1 Introduction to Bayesian statistics: Representing our knowledge and uncertainty with probabilities
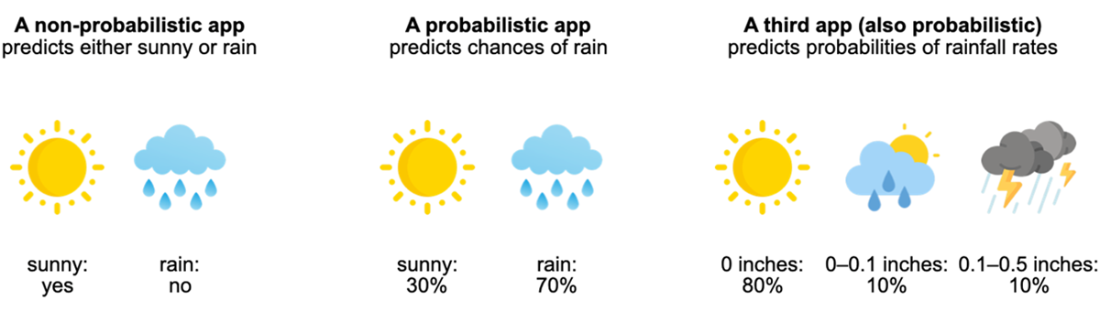
Bayesian statistics is introduced as a practical language for thinking and acting under uncertainty, from everyday choices like carrying an umbrella to high-stakes predictions in medicine and AI. The chapter motivates probability with a weather-forecast example, contrasting rigid yes/no outputs with probabilistic forecasts that reflect error margins and support decisions based on risk tolerance. Unknowns are modeled as random variables, with binary, categorical, or continuous forms offering different levels of