1 Getting started with MLOps and ML engineering
This chapter sets the stage for building production-grade ML systems by shifting focus from model creation to the realities of deployment, reliability, and ongoing operations. It introduces MLOps as the engineering discipline that brings structure, automation, and accountability to the full ML life cycle, emphasizing hands-on, iterative learning over theory. Aimed at data scientists, software engineers, and ML engineers alike, it outlines a practical journey that builds confidence through real-world patterns, clear workflows, and progressively introduced tools—laying foundations that also extend naturally to modern LLM use cases.
The ML life cycle is presented as an iterative process that moves from problem formulation and data collection/labeling through data versioning, training, evaluation, and validation—then transitions to dev/staging/production where full automation, deployment, monitoring, and retraining take center stage. Pipelines orchestrate non-linear experimentation, enforce reproducibility, and enable CI-triggered end-to-end runs. In production, models are served as services, monitored for both system and business metrics, and watched for drift; retraining is automated on schedules or thresholds. The chapter underscores the need for disciplined engineering practices—versioning, testing, observability, and rollback plans—to keep models reliable under real-world conditions.
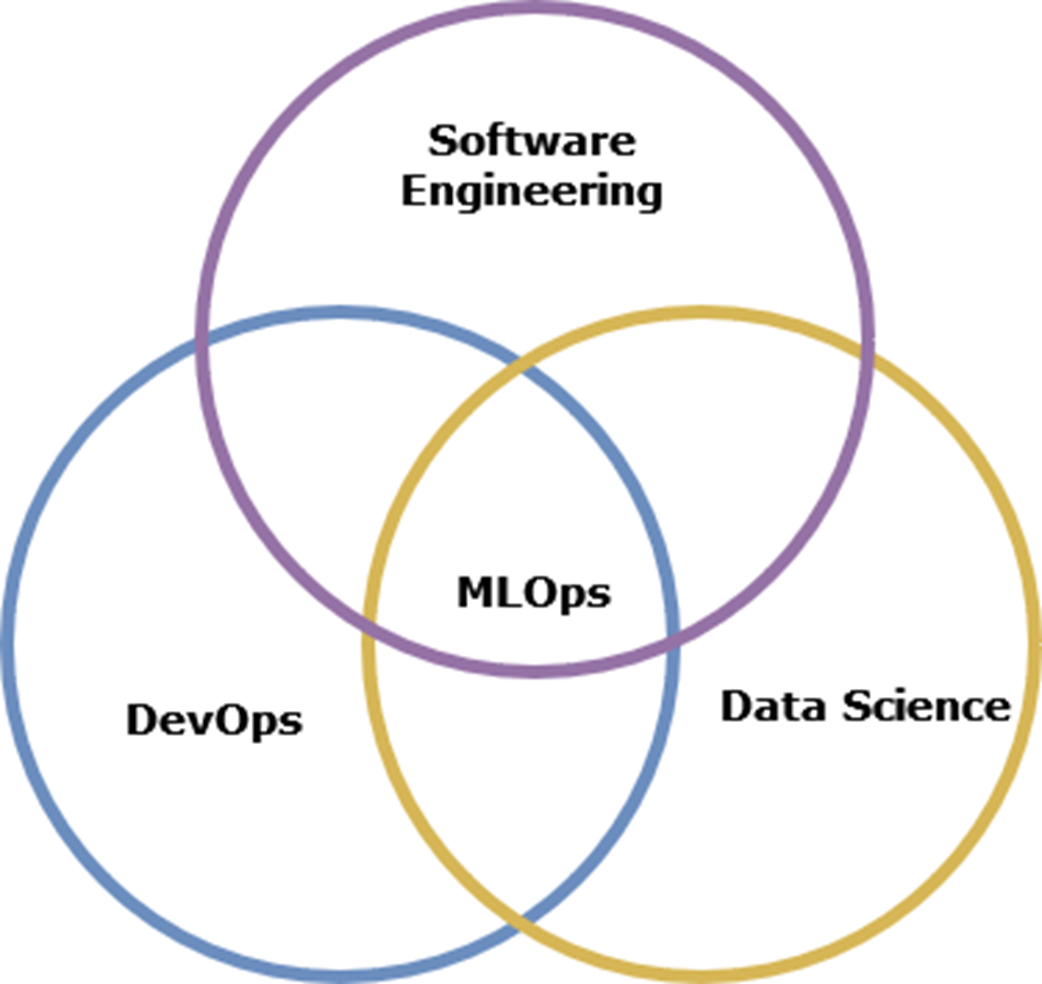
Success in MLOps requires a blend of strong software engineering, practical ML fluency, data engineering awareness, and a bias toward automation and reproducibility (with tools like Kubernetes and CI/CD). To ground these skills, the chapter lays out an incremental approach to building an ML platform using Kubeflow and its pipelines, then augmenting it with essential components such as a feature store, model registry, containerization, and deployment automation—while remaining pragmatic about tool choice and trade-offs. The journey is made concrete through three projects—an OCR system, a movie recommender, and a RAG-powered documentation assistant—demonstrating how the same core MLOps principles evolve from classic ML to LLMOps without abandoning the foundational platform and practices.
The experimentation phase of the ML life cycle

The dev/staging/production phase of the ML life cycle
MLOps is a mix of different skill sets
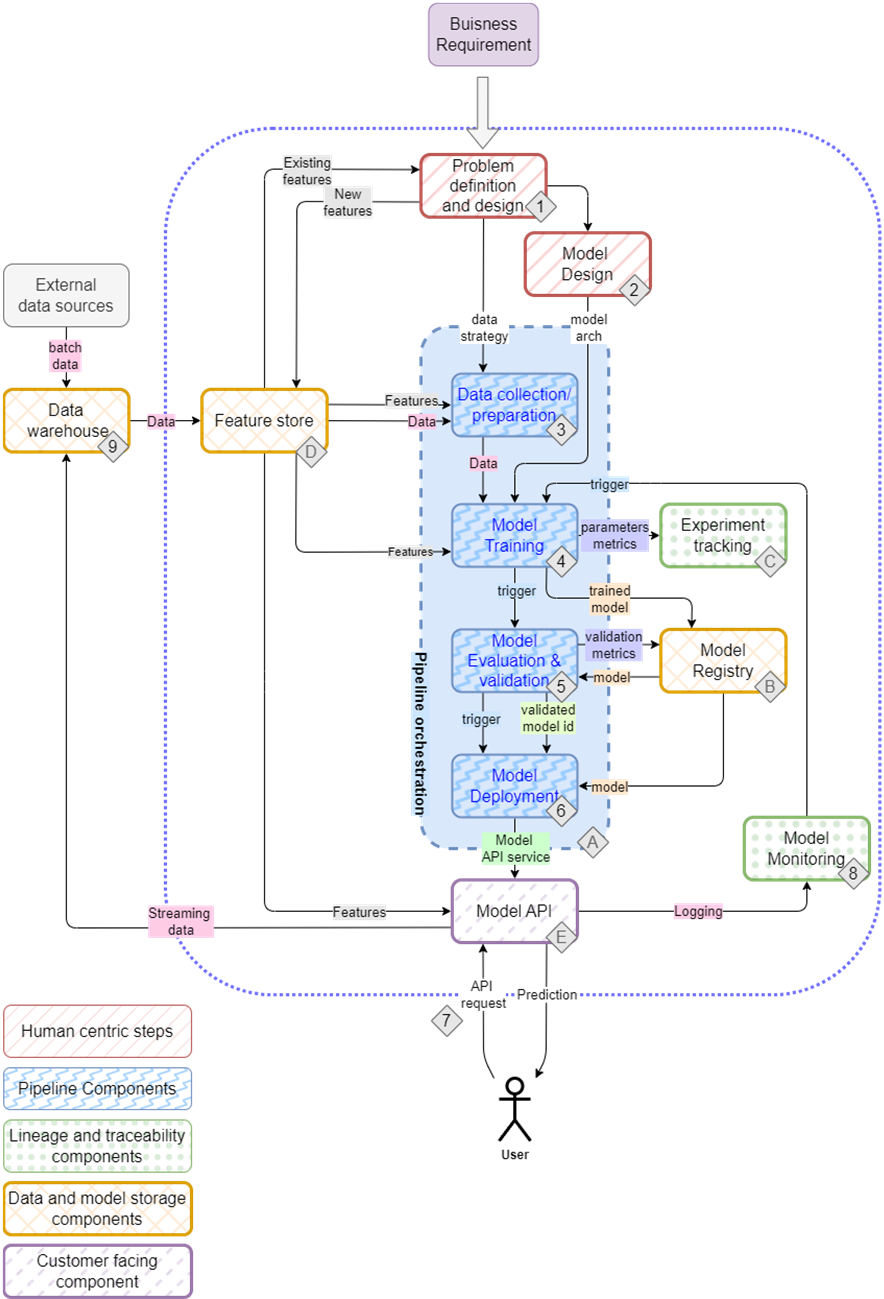
The mental map of an ML setup, detailing the project flow from planning to deployment and the tools typically involved in the process
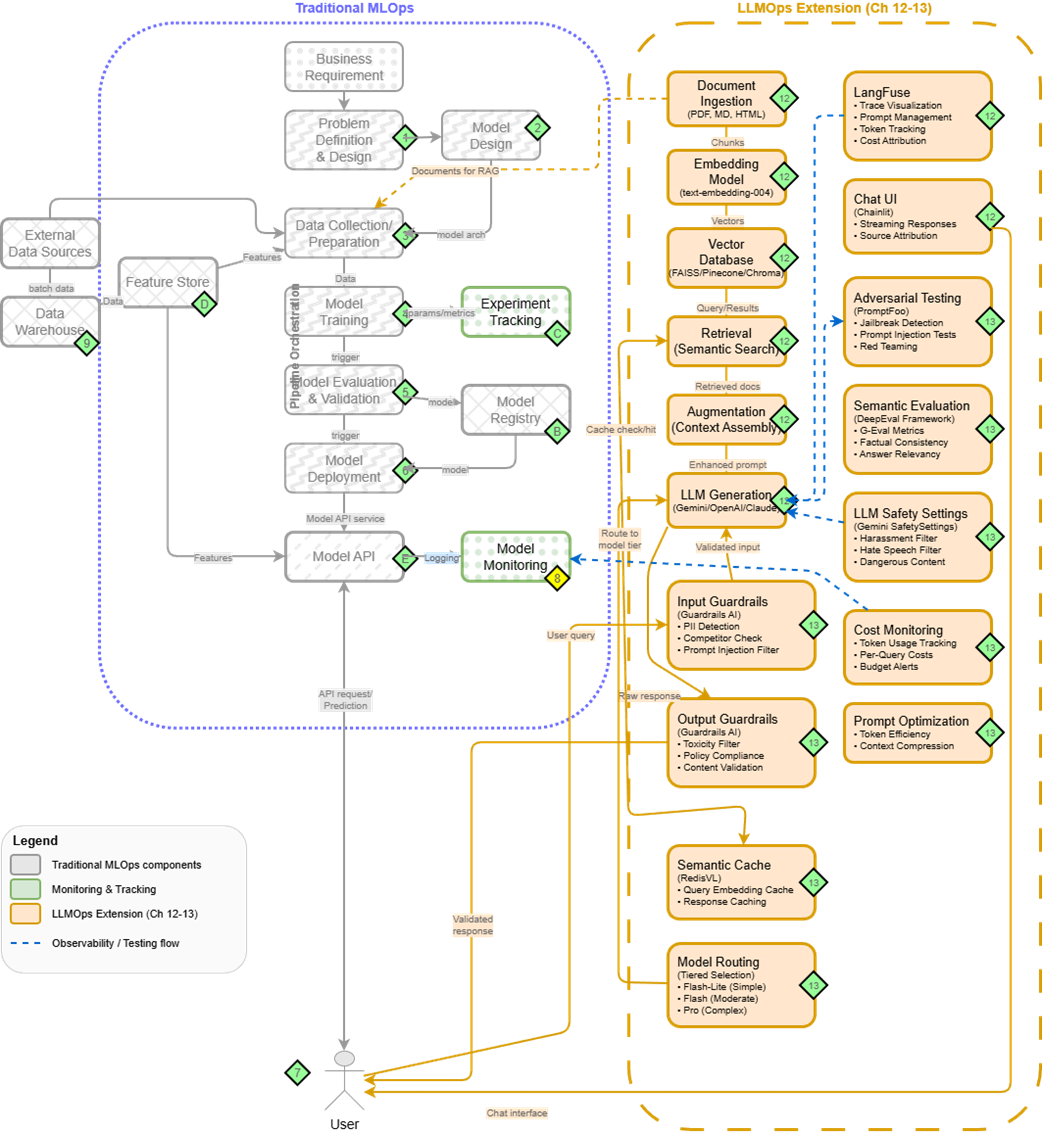
Traditional MLOps (right) extended with LLMOps components (left) for production LLM systems. Chapters 12-13 explore these extensions in detail.
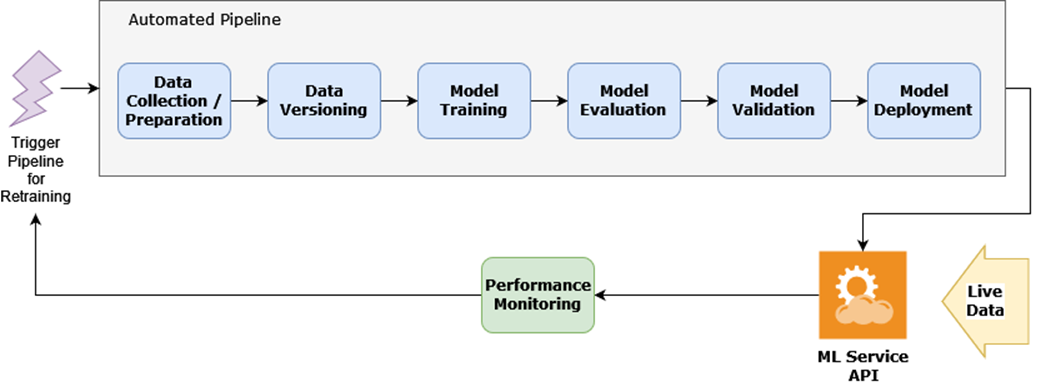
