5 What’s up with you, Directed Acyclic Word Graph?
This chapter tackles practical ways to store and search large word lists for exact membership and rapid prefix enumeration, problems that show up in autocomplete and word games. It frames the required operations with a simple interface and compares options: hash sets are excellent for membership tests but are essentially unusable for prefix queries, while sorted lists enable binary search with O(m log n) time but can still be costly per match and consume notable memory. To improve both speed and space, the chapter pursues data structures that share common substrings and highlights a key theoretical lens: the connection to finite state automata.
Tries address time performance by deduplicating prefixes: words are paths labeled by characters, with nodes marking word ends. They’re easy to build in O(mn) total time and support O(m) Contains and StartsWith, a clear win over sorted lists. However, naïve implementations are memory-hungry: many nodes, large per-node dictionary overhead, and vast numbers of redundant leaves and repeated suffixes in real lexicons. Viewing a trie as a deterministic finite-state automaton reveals that many nodes are equivalent; minimizing the automaton would remove them—ideally without first constructing a large, wasteful trie.
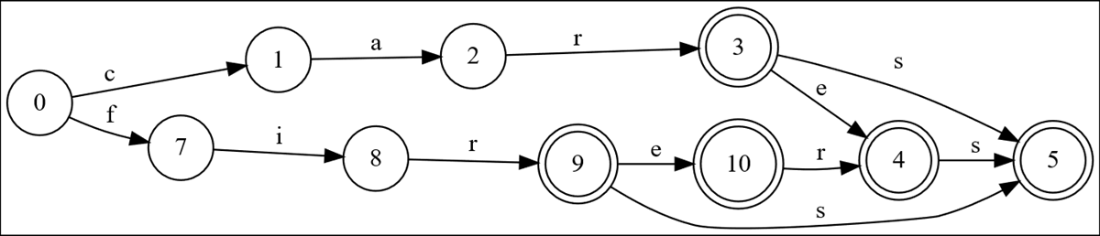
The solution is a Directed Acyclic Word Graph (DAWG), a minimal deterministic automaton that deduplicates both prefixes and suffixes. Using words in sorted order, the Daciuk–Watson–Watson algorithm incrementally maintains an almost-minimal graph by finding the common prefix with the previous word, recursively “fixing up” the previous word’s suffix with a canonical set of nodes and a structural equivalence test backed by a hash set, then appending the new suffix. The result preserves O(m) queries and achieves O(mn) construction while dramatically shrinking space in practice: for the ENABLE benchmark, nodes fall from about 388,000 in a trie to roughly 54,000 in a DAWG, with far fewer edges as well. Although object overhead still costs memory, DAWGs can be packed into tight byte arrays when needed, yielding an elegant, memory-efficient, high-performance approach to word-list search.
The trie for a nine-word list, laid out here left to right, and in alphabetical order from top to bottom. Node numbers are not data in the tree; they are just so we can refer to them in the discussion which follows. Double-circle nodes represent ends of words.
The trie for the word list “car”

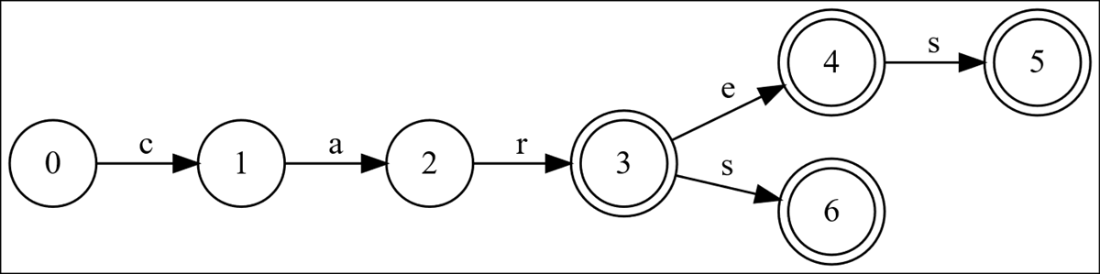
The trie for the word list “car”, “care”.

