The chapter opens by acknowledging the growing pains of modern data work: as collecting and storing data becomes cheaper, practitioners increasingly collide with the limits of single-machine tools, experiencing slow runs, instability, and unwieldy workflows. It situates Python’s data stack (NumPy, SciPy, Pandas, Scikit-learn) as the on-ramp that democratized data science, while clarifying that these libraries excel primarily for small, in-memory datasets. To reason about scale, the text introduces a practical tiering—small, medium, and large data—highlighting when paging, parallelism, or distribution become necessary and when conventional tools start to fail. The chapter’s goal is to equip readers—especially beginner to intermediate data scientists and engineers—with the foundational concepts behind scalable computing and to motivate why Dask belongs in a modern toolkit.
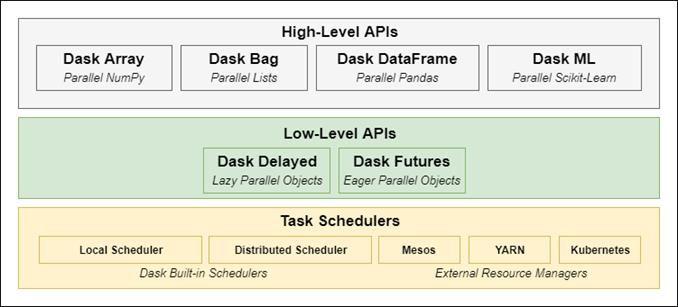
Dask is presented as a Python-native bridge from familiar single-machine workflows to parallel and distributed computation. Its layered design centers on a task scheduler that manages computations expressed through low-level primitives (Delayed and Futures) and exposed via high-level collections that mirror NumPy arrays, Pandas DataFrames, and more. By chunking data into partitions and orchestrating many small tasks, Dask preserves familiar APIs while enabling work to scale from a laptop to a cluster with minimal code changes and low operational overhead. Beyond collections, its low-level APIs generalize to custom Python workloads, making it a flexible parallel framework. A brief comparison notes that while other systems are powerful, Dask’s tight alignment with Python, short learning curve, and versatility make it especially appealing to users steeped in the Python data stack.
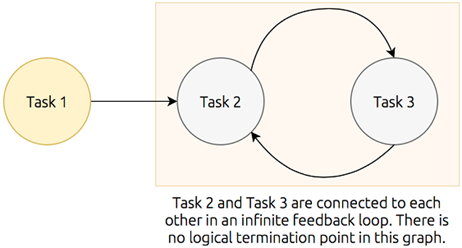
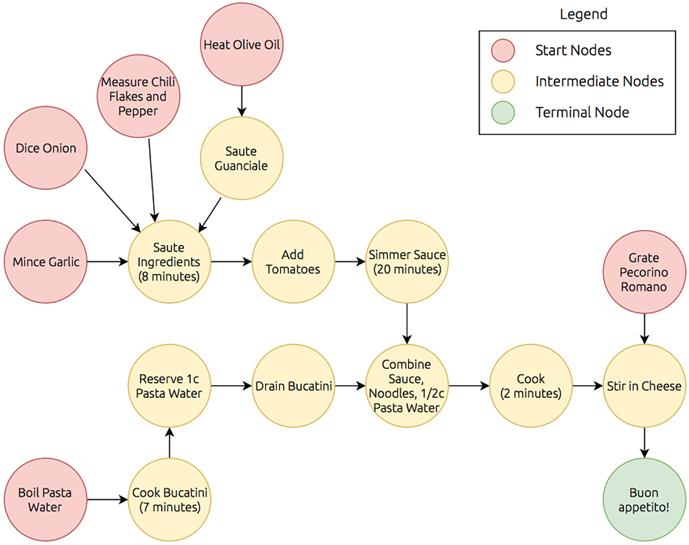
The conceptual backbone of Dask’s execution model is the directed acyclic graph (DAG), which encodes computations as nodes with explicit dependencies, making order, parallelism, and optimization transparent. Using a cooking analogy, the chapter illustrates how DAGs prevent cycles, capture transitive dependencies, and help expose bottlenecks and opportunities for reordering. With this model, the scheduler can prioritize tasks near outputs, stream results early, and manage memory efficiently, while also handling real-world concerns: deciding when to scale up versus scale out, enforcing concurrency limits and resource locks, and recovering from worker failures or data loss by replaying lineage. The chapter closes by introducing a real, messy, medium-scale companion dataset of NYC parking tickets that will anchor hands-on examples throughout the book.
The components and layers than make up Dask
My favorite recipe for bucatini all'Amatriciana

A graph displaying nodes with dependencies

An example of a cyclic graph demonstrating an infinite feedback loop
The graph represented in figure 1.3 redrawn without transitive reduction
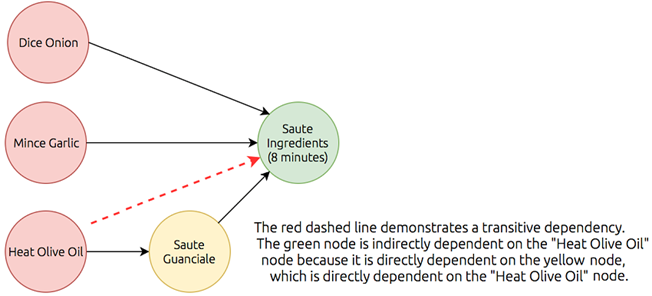
The full directed acyclic graph representation of the bucatini all’Amatriciana recipe.
