Generative AI has surged into mainstream attention by creating new content—text, images, audio, code—rather than merely classifying existing data. This chapter sets the stage by contrasting generative and discriminative approaches, framing generative models as systems that learn data distributions to synthesize novel samples. It also motivates why learning to build these systems from the ground up matters: a transparent understanding leads to better results, practical control over outputs, and more responsible use. Python and PyTorch are introduced as the practical toolkit for this journey thanks to readable syntax, broad community support, dynamic computation graphs, and fast GPU training.
Two model families anchor the chapter. GANs pit a generator against a discriminator in an iterative contest, yielding increasingly realistic outputs and enabling powerful tasks like domain translation. Transformers address sequence problems with self-attention, capturing long-range dependencies while enabling parallel training—key to modern large language models and multimodal systems. The narrative connects these ideas to statistical foundations (conditional vs joint distributions), surveys Transformer variants (encoder-only, decoder-only, encoder–decoder), and highlights diffusion models and their role in text-to-image generation through progressive denoising and iterative refinement.
Beyond concepts, the chapter outlines a hands-on path: setting up Python and PyTorch, learning tensors, and completing an end-to-end project before building generative models from scratch. Readers implement GANs (including DCGAN and CycleGAN) and core Transformer components, explore smaller-scale language modeling, and leverage pretrained weights and transfer learning where training from scratch is impractical. Throughout, the chapter emphasizes practical benefits—controlling attributes of generated outputs, adapting models to downstream tasks—and encourages an informed perspective on the technology’s disruptive potential and risks, laying a solid foundation for the rest of the book.
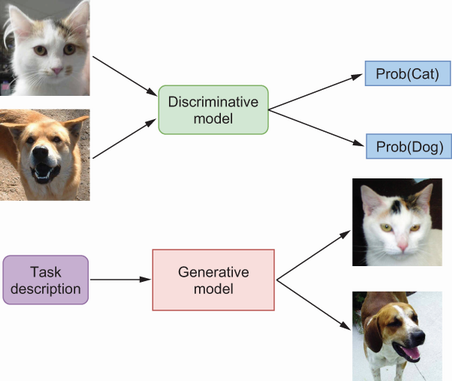
A comparison of generative models versus discriminative models. A discriminative model (top half of the figure) takes data as inputs and produces probabilities of different labels, which we denote by Prob(dog) and Prob(cat). In contrast, a generative model (bottom half) acquires an in-depth understanding of the defining characteristics of these images to synthesize new images representing dogs and cats.
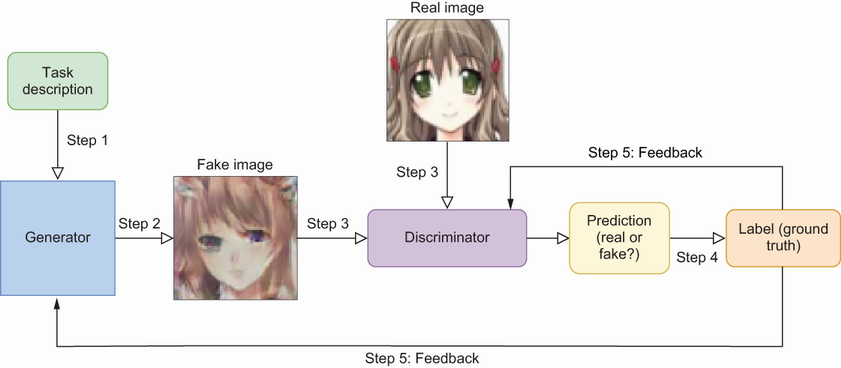
GANs architecture and its components. GANs employ a dual-network architecture comprising a generative model (left) tasked with capturing the underlying data distribution and a discriminative model (center) that serves to estimate the likelihood that a given sample originates from the authentic training dataset (considered as “real”) rather than being a product of the generative model (considered as “fake”).
Examples from the anime faces training dataset

Generated anime face images by the trained generator in DCGAN

Changing hair color with CycleGAN. If we feed images with blond hair (first row) to a trained CycleGAN model, the model converts blond hair to black hair in these images (second row). The same trained model can also convert black hair (third row) to blond hair (bottom row).

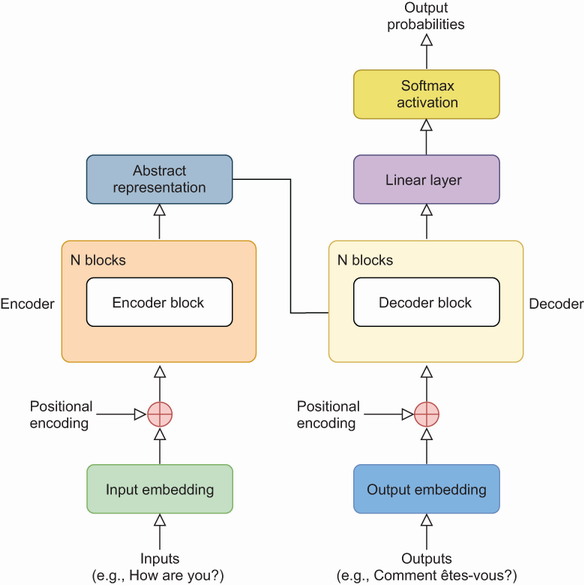
The Transformer architecture. The encoder in the Transformer (left side of the diagram) learns the meaning of the input sequence (e.g., the English phrase “How are you?”) and converts it into an abstract representation that captures its meaning before passing it to the decoder (right side of the diagram). The decoder constructs the output (e.g., the French translation of the English phrase) by predicting one word at a time, based on previous words in the sequence and the abstract representation from the encoder.
The diffusion model adds more and more noise to the images and learns to reconstruct them. The left column contains four original flower images. As we move to the right, some noise is added to the images in each time step, until at the right column, the four images are pure random noise. We then use these images to train a diffusion-based model to progressively remove noise from noisy images to generate new data samples.

Image generated by DALL-E 2 with text prompt “an astronaut in a space suit riding a unicorn”

Summary
- Generative AI is a type of technology with the capacity to produce diverse forms of new content, including texts, images, code, music, audio, and video.
- Discriminative models specialize in assigning labels while generative models generate new instances of data.
- PyTorch, with its dynamic computational graphs and the ability for GPU training, is well suited for deep learning and generative modeling.
- GANs are a type of generative modeling method consisting of two neural networks: a generator and a discriminator. The goal of the generator is to create realistic data samples to maximize the chance that the discriminator thinks they are real. The goal of the discriminator is to correctly identify fake samples from real ones.
- Transformers are deep neural networks that use the attention mechanism to identify long-term dependencies among elements in a sequence. The original Transformer has an encoder and a decoder. When it’s used for English-to-French translation, for example, the encoder converts the English sentence into an abstract representation before passing it to the decoder. The decoder generates the French translation one word at a time, based on the encoder’s output and the previously generated words.
 Learn Generative AI with PyTorch ebook for free
Learn Generative AI with PyTorch ebook for free