A trie with nine words: car, care, cares, cars, fir, fire, firer, firers, firs
Deduplicating all the leaves of the trie produces an equivalent word graph.
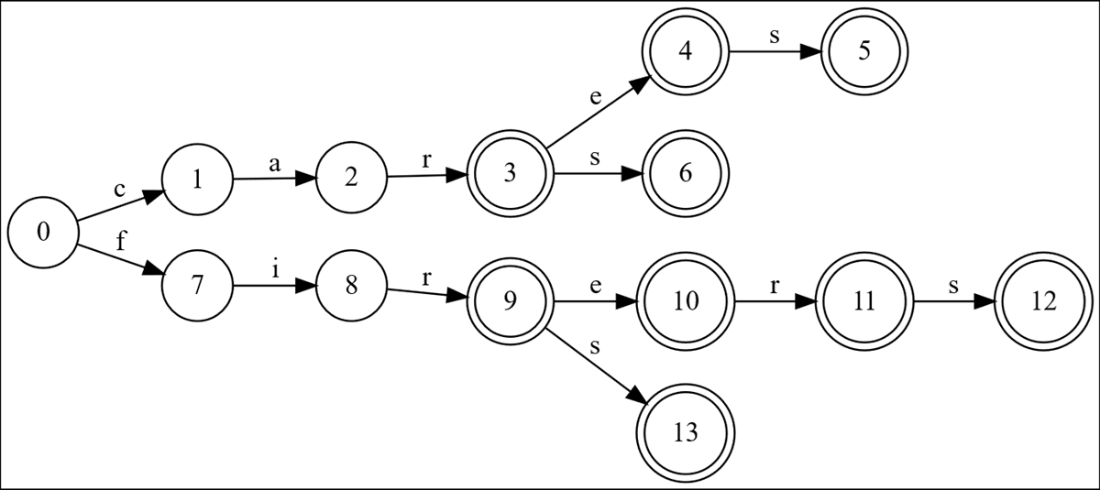
We’ve added car, care, cares and cars. The graph is optimized for everything except “cars”. Node 6 is identical to node 5, but node 6 is in “cars” so we have not fixed it yet.
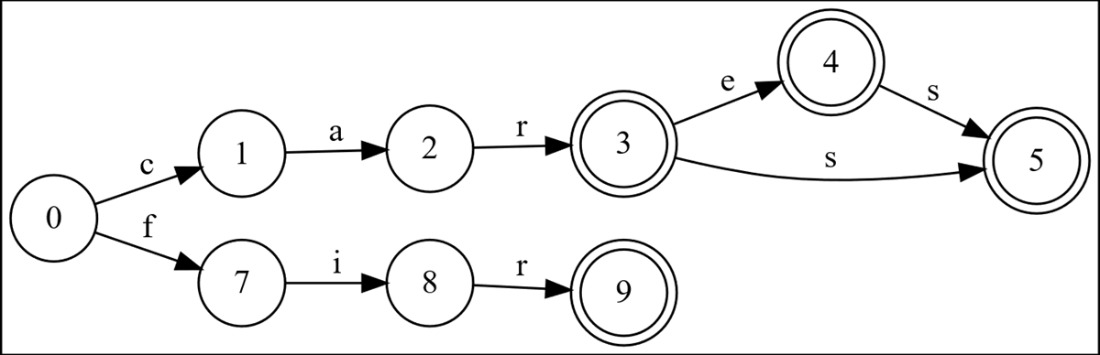
After adding “fir” the graph is optimized for every word except “fir”. State 9 could be replaced with state 5, so this graph is not optimized for the final word.