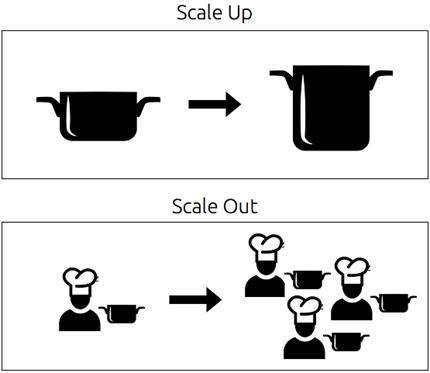
Scaling up replaces existing equipment with larger/faster/more efficient equipment, while scaling out divides the work between many workers in parallel.
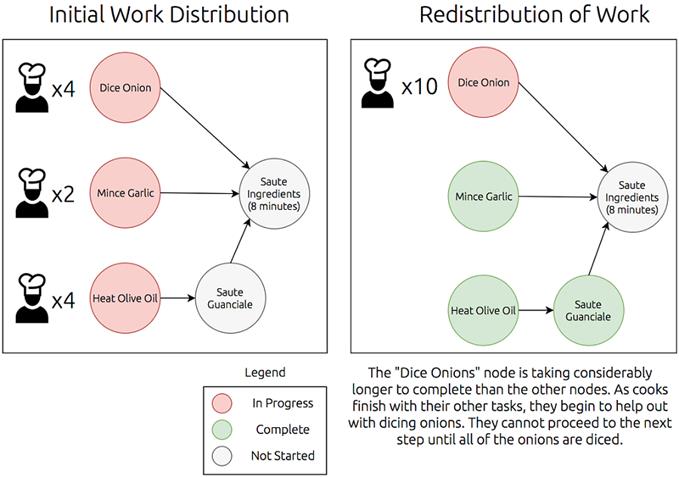
A graph with nodes distributed to many workers depicting dynamic redistribution of work as tasks complete at different times.
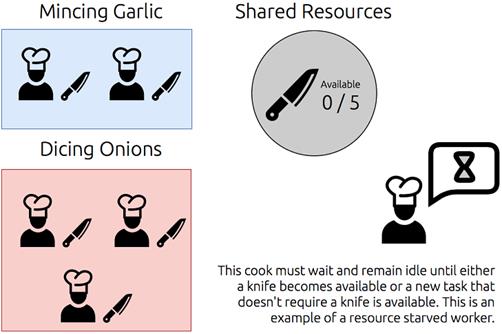
An example of resource starvation
Summary
In this chapter you learned
- Dask can be used to scale popular data analysis libraries such as Pandas and NumPy, allowing you to analyze medium and large datasets with ease.
- Dask uses directed acyclic graphs (DAGs) to coordinate execution of parallelized code across CPU cores and machines.
- Directed acyclic graphs are comprised of nodes, have a clearly defined start and end, a single traversal path, and no looping.
- Upstream nodes must be completed before work can begin on any dependent downstream nodes.
- Scaling out can generally improve performance of complex workloads, but it creates additional overhead that might substantially reduce those performance gains.
- In the event of a failure, the steps to reach a node can be repeated from the beginning without disturbing the rest of the process.
FAQ
What problem does this chapter address, and why does scalable computing matter?
It tackles the common pain of working with datasets that outgrow a single machine: long runtimes, out-of-memory errors, fragile code, and clunky workflows. As data volumes grow, traditional single-machine tools struggle, so scalable computing frameworks like Dask help you analyze and model larger datasets efficiently.How does the chapter define small, medium, and large datasets?
- Small: roughly under 2–4 GB, fits in RAM and on local disk; tools like Pandas/NumPy/Scikit-learn work well without paging.- Medium: roughly 10 GB to 2 TB, fits on local disk but not in RAM; paging (spilling to disk) and lack of parallelism become bottlenecks.
- Large: greater than ~2 TB, does not fit in RAM or a single machine’s disk; requires distributed computing.
Why choose Dask for data science?
Dask brings native scalability to the Python data stack and offers four key advantages: it’s fully in Python and scales NumPy/Pandas/Scikit-learn; it works on both a single machine (medium data) and clusters (large data); it can parallelize general Python workflows via low-level APIs; and it has low setup and maintenance overhead.How is Dask structured under the hood?
At its core is a task scheduler that executes computations across cores and machines. Low-level APIs (Delayed for lazy evaluation, Futures for eager evaluation) build task graphs. High-level collections (Dask DataFrame, Array, Bag) sit atop these, translating familiar Pandas/NumPy-style operations into many parallel tasks managed by the scheduler.What are DAGs and why do they matter in Dask?
A directed acyclic graph (DAG) represents work as nodes (tasks) connected by directed edges (dependencies) with no cycles. Dask composes your computation as a DAG so the scheduler can run independent tasks in parallel, respect prerequisites, optimize execution order, reduce memory pressure, and monitor progress.When should I scale up versus scale out?
- Scale up: choose a bigger/faster machine when problems sit near the upper end of “medium” and parallelism is limited; it’s simpler operationally, especially in the cloud.- Scale out: add workers when tasks parallelize well or data is large; it offers better long-term headroom but introduces coordination costs that Dask’s scheduler helps manage.
 Data Science with Python and Dask ebook for free
Data Science with Python and Dask ebook for free