granularity; choosing the right level balances usefulness with practicality. Concepts like expected value and cumulative probability help summarize beliefs quantitatively, and the chapter highlights how probabilistic reasoning guards against overconfident mistakes common in deterministic models, especially with small or noisy datasets.
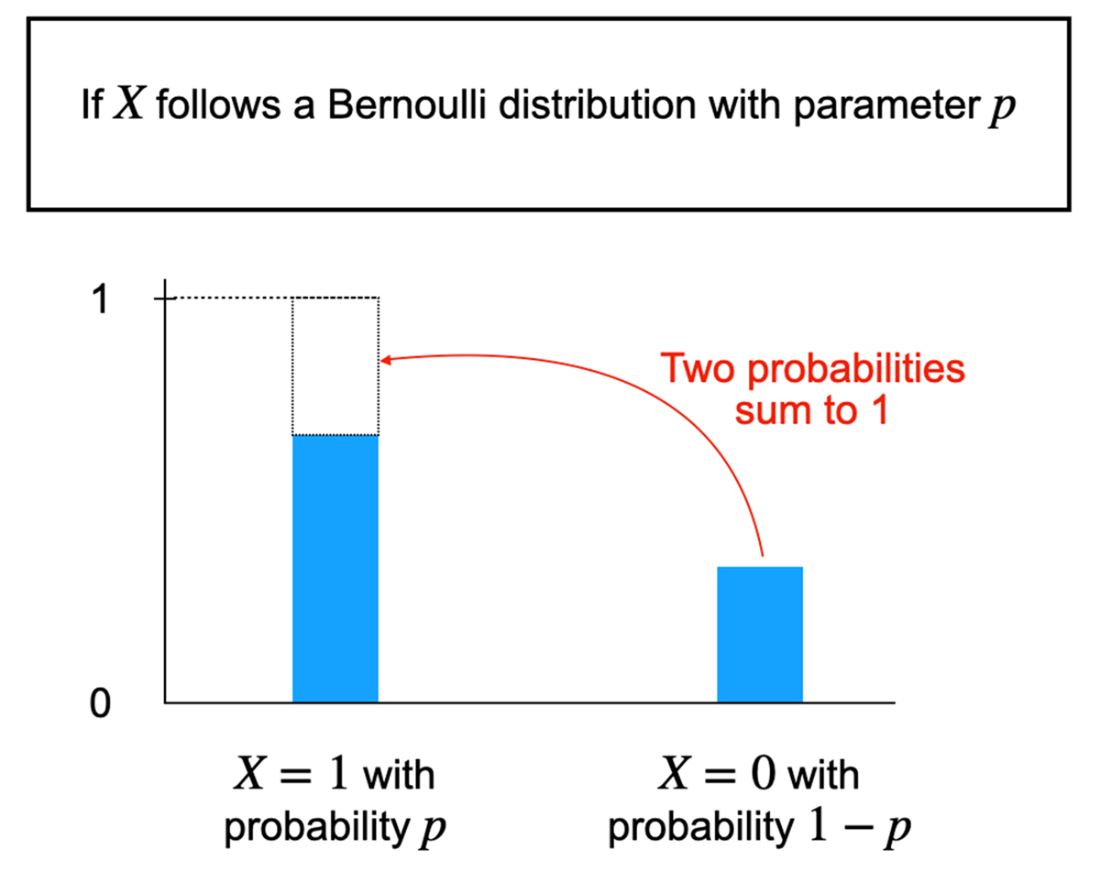
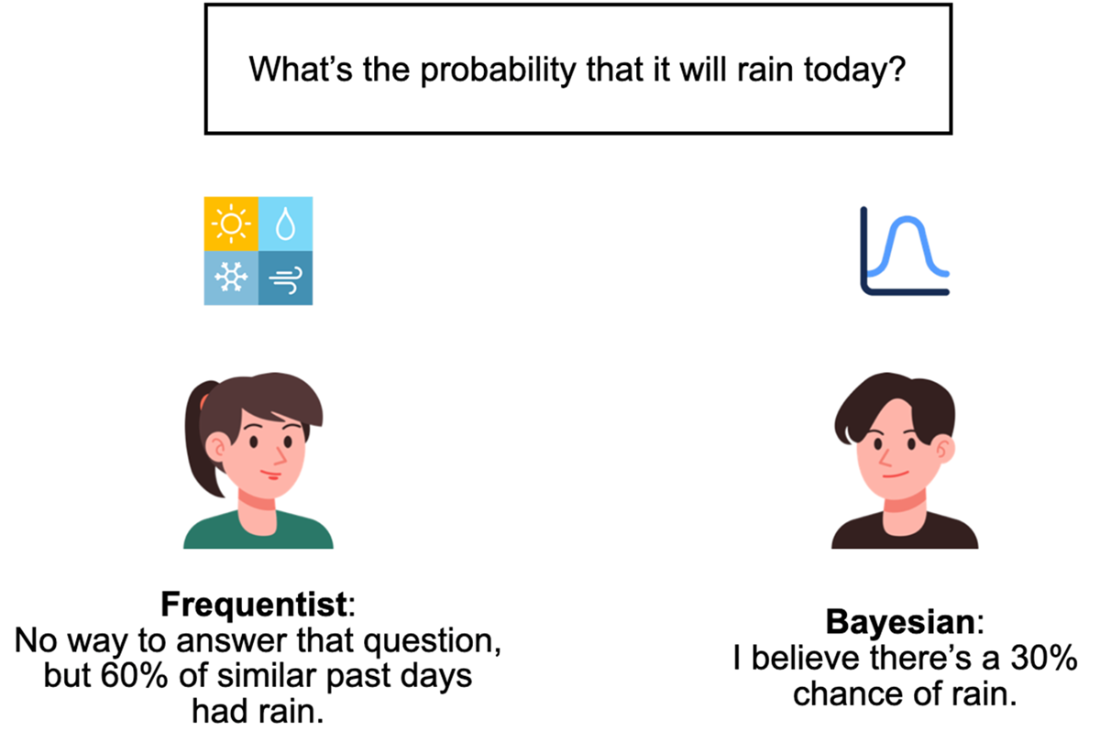
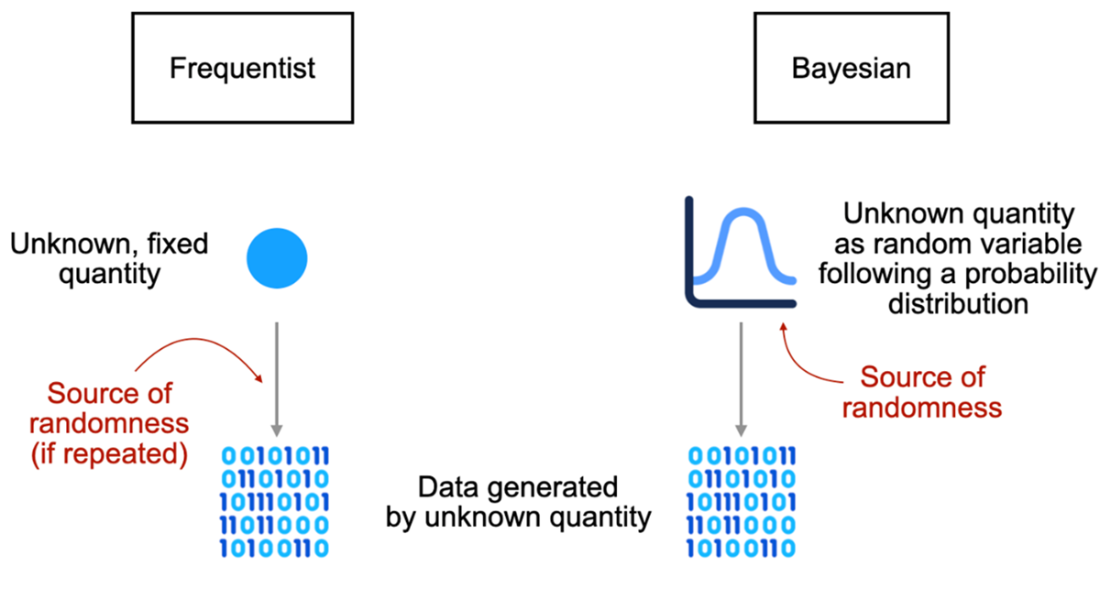
The Bayesian viewpoint treats probability as a degree of belief about unknown quantities, encoded by probability distributions with parameters (for example, a Bernoulli distribution with p for rain). Beliefs are updated by combining prior knowledge with observed data to produce a posterior distribution, a conditional probability that mirrors how people revise judgments in light of evidence. The chapter contrasts this with frequentism, where probability is the long-run frequency of outcomes under repeated trials, parameters are fixed, and randomness stems from data collection rather than ignorance. Frequentist tools are often simpler and data-driven, while Bayesian methods are flexible, transparent, and able to incorporate prior knowledge—differences that tend to narrow when data are abundant, but matter when data are scarce or decisions must reflect domain expertise.