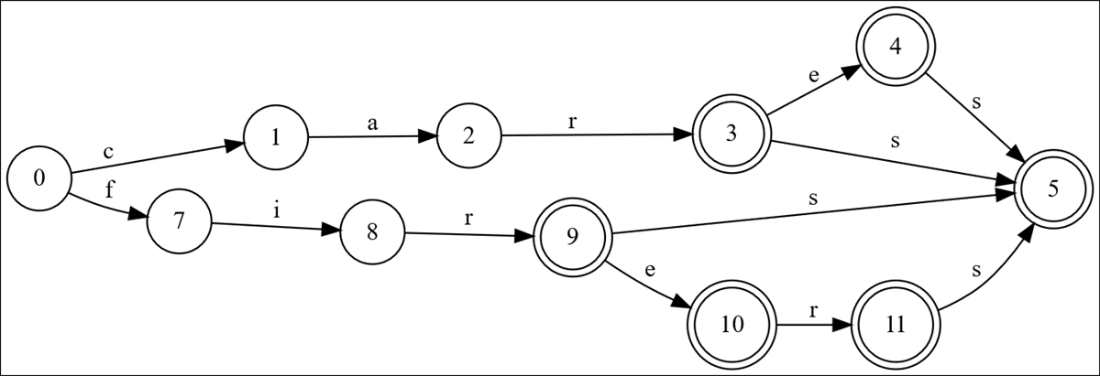
Do you notice something odd about this graph after adding “fire”?
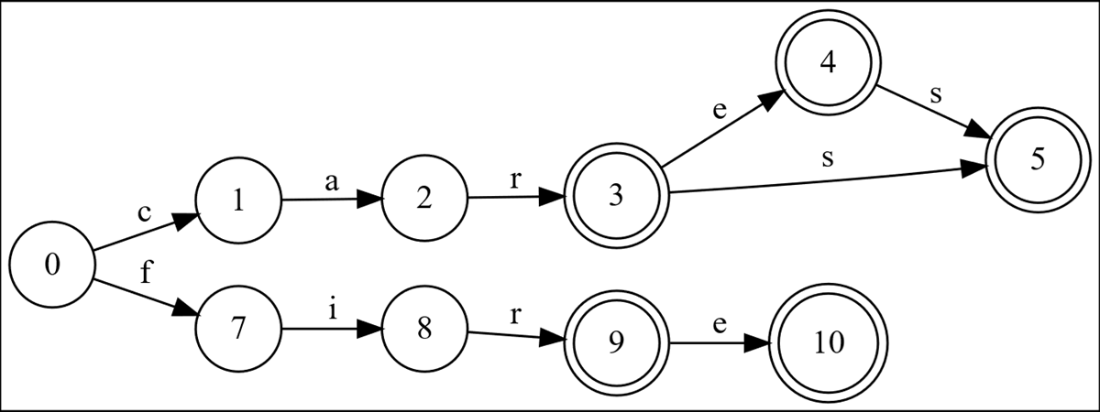
After adding “firer” and “firers”, the nodes for “firers” are still not optimized.
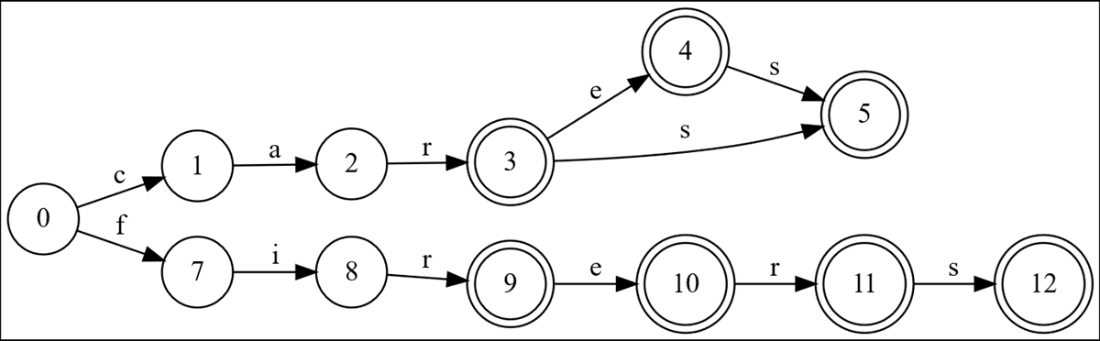
We look for optimizations moving backwards from the end of the previous word added, and first discover that node 12 is redundant; node 11 should have an edge to node 5 instead.
