1 Large language models: The foundation of generative AI
Large language models (LLMs) burst into public view with ChatGPT’s 2022 debut, revealing how far natural language technology had come and why it matters. This chapter traces the field’s arc from early rule-based and statistical systems to neural networks, culminating in the transformer architecture and the attention mechanism that enabled today’s scale. Pretrained on massive unlabeled text and then adapted to tasks via fine-tuning, models like GPT and BERT turned LLMs into general-purpose engines for language, igniting both excitement about their potential and concern about their societal impact.
Under the hood, LLMs tokenize text, build contextual representations with self-attention, and learn through self-supervised objectives that predict hidden or next tokens; they can then be refined for specific uses or paired with reinforcement learning. This training recipe powers a wide array of applications: dialogue and assistance, question answering (extractive, open-book, and closed-book), coding support and code generation, content creation, translation, summarization, and emerging forms of mathematical and scientific reasoning. Rapid innovation has expanded capabilities into multimodal settings (text, images, audio, video) and ushered LLMs into everyday tools across consumer and enterprise workflows.
The chapter also examines hard problems and the competitive landscape. Training data can import social biases and harmful content; model outputs can “hallucinate” convincing but false claims; and the compute, cost, and energy demands raise sustainability and access concerns. Meanwhile, industry strategies diverge: OpenAI’s fast-paced releases and Microsoft integration; Google’s foundational research and cautious deployment; Meta’s open-weight Llama models; Anthropic’s safety-first “Constitutional AI”; and a widening field that includes DeepSeek, Mistral, Cohere, Perplexity, xAI, Midjourney, Stability, and Runway. Together, these themes equip readers to cut through hype, recognize both capabilities and limits, and approach LLMs with a pragmatic, responsible mindset.
The reinforcement learning cycle
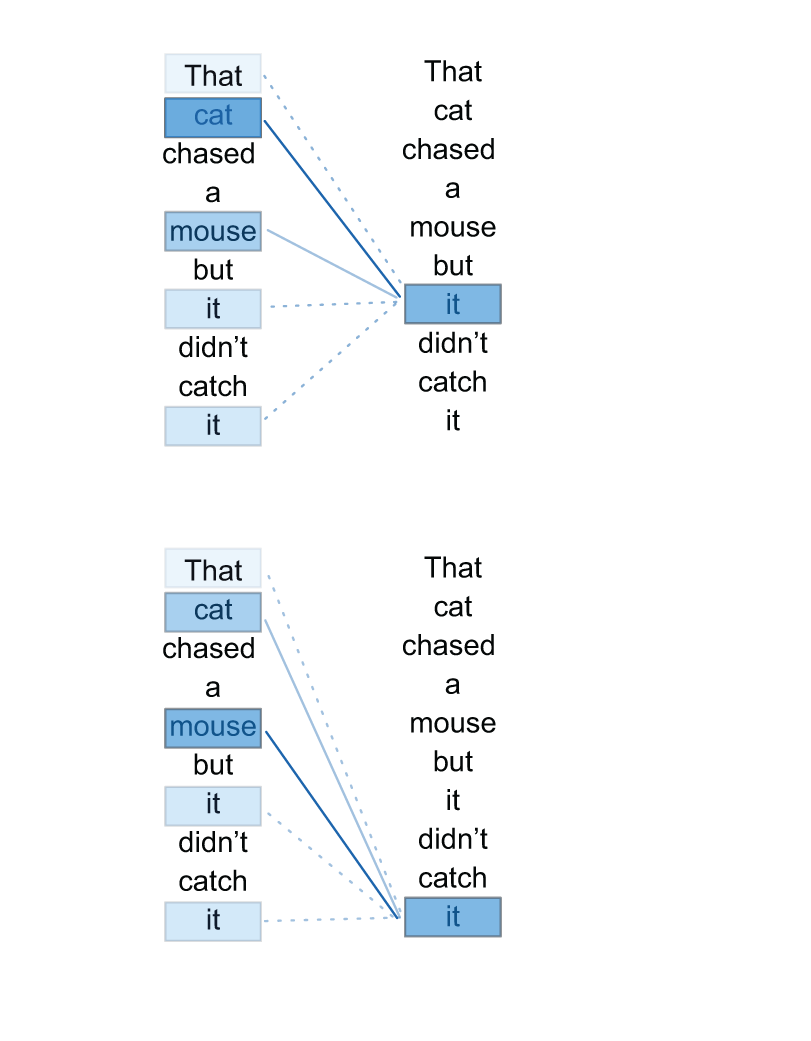
The distribution of attention for the word “it” in different contexts.
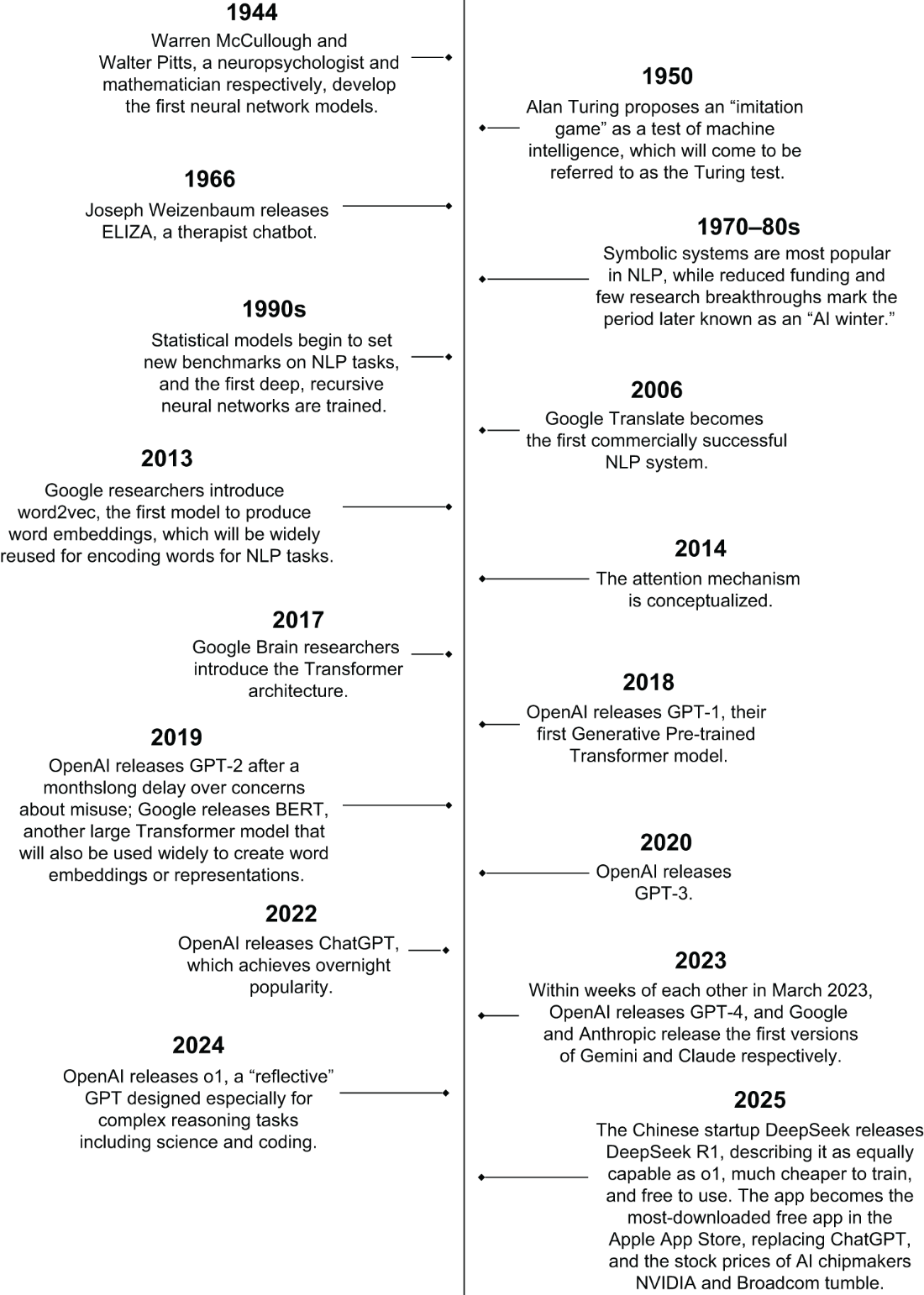
A timeline of breakthrough events in NLP.
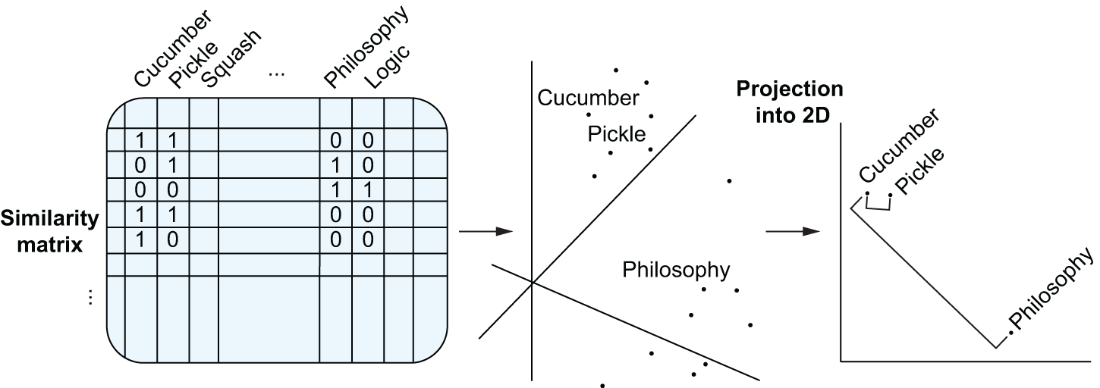
Representation of word embeddings in the vector space
Summary
The history of NLP is as old as computers themselves. The first application that sparked interest in NLP was machine translation in the 1950s, which was also the first commercial application released by Google in 2006.
Transformer models and the debut of the attention mechanism were the biggest NLP breakthroughs of the decade. The attention mechanism attempts to mimic attention in the human brain by placing “importance” on the most relevant information.
The boom in NLP from the late 2010s to early 2020s is due to the increasing availability of text data from around the internet and the development of powerful computational resources. This marked the beginning of the LLM.
Today’s LLMs are trained primarily with self-supervised learning on large volumes of text from the web and are then fine-tuned with reinforcement learning.
GPT, released by OpenAI, was one of the first general-purpose LLMs designed for use with any natural language task. These models can be fine-tuned for specific tasks and are especially well-suited for text-generation applications, such as chatbots.
LLMs are versatile and can be applied to various applications and use cases, including text generation, answering questions, coding, logical reasoning, content generation, and more. Of course, there are also inherent risks, such as encoding bias, hallucinations, and emission of sizable carbon footprints.
In January 2023, OpenAI’s ChatGPT set a record for the fastest-growing user base in history and set off an AI arms race in the tech industry to develop and release LLM-based conversational dialogue agents. As of 2025, the most significant LLMs have come from OpenAI, Google, Meta, Microsoft, and Anthropic.
FAQ
What are large language models (LLMs)?LLMs are transformer-based neural networks trained on massive text corpora to predict the next token in context (self-supervised learning). They learn general language patterns that let them generate, summarize, translate, and reason about text. ChatGPT is an LLM optimized for dialogue; other LLMs are tuned for different tasks.How did NLP evolve to today’s LLMs?NLP progressed from brittle rule-based systems (e.g., ELIZA) to data-driven statistical methods in the 1990s, then to deep neural networks. The 2017 transformer architecture, powered by attention, enabled training on far larger datasets. Models like BERT and GPT popularized pretraining on unlabeled text followed by task-specific adaptation, culminating in systems like ChatGPT.What is a transformer, and why is attention important?Transformers use self-attention to weigh relationships among all tokens in a sequence, capturing long-range dependencies without step-by-step recurrence. This design is highly parallelizable and efficient, delivering state-of-the-art results and enabling today’s large-scale language modeling.How are LLMs trained and adapted to new tasks?They are pretrained via self-supervised objectives (e.g., next-token prediction or masked tokens) on vast unlabeled text to learn general language representations. They can then be fine-tuned on smaller, labeled datasets for specific tasks, and sometimes refined with reinforcement learning to encourage desirable behaviors.What can LLMs do in practice?Common uses include conversation and text generation, question answering (extractive, open-book, and closed-book), translation, summarization, grammar correction, coding assistance, and elements of logical and common-sense reasoning. Their generality lets one model support many applications.How do LLMs handle question answering?Three main styles are used: extractive QA (pull the answer from provided context), open-book generative QA (generate an answer using provided context), and closed-book generative QA (answer from learned knowledge without external context). Reading comprehension benchmarks test these abilities in varied formats.How are LLMs used for coding?Code models turn natural-language prompts into code, autocomplete snippets, and suggest alternatives (e.g., GitHub Copilot based on Codex). Newer reasoning-focused models greatly improve on programming benchmarks, though fully autonomous “AI engineers” remain unreliable and require human oversight.Where do LLMs fall short?Key issues include bias inherited from training data, hallucinations (fluent but incorrect outputs), and environmental and resource costs of training and inference. These challenges affect safety, reliability, and access, and remain active areas of research and policy.What causes bias and hallucinations in LLMs?Bias arises when training data reflect societal stereotypes or skewed distributions, leading to disparate outputs across identity attributes. Hallucinations occur because models generate likely text patterns rather than grounded facts, producing confident but false statements—especially in unfamiliar contexts.Who are the major players in generative AI, and how do they differ?OpenAI (rapid multimodal releases; Microsoft partnership), Google (Gemini; DeepMind; emphasis on AI principles), Meta (open-access Llama models), Microsoft (Copilot integrations across products), and Anthropic (safety-focused Claude, Constitutional AI) lead the field. Others include DeepSeek (efficient MoE models), Cohere (enterprise focus), Perplexity (AI search with citations), Mistral (efficient open models), xAI (Grok), Stability AI, Midjourney, and Runway in image/video.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!

 Introduction to Generative AI, Second Edition ebook for free
Introduction to Generative AI, Second Edition ebook for free