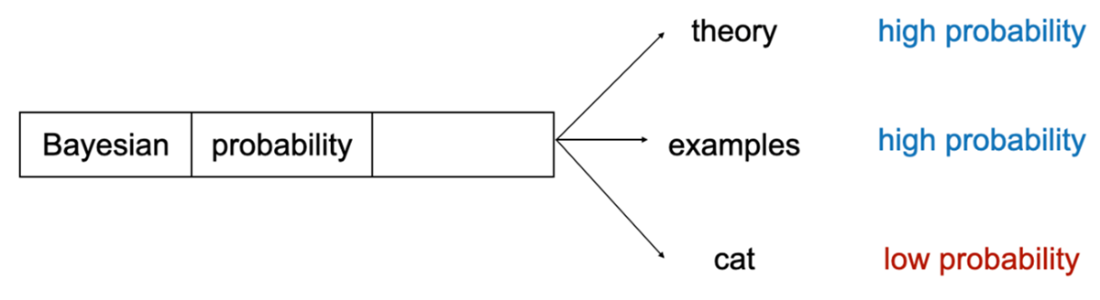
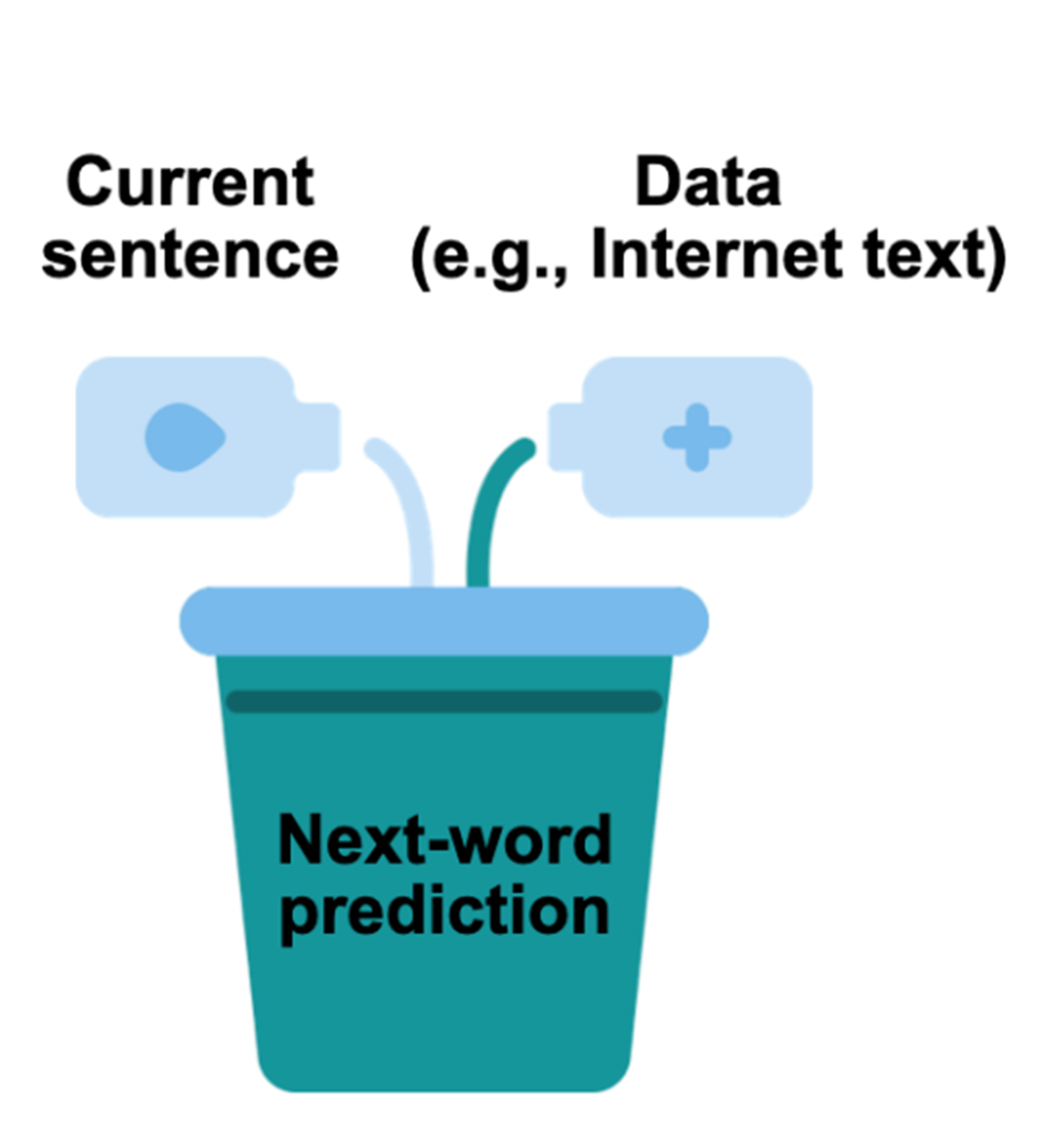
As a modern showcase, the chapter frames large language models as probabilistic next-word predictors that score candidate continuations using conditional probabilities. While inspired by Bayesian thinking, they are not fully Bayesian because computing complete posteriors over all words is intractable; instead, they approximate by focusing on likely candidates, and their probabilistic outputs enable generating multiple plausible responses and refining models via user feedback. The chapter closes by outlining the book’s trajectory: an intuitive foundation of priors, data, and posteriors; core tools such as model comparison, hierarchical and mixture models, Monte Carlo methods, and variational inference; specialized models for sequences and time series (like Kalman filters) and Bayesian neural networks; and finally Bayesian decision theory for making principled choices under uncertainty.
