Searching for information is often like consulting a librarian who may not share your context, language, or up‑to‑date understanding. The chapter frames web search engines as many such “librarians” and introduces the idea of an assistant—embodied by deep learning—that can translate user intent, add context, and highlight what matters. Deep learning, a subfield of machine learning, learns layered representations with deep neural networks; in this book it serves as the adviser that shapes how a search engine interprets queries and content, a perspective the authors call neural search.
Before turning to neural methods, the chapter grounds readers in core information retrieval: text analysis pipelines break documents into tokens and terms; inverted indexes map terms to documents for fast retrieval; query parsers interpret user input; and ranking models estimate relevance (e.g., vector space with TF‑IDF, probabilistic approaches like BM25). Effectiveness is assessed with precision and recall. Despite these tools, persistent user problems remain: relevance depends on subjective context, queries usually require iteration, systems behave like black boxes sensitive to small phrasing changes or language choice, and traditional keyword matching struggles to capture semantics across text and media.
Deep learning addresses these gaps by learning semantic representations (embeddings) for words, sentences, documents, and images, enabling similarity grounded in meaning (e.g., placing “AI” near “artificial intelligence”), robust query expansion, multilingual retrieval via neural translation, image understanding without manual metadata, content generation, and improved recommendations. The chapter also outlines practical integration: training costs and data needs, the value of online learning, and storing model artifacts (such as embeddings) alongside index terms to keep systems efficient. Throughout the book, the authors focus on principled, measurable improvements—using open-source tools while emphasizing concepts—to enhance relevance, coverage, and user experience, acknowledging that neural search is powerful but not magical and must be engineered with care.
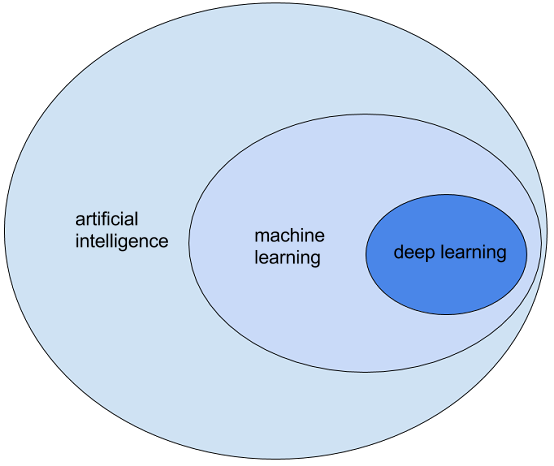
Figure 1.1. Artificial intelligence, machine learning, deep learning
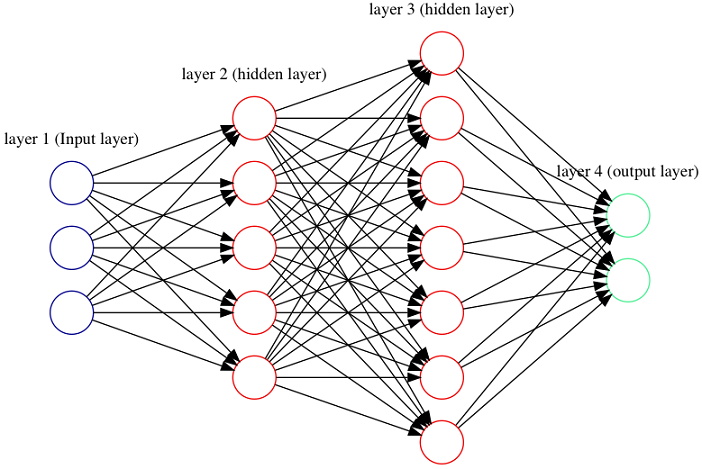
Figure 1.2. A deep feed forward neural network with 2 hidden layers
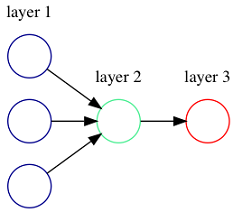
Figure 1.3. An artificial neuron (green) with 3 inputs and 1 output
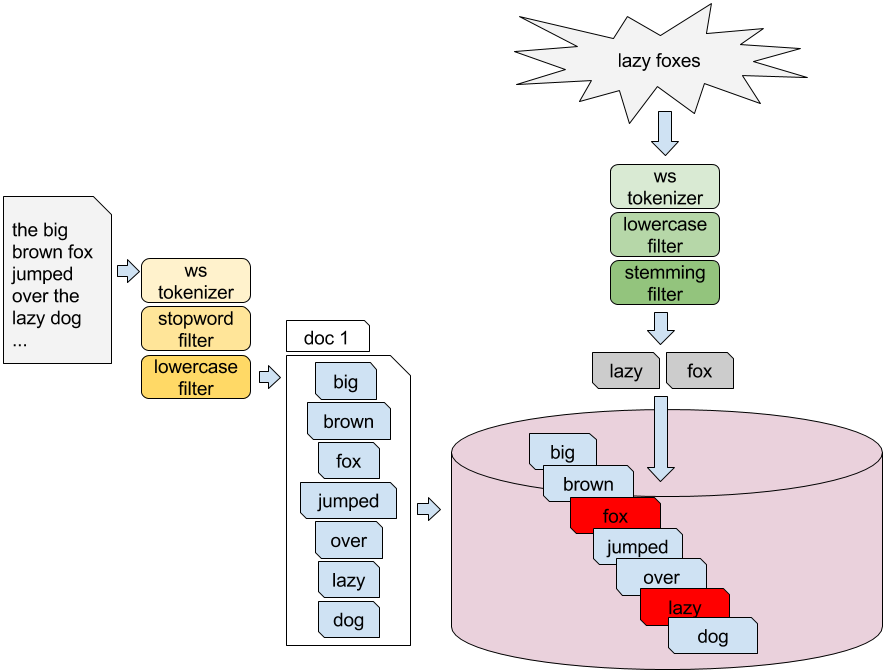
Figure 1.4. Getting the words of "I like search engines" using a simple text analysis pipeline
Figure 1.5. The traversed token graph
Figure 1.6. Index, search time analysis and term matching
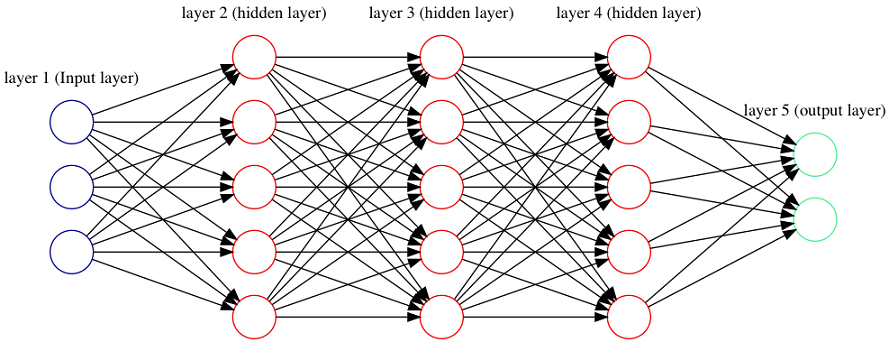
Figure 1.8. A deep feed forward neural network with 3 hidden layers
Figure 1.9. Word vectors derived from papers on word2vec
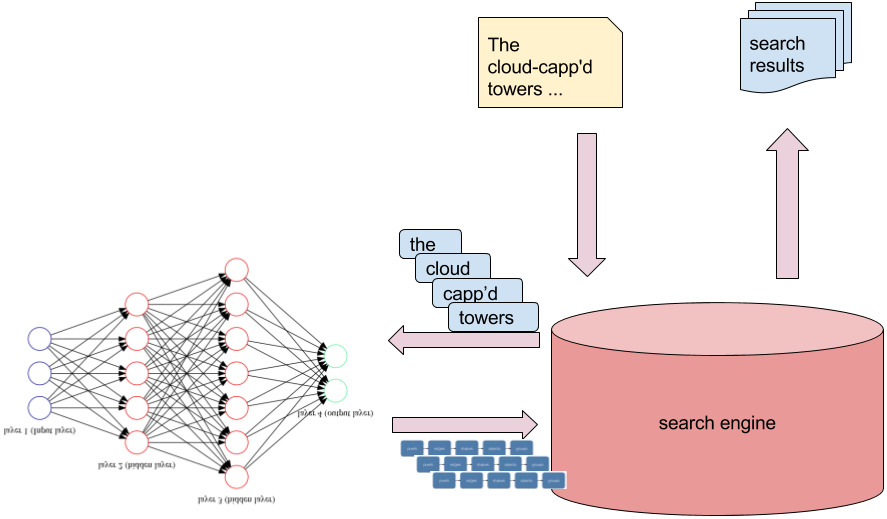
Figure 1.10. A neural search application: using word representations generated by a deep neural network to provide more relevant results
Summary
Search is a hard problem: common approaches to information retrieval come with some limitations and disadvantages, and both users and search engineers can have a hard time making things work as expected.
