execute in principle?
- Identify tasks whose upstream dependencies are complete and place them on a run queue.- Execute queued tasks and mark them finished when done.
- Repeat until all tasks are complete. This enables correct ordering and parallelism where dependencies allow.
Why represent pipelines as graphs instead of one big script?
- Clarity: dependencies are explicit and easy to reason about.- Parallelism: independent branches can run concurrently to reduce runtime.
- Resilience: you can rerun only failed tasks (and downstream ones) instead of the whole script.
- Modularity: smaller, focused tasks are easier to maintain and test.
How are pipelines defined in Airflow?
Workflows are written as Python DAG files that declare tasks and their dependencies plus metadata like schedules. While Airflow 3.0 introduced options for other languages, Python remains the primary way to define pipelines and is the language Airflow itself is built on.What kinds of systems can Airflow integrate with?
Airflow’s Python foundation and a rich ecosystem of “provider” packages let you connect to databases, big data engines, and major cloud services. This enables end-to-end pipelines that span fetching, transforming, modeling, and loading data across diverse platforms.How does Airflow schedule and run tasks? What are the main components?
- Scheduler: checks DAG schedules and enqueues runnable tasks.- Workers: execute tasks in parallel and report results.
- Triggerer: manages async/deferred tasks waiting on external conditions.
- DAG Processor: parses DAG files and stores metadata.
- API server: central interface for the UI and components to access the metastore. Schedules can be simple intervals or Cron-like expressions.
 Data Pipelines with Apache Airflow, Second Edition ebook for free
Data Pipelines with Apache Airflow, Second Edition ebook for free