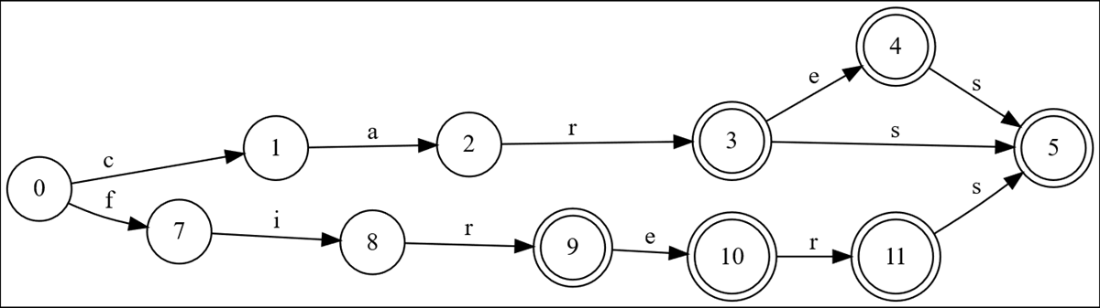
We’ve now fully optimized the “ers” portion of “firers” and we’re ready to add “firs”.

“firs” is added, and everything is optimized except for node 13, which is redundant to node 4.
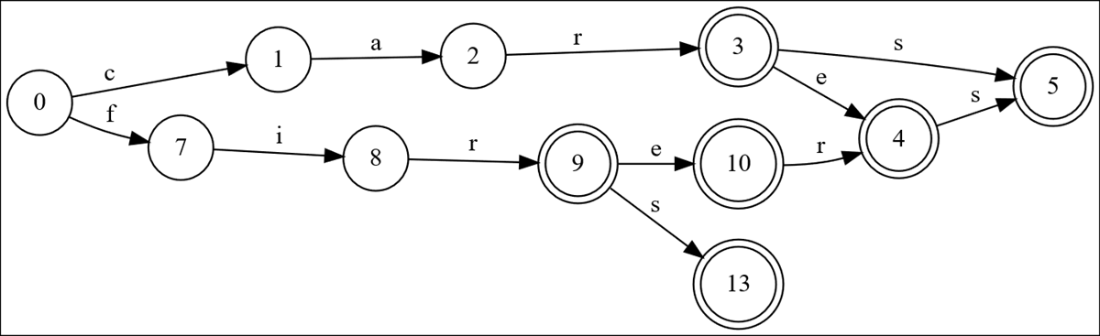
This is the smallest possible DAWG that represents those nine words.
Summing Up
- Storing n words of average length m in a list such that we can generate all the words matching a particular prefix is a common problem. The number of words can be very large.
- Hash sets are great at determining if a given word is contained in a set, but not at all good at generating completions given a prefix.
- We can get O(m log n) search performance by using binary search on a sorted list, which is probably acceptable -- but this solution uses a surprisingly large amount of memory if we use off-the-shelf parts.
- We can get O(m) search performance by using a trie to deduplicate prefixes, but the number of redundant nodes is potentially enormous.
- By noticing that tries are a special case of finite state automata, we could use any one of many algorithms that minimize FSAs without changing the language they recognize. But starting with the huge, space-inefficient trie in memory and running an expensive, difficult minimization algorithm is not great; what we really want is to build an optimized DAWG one word at a time.
- Efficiently detecting when two nodes are redundant and can be safely merged is a key sub-problem in graph minimization; if we are careful about not mutating a node after it is in the canonical set of optimized nodes, we can do so very efficiently.
- We can make DAWGs very small in memory if we need to; this is exactly what game developers did back in the day.
 Fabulous Adventures in Data Structures and Algorithms ebook for free
Fabulous Adventures in Data Structures and Algorithms ebook for free