Text analysis is an important task in search, for both indexing and search phases, because it prepares the data to be stored in the inverted indexes and has a high influence on the effectiveness of a search engine.
Relevance is the fundamental measure of how well the search engine responds to users' information needs. Some information retrieval models can give a standardized measure of the importance of results with respect to queries, but there is no silver bullet. Context and opinions can float significantly among users, and therefore measuring relevance needs to be a continuous focus for a search engineer
Deep learning is a field in machine learning that makes use of deep neural networks to learn (deep) representations of content (text like words, sentences, paragraphs, but also images) that can capture semantically relevant similarity measures.
Neural search stands as a bridge between search and deep neural networks with the goal of using deep learning to help improve different tasks related to search.
FAQ
What is neural search?Neural search is the application of deep artificial neural networks to information retrieval. It uses deep learning to influence how a search engine analyzes, retrieves, and ranks results, aiming for more effective, context-aware search. The term relates to “neural information retrieval,” popularized at a SIGIR 2016 workshop.Why do we need neural search if web search already works well?Neural search addresses common pain points: finding more relevant results faster, reducing the need to read many documents to grasp a topic, overcoming language barriers, and enabling image search by content rather than manual tags. Deep neural networks learn semantic representations, generate text, represent images by objects, and perform translation—capabilities that improve search quality and user experience.How do search engines work at a high level?They perform:
- Indexing: analyze and store data for fast retrieval.
- Querying: parse user queries and match them against the index.
- Ranking: score and order results by relevance to the user’s need.
Efficiency is critical so users get useful information quickly.What is text analysis and why does it matter?Text analysis breaks raw text into searchable terms using tokenizers and token filters (e.g., stopword removal, lowercasing, stemming). It runs both at index time and search time. The chosen analysis pipeline controls what matches what—for example, removing “the” from content improves efficiency and relevance, while titles may need exact matching without aggressive filtering.What is an inverted index?An inverted index maps each term to a posting list of document IDs that contain it. This structure enables fast retrieval: given a term, the engine directly fetches matching documents rather than scanning all text. Search systems often keep multiple fields or indexes (e.g., title vs. body) with different analysis settings.What does “relevance” mean and how is it modeled?Relevance measures how well a result satisfies a query. Common retrieval models include:
- Vector Space Model with TF-IDF weights to compare query/document vectors.
- Probabilistic models such as Okapi BM25 estimating the likelihood a document is relevant.
These provide strong baselines but typically need tuning and careful analysis design.How does deep learning improve relevance?Deep learning learns embeddings (vector representations) for words, sentences, and documents from context. Semantically similar terms (e.g., “artificial intelligence” and “AI”) end up close in vector space, helping queries match relevant documents even when wording differs. Embeddings can be used to expand queries, re-rank results, and better capture semantics than keyword-only methods.What are precision and recall, and how are they measured?Precision is the fraction of retrieved documents that are relevant; high precision means top results are mostly useful. Recall is the fraction of relevant documents that are retrieved; high recall means the system finds most relevant items. Evaluations often require human judgments or public benchmarks (e.g., TREC datasets).How do we integrate neural networks into a search engine in practice?Key considerations:
- Training: needs time and data; consider online learning to handle evolving indexes.
- Consistency: when retraining is costly, temporarily discount or unplug stale models.
- Model storage: persist models to avoid retraining on restart; for word embeddings, store vectors alongside terms in the index for efficient lookup.
Typical stacks in the book use Apache Lucene for search and Deeplearning4j for deep learning.What are the promises and limitations of neural search?Promises: better relevance, semantic matching, cross-lingual serving via neural machine translation, image search by content, and recommendation via similarity in embedding space. Limitations: training cost, model updates, integration complexity, and no guaranteed “automagic” fix—solutions must be context-aware and measured for accuracy and performance.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!




 Deep Learning for Search ebook for free
Deep Learning for Search ebook for free