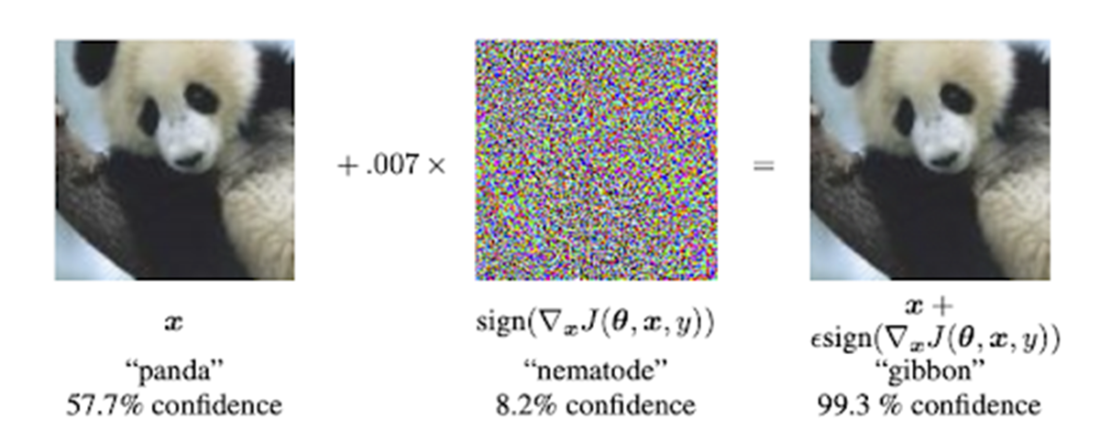
An illustration of machine learning models without probabilistic reasoning capabilities being susceptible to noise and overconfidently making the wrong predictions.
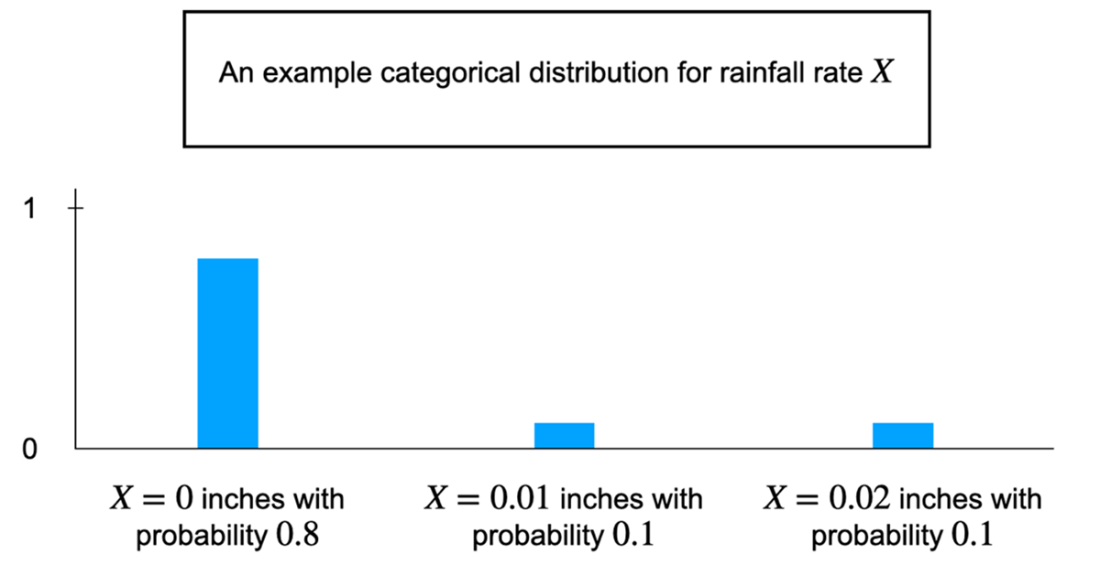
An example categorical distribution for rainfall rate.
