1 Small Language Models
This chapter introduces Small Language Models as a practical, efficient alternative to very large generalist language models. It explains that SLMs use the same Transformer-based foundations as larger models but operate at a much smaller scale, typically with far fewer parameters, lower memory needs, reduced computational requirements, and better suitability for local, edge, offline, or on-premise deployment. The chapter frames SLMs as especially valuable when organizations need privacy, lower cost, faster inference, energy efficiency, or domain-specific behavior rather than broad general-purpose capability.
The chapter also gives a high-level overview of how modern language models emerged from the Transformer architecture. It contrasts Transformers with earlier recurrent neural networks, emphasizing self-attention, parallel processing, word embeddings, and self-supervised learning as key advances that enabled models to train on massive unlabeled text corpora and develop capabilities beyond basic language tasks. It also describes major Transformer evolutions, including encoder-focused models such as BERT for classification and prediction, decoder-focused models such as GPT for generation, and reinforcement learning from human feedback as a technique used to improve conversational behavior.
Finally, the chapter compares commercial closed-source generalist LLMs, open-source models, and domain-specific models from a business perspective. Generalist LLMs are powerful and easy to access, but they introduce risks around data exposure, lack of transparency, limited reproducibility, hallucinations, vendor control, and security concerns. Open-source pretrained models reduce the cost of building custom solutions, while domain-specific tuning allows organizations to use private or specialized data for better accuracy, compliance, and contextual understanding in fields such as healthcare, finance, chemistry, manufacturing, and biotechnology. The chapter concludes by positioning optimized, customized SLMs as a strong foundation for cost-effective inference, deployment flexibility, retrieval-augmented generation, and agentic AI systems.
Some examples of diverse content an LLM can generate.
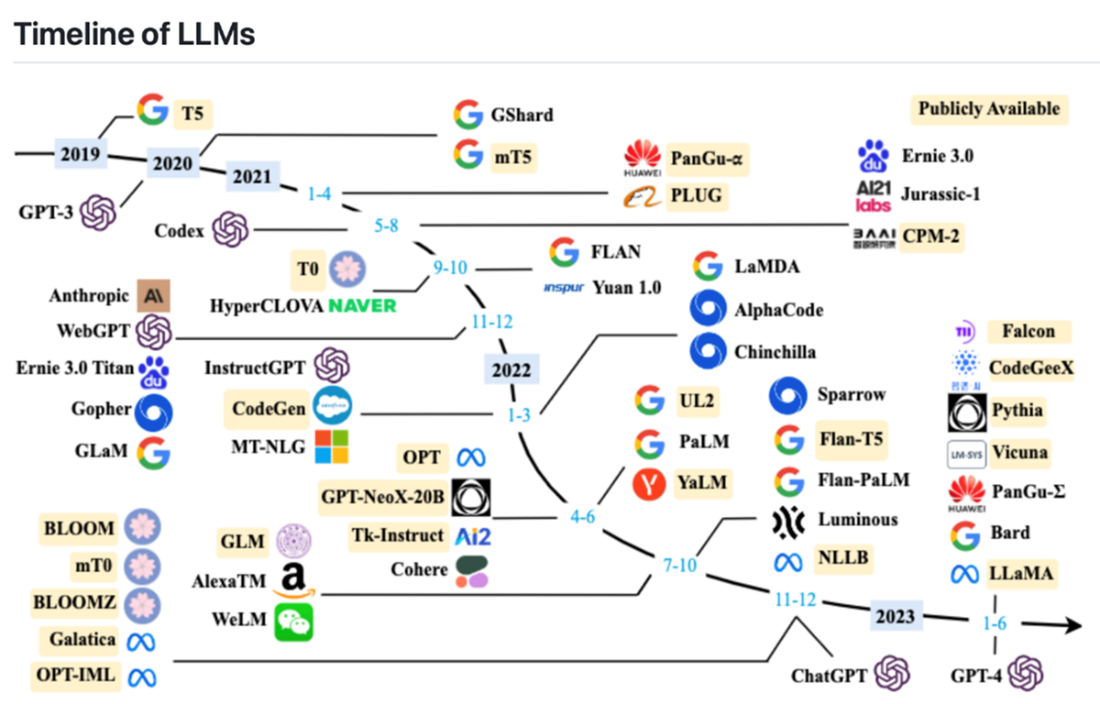
The timeline of LLMs since 2019 (image taken from paper [3])
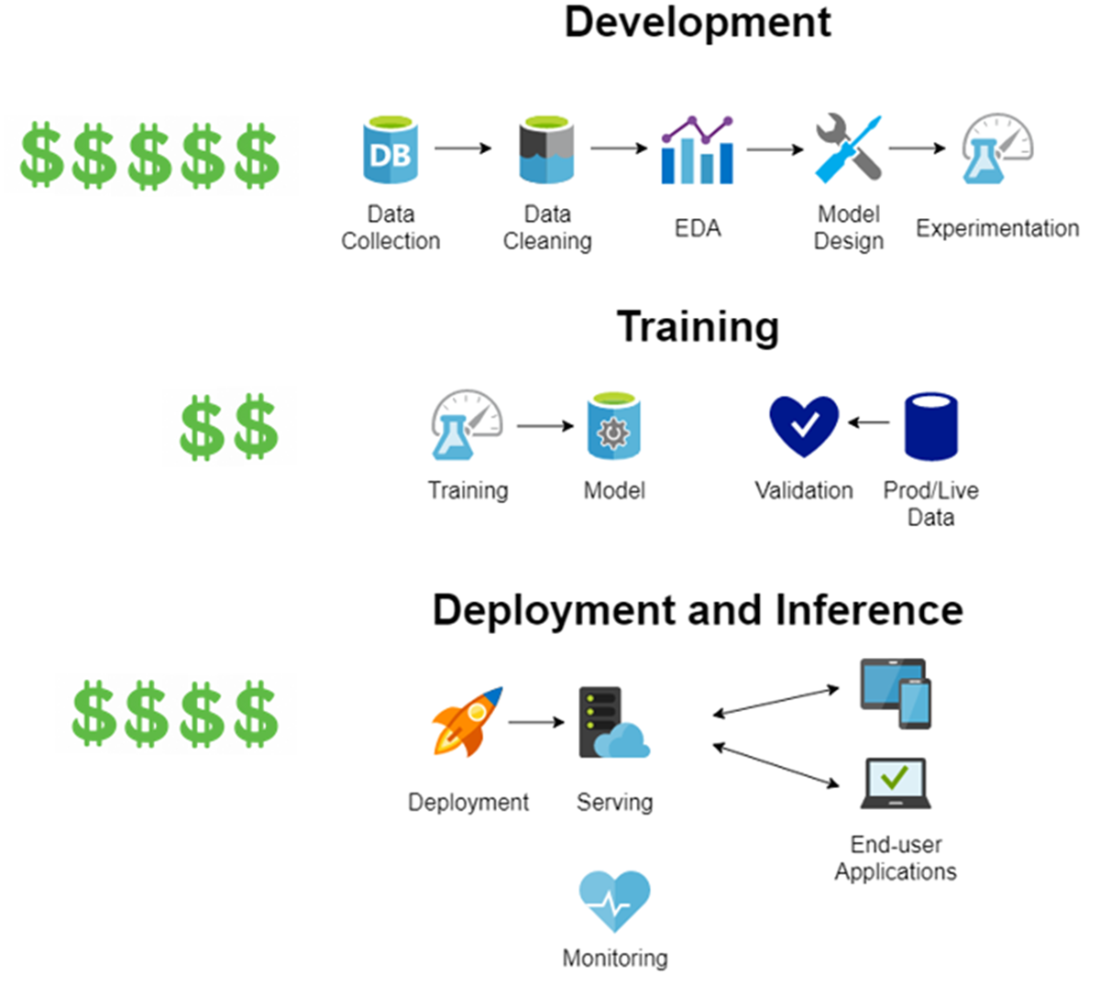
Order of magnitude of costs for each phase of LLM implementation from scratch.
