1 Getting to know Kafka as an architect
Kafka for Architects opens by positioning Kafka as a foundation for modern, event-driven systems, explaining why architects must think beyond running clusters to designing for decoupling, resilience, and long-term sustainability. The chapter introduces the principles of event-driven architecture, the publish-subscribe model, and Kafka’s log-centric design, and it frames where Kafka excels—high-throughput pipelines, real-time analytics, and enterprise integration. It also outlines the broader ecosystem and the kinds of strategic tradeoffs architects will face when deciding how and when to apply Kafka.
The text contrasts traditional synchronous, request-response integrations with event-driven patterns that favor autonomy, low latency, and fan-out, while acknowledging new responsibilities around eventual consistency, ordering, and idempotency. It summarizes Kafka’s core building blocks—producers, brokers, and consumers; durable storage with replication; acknowledgments and replay; and controllers managing cluster metadata—to show how reliability and scalability are achieved. These concepts are tied to real-world needs such as fraud detection, recommendations, and telemetry, where massive volumes and near-real-time processing make Kafka a compelling choice.
Design and operations receive equal emphasis: schemas act as data contracts managed externally via Schema Registry; Kafka Connect moves data between systems through configuration rather than custom code; and stream processing frameworks (e.g., Kafka Streams, Flink) transform, enrich, and route events in motion. The chapter highlights operational concerns—sizing, monitoring, security, disaster recovery, and the on-premises versus managed-service decision—then discusses two primary usage modes: durable event delivery and long-retention logs that enable event sourcing and state reconstruction, while noting why Kafka does not replace databases. It closes by distilling what makes Kafka different: its immutable, replicated commit log, ecosystem breadth, and suitability as a scalable, reliable backbone for data-centric architectures.
Request-response design pattern

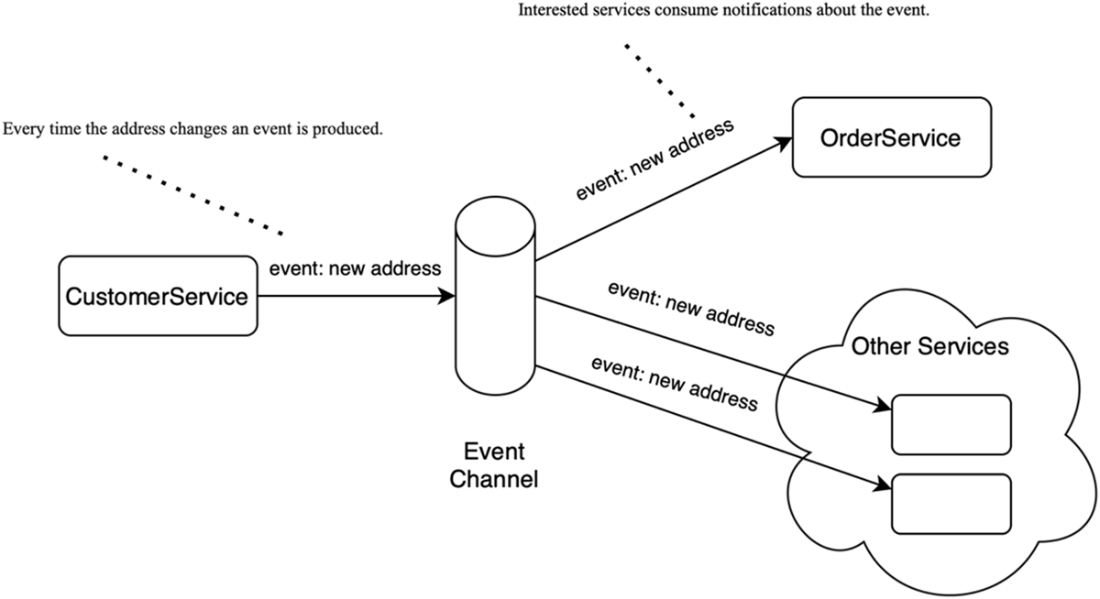
The EDA style of communication: systems communicate by publishing events that describe changes, allowing others to react asynchronously.