Summary
We need probability to model phenomena in the real world whose outcomes we haven’t observed.
With Bayesian probability, we use probability to represent our personal belief about an unknown quantity, which we model using a random variable.
From a Bayesian belief about a quantity of interest, we can compute quantities that represent our knowledge and uncertainty about that quantity of interest.
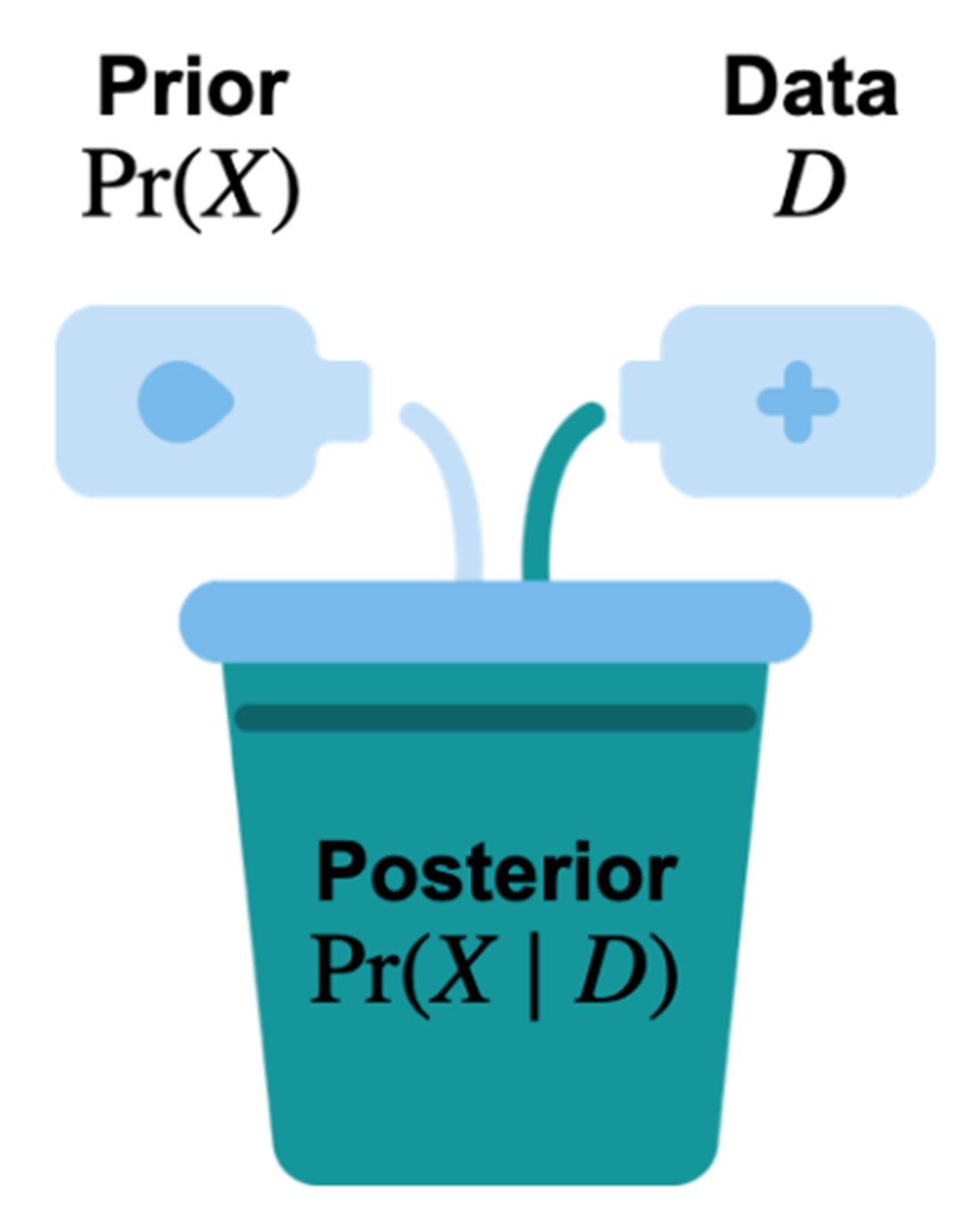
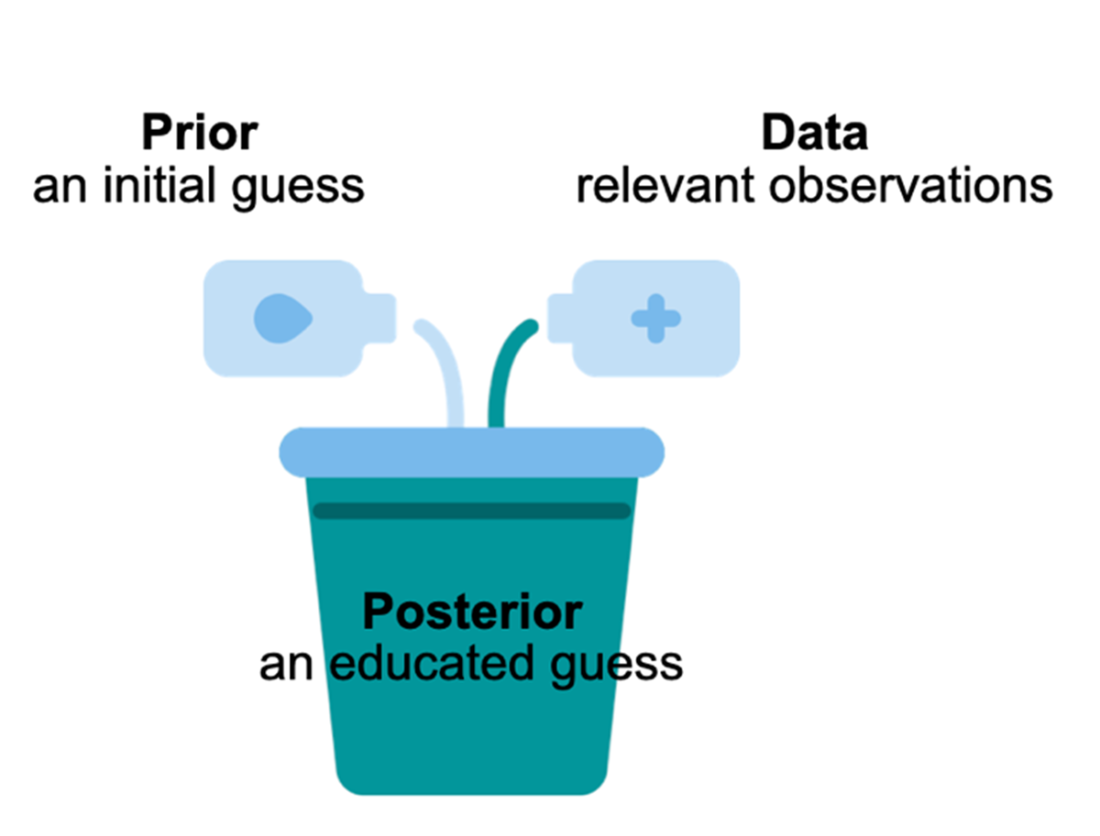
There are three main components to a Bayesian model: the prior distribution, the data, and the posterior distribution. The last component is the result of combining the first two and what we want out of a Bayesian model.
Bayesian probability is useful when we want to incorporate prior knowledge into a model, when data is limited, and for decision-making under uncertainty.
A different interpretation of probability, frequentism, views probability as the frequency of an event under infinite repeats, which limits the application of probability in various scenarios.
Large language models, which power popular chat artificial intelligence models, apply Bayesian probability to predict the next word in a sentence.
FAQ
Why is a probabilistic forecast more useful than a yes/no prediction?Because real-world predictions are uncertain. Probabilities communicate how likely outcomes are, letting different people make choices that match their risk tolerance. A yes/no app is just a thresholded version of a probabilistic model and throws away information that could guide better decisions.What is a random variable, and how do binary, categorical, and continuous variables differ?A random variable maps uncertain outcomes to numbers so we can reason with them. Binary variables take two values (for example, rain vs no rain). Categorical variables take one of several predefined values (for example, discretized rainfall amounts). Continuous variables can take any value in a range (for example, exact rainfall rate).How does Bayesian probability represent belief about an unknown?Bayesian probability treats the unknown quantity as a random variable with a probability distribution that encodes our degree of belief. For example, “will it rain today?” can be modeled with a Bernoulli distribution whose parameter p is our believed chance of rain. Distribution parameters control the shape of our belief and must satisfy probability rules (non-negativity and summing to 1).What are prior, data, and posterior in a Bayesian model?The prior captures our initial belief before observing evidence. The data are observations from the world. The posterior is our updated belief after combining the prior with the data, expressed as a conditional probability Pr(X | D). Chapter 2 formalizes how this update is computed.What is expected value and how should I interpret it?The expected value is the probability-weighted average of all possible outcomes. It summarizes the central tendency of a distribution but is not necessarily the most likely or typical realized value. Example: with 80% chance of 0, 10% of 0.01, and 10% of 0.02 inches/hour, the expected rainfall is 0×0.8 + 0.01×0.1 + 0.02×0.1 = 0.003.What does “granularity of reasoning” mean in probabilistic modeling?It’s the level of detail in how we model outcomes. A binary variable answers “rain or not,” a categorical variable lists discrete rainfall amounts, and a continuous variable models exact amounts. More granularity adds usefulness and trust but can increase complexity; the goal is a practical balance.How do Bayesian and frequentist interpretations of probability differ?Bayesians interpret probability as degrees of belief about unknowns and update those beliefs with data. Frequentists tie probability to long-run frequencies from repeatable experiments, treating the unknown as fixed and the data-generating process as random. Both approaches can yield similar answers when data are abundant, but they reason differently.When should I use Bayesian vs frequentist methods?Bayesian methods shine when data are limited, when you have meaningful prior knowledge to incorporate, or when you need customized decision analysis. Frequentist methods are convenient when data are abundant, objectives match standard tools (like hypothesis testing or A/B tests), and you want lighter computation and diagnostics.Are neural network confidence scores true probabilities?Not by default. The commonly used softmax outputs in classifiers are normalized scores that sum to 1, but they are often poorly calibrated and shouldn’t be interpreted as true probabilities without additional probabilistic modeling or calibration.How do large language models reflect Bayesian ideas?LLMs perform next-word prediction using conditional probabilities given context and training data, a Bayesian-flavored framing. They aren’t fully Bayesian because computing full posteriors over all vocabulary is intractable, so they approximate by focusing on the most likely candidates. Sampling multiple likely continuations supports user feedback and iterative refinement.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!

 Grokking Bayes ebook for free
Grokking Bayes ebook for free