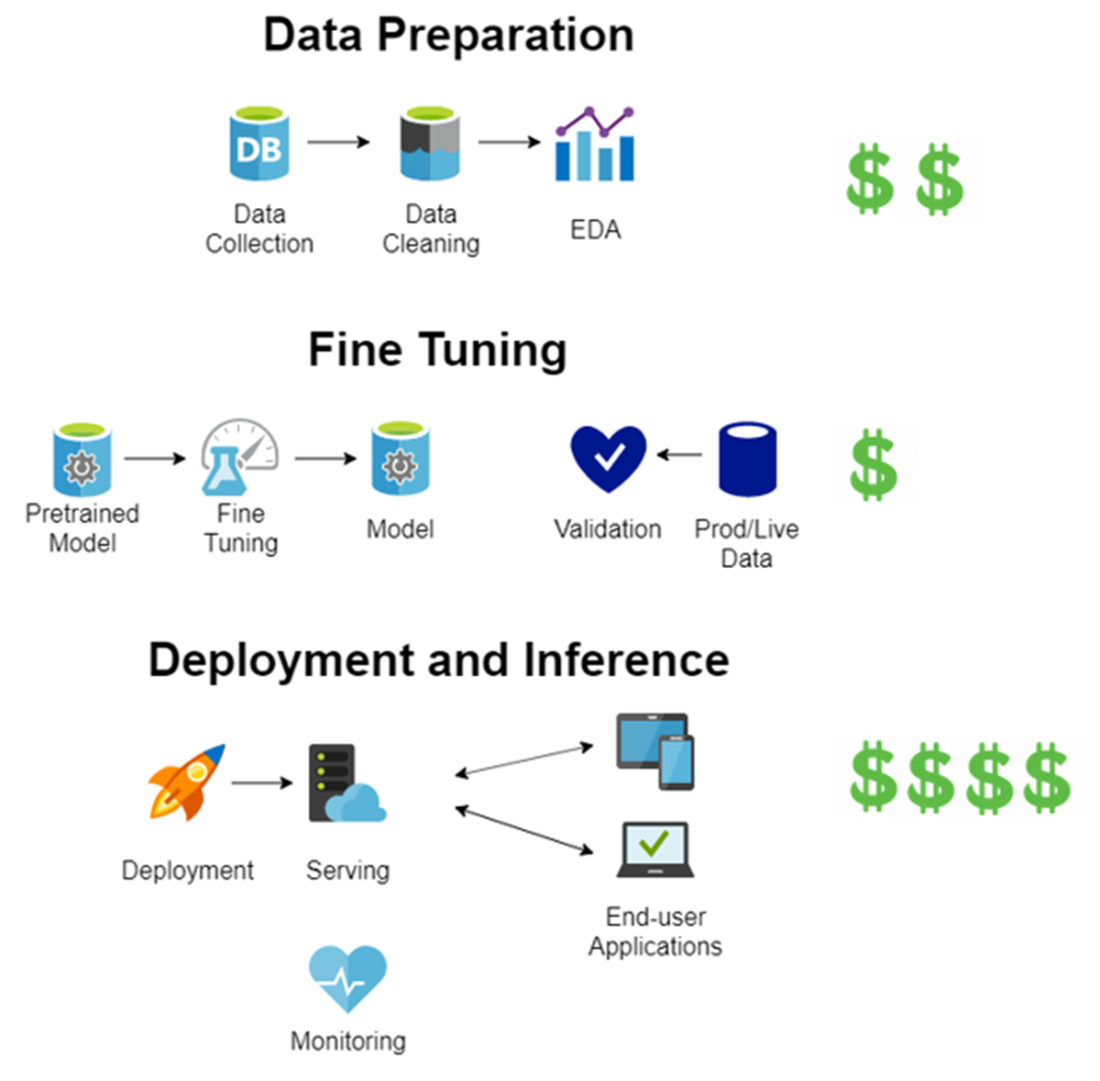
Order of magnitude of costs for each phase of LLM implementation when starting from a pretrained model.
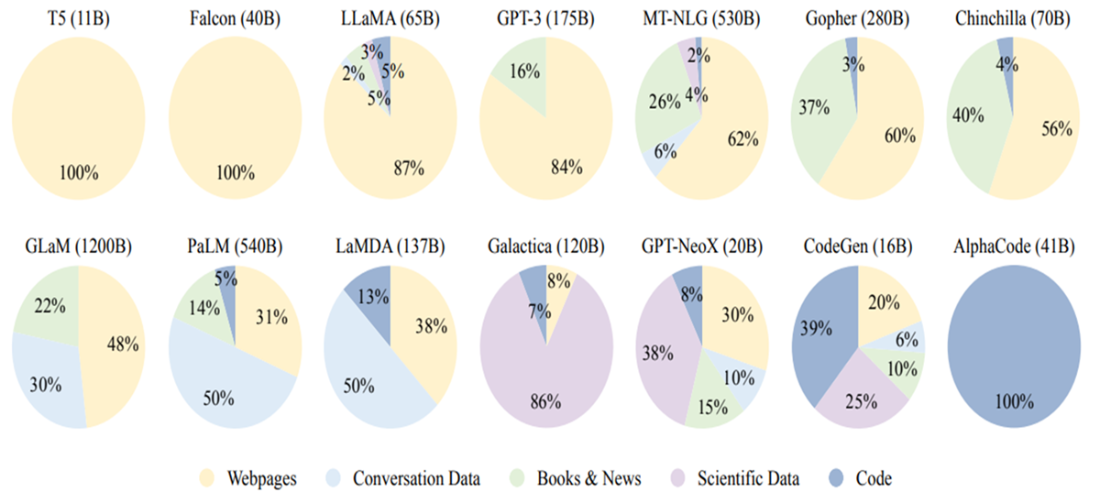
Ratios of data source types used to train some popular existing LLMs.
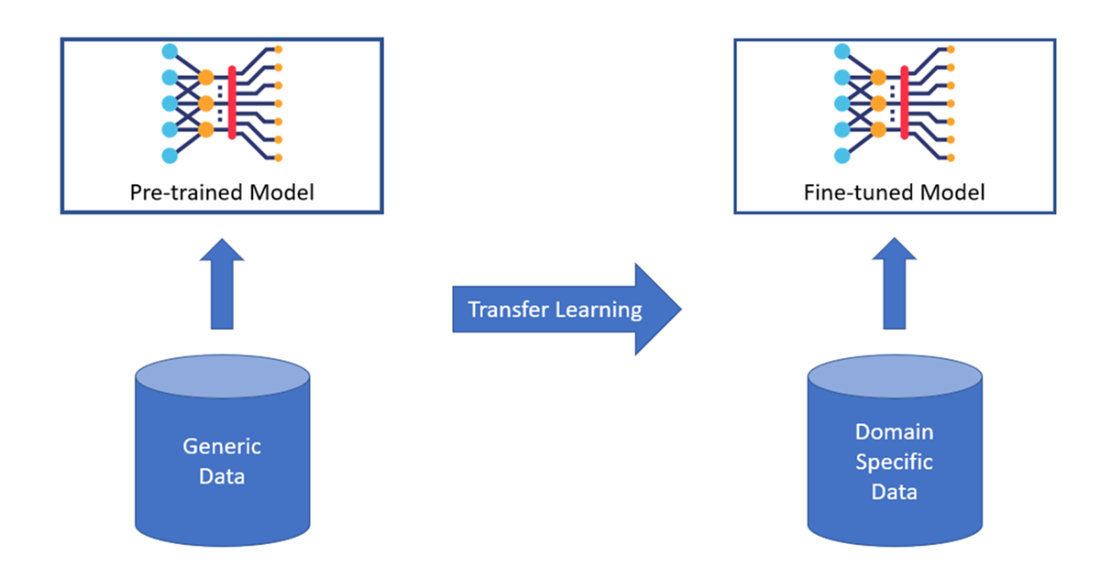
Generic model specialization to a given domain.
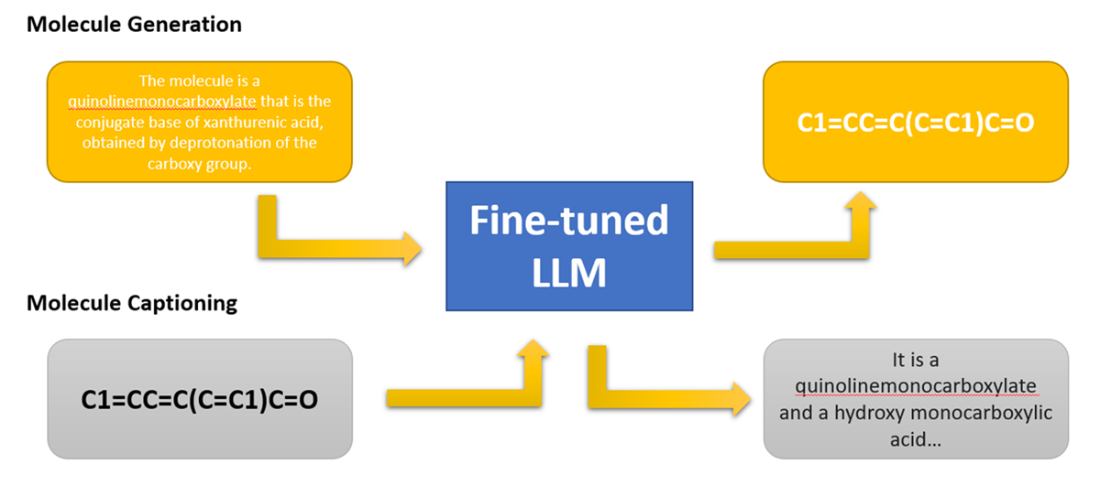
A LLM trained for tasks on molecule structures (generation and captioning).
Summary
- The definition of SLMs.
- Transformers use self-attention mechanisms to process entire text sequences at once instead of word by word.
- Self-supervised learning creates training labels automatically from text data without human annotation.
- BERT models use only the encoder part of Transformers for classification and prediction tasks.
- GPT models use only the decoder part of Transformers for text generation tasks.
- Word embeddings convert words into numerical vectors that capture semantic relationships.
- RLHF uses reinforcement learning to improve LLM responses based on human feedback.
- LLMs can generate any symbolic content including code, math expressions, and structured data.
- Open source LLMs reduce development costs by providing pre-trained models as starting points.
- Transfer learning adapts pre-trained models to specific domains using domain-specific data.
- Generalist LLMs risk data leakage when deployed outside organizational networks.
- Closed source models lack transparency about training data and model architecture.
- Domain-specific LLMs provide better accuracy for specialized tasks than generalist models.
- Smaller specialized models require less computational power than large generalist models.
- Fine-tuning costs significantly less than training models from scratch.
- Regulatory compliance often requires domain-specific models with known training data.
FAQ
What is a Small Language Model (SLM)?
A Small Language Model is a language model designed to perform natural language processing tasks like larger LLMs, but with fewer parameters, a smaller memory footprint, and lower computational requirements. SLMs typically range from a few hundred million to a few billion parameters, often below 10 billion, making them suitable for mobile devices, edge devices, on-prem servers, and small clusters.
How are SLMs different from Large Language Models (LLMs)?
SLMs and LLMs are based on the same core Transformer technology, so the difference is mainly scale rather than architecture. LLMs may contain hundreds of billions of parameters and require large infrastructure, while SLMs are optimized for efficiency, speed, lower energy use, and local deployment. SLMs are often better suited for focused, domain-specific, offline, privacy-sensitive, or resource-constrained use cases.
Why are SLMs useful for privacy-sensitive applications?
SLMs can run locally on devices, on-prem servers, or private infrastructure. This means sensitive or personal data does not need to leave the organization’s network. This is especially valuable in regulated industries such as healthcare, pharma, biotech, finance, manufacturing, and chemistry, where privacy and compliance are critical.
What role do SLMs play in Agentic AI?
SLMs are considered well suited for many invocations inside agentic systems because they are powerful enough for specific tasks, more economical, and easier to deploy than large general-purpose models. In heterogeneous agentic systems, agents may invoke multiple models, including both SLMs and LLMs, depending on the task requirements.
Why was the Transformer architecture important for language models?
The Transformer architecture introduced major improvements over earlier recurrent neural networks. It uses self-attention to process an entire input sequence at once and removes the recurrent structure, enabling greater parallelism and much faster training. This made it possible to train language models at larger scale on vast amounts of text.
What is self-supervised learning in language models?
Self-supervised learning generates labels programmatically from the data instead of relying on humans to label examples manually. For example, in a text completion task, the final word of a sentence can be removed and used as the label. The model learns by trying to predict the missing word and comparing its prediction with the original text.
What are BERT and GPT, and how do they differ?
BERT and GPT are two major Transformer-based model families. BERT, or Bidirectional Encoder Representations from Transformers, uses the encoder part of the Transformer and is typically strong for classification and prediction tasks. GPT, or Generative Pre-trained Transformer, uses the decoder part and is typically better suited for generative text tasks.
What tasks can language models perform beyond translation?
Language models can support many tasks beyond natural language translation, including language understanding, text classification, text generation, question answering, document summarization, semantic parsing, pattern recognition, basic math solving, code generation, dialogue, general knowledge tasks, and logical inference chains.
What are the main risks of closed source generalist LLMs?
Closed source generalist LLMs can be powerful and easy to use, but they introduce risks such as data leaving the organization’s network, potential data leakage, lack of transparency about training data, limited reproducibility and interpretability, hallucinations, hidden infrastructure or model changes, and the possibility of generating unsafe or malicious code if guardrails are bypassed.
When do domain-specific language models provide more business value than generalist LLMs?
Domain-specific models provide more value when tasks require specialized expertise, high accuracy, regulatory compliance, privacy protection, or strong understanding of domain context. They are especially useful when an organization has high-quality private domain data that can be used to specialize a pretrained model through transfer learning, fine-tuning, PEFT, RAG, or related techniques.
 Domain-Specific Small Language Models ebook for free
Domain-Specific Small Language Models ebook for free