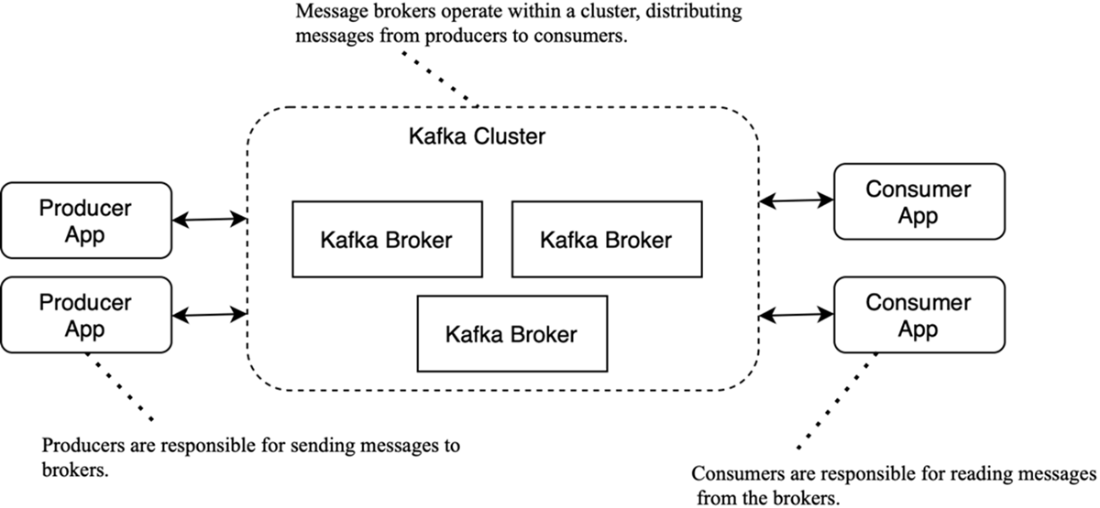
The key components in the Kafka ecosystem are producers, brokers, and consumers.
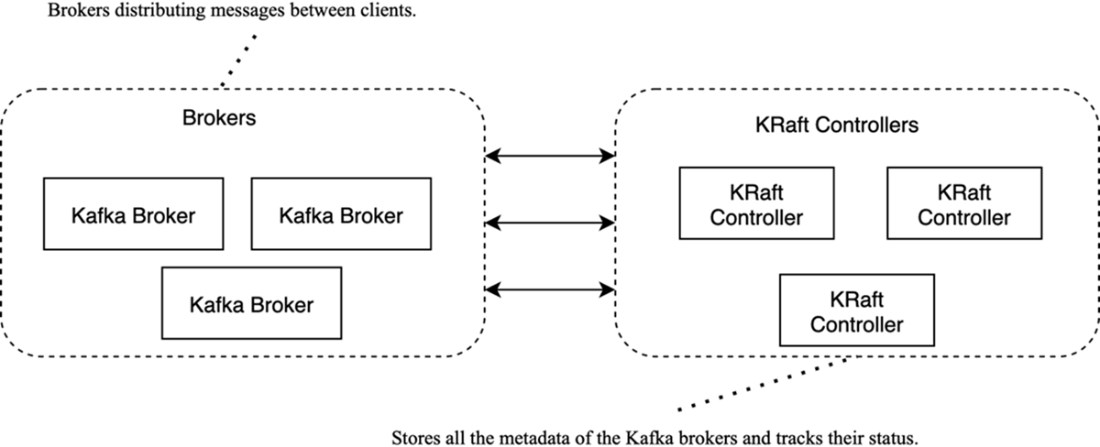
Structure of a Kafka cluster: brokers handle client traffic; KRaft controllers manage metadata and coordination
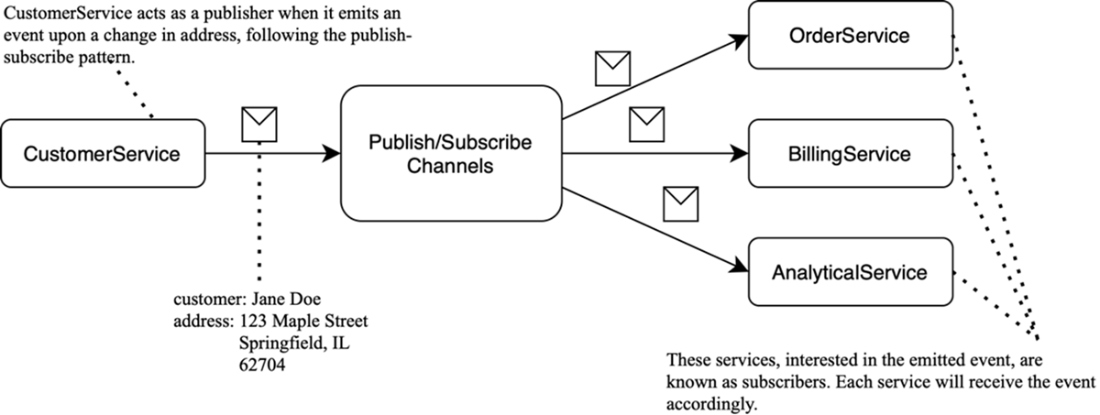
Publish-subscribe example: CustomerService publishes a “customer updated” event to a channel; all subscribers receive it independently.
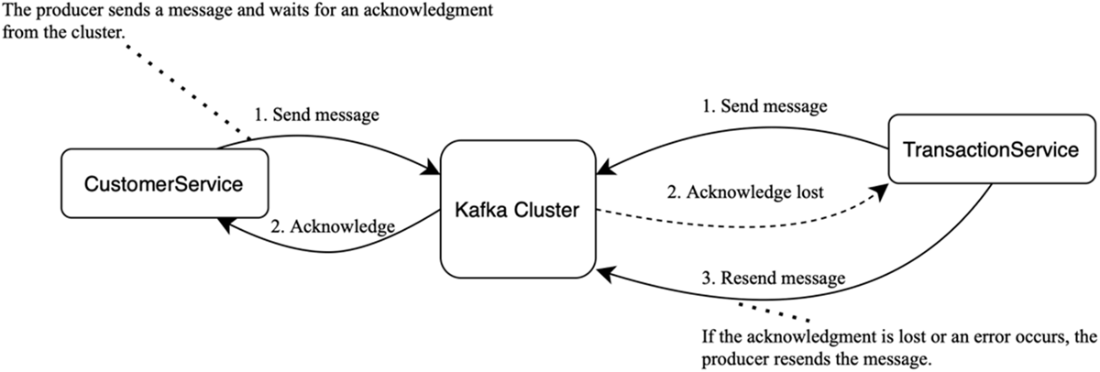
Acknowledgments: Once the cluster accepts a message, it sends an acknowledgement to the service. If no acknowledgment arrives within the timeout, the service treats the send as failed and retries.
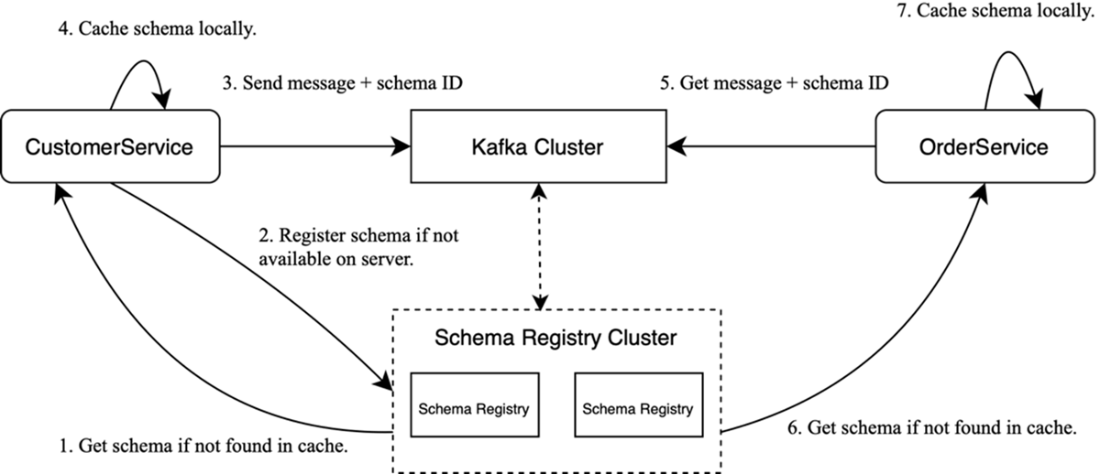
Working with Schema Registry: Schemas are managed by a separate Schema Registry cluster; messages carry only a schema ID, which clients use to fetch (and cache) the writer schema.
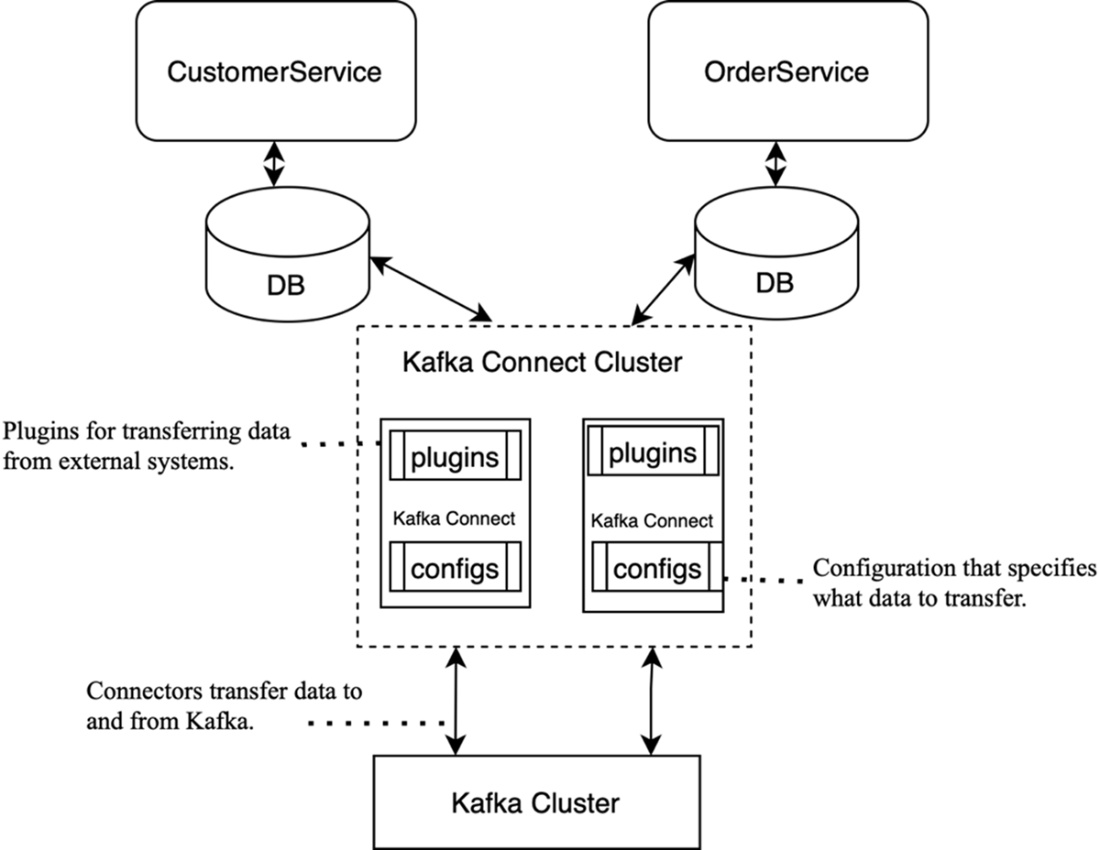
The Kafka Connect architecture: connectors integrate Kafka with external systems, moving data in and out.
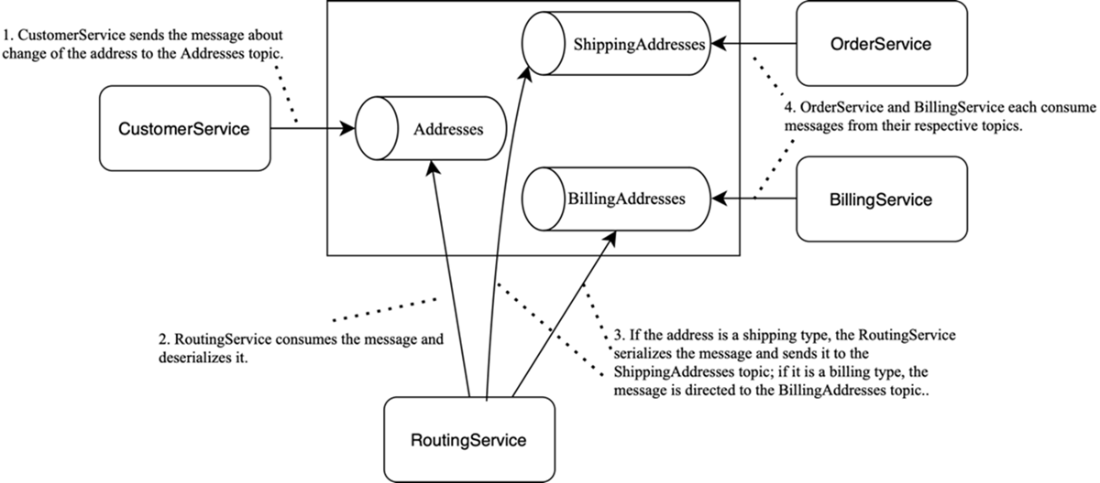
An example of a streaming application. RoutingService implements content-based routing, consuming messages from Addresses and, based on their contents (e.g., address type), publishing them to ShippingAddresses or BillingAddresses.
Summary
- There are two primary communication patterns between services: request-response and event-driven architecture.
- In the event-driven approach, services communicate by triggering events.
- The key components of the Kafka ecosystem include brokers, producers, consumers, Schema Registry, Kafka Connect, and streaming applications.
- Cluster metadata management is handled by KRaft controllers.
- Kafka is versatile and well-suited for various industries and use cases, including real-time data processing, log aggregation, and microservices communication.
- Kafka components can be deployed both on-premises and in the cloud.
- The platform supports two main use cases: message delivery and state storage.
 Kafka for Architects ebook for free
Kafka for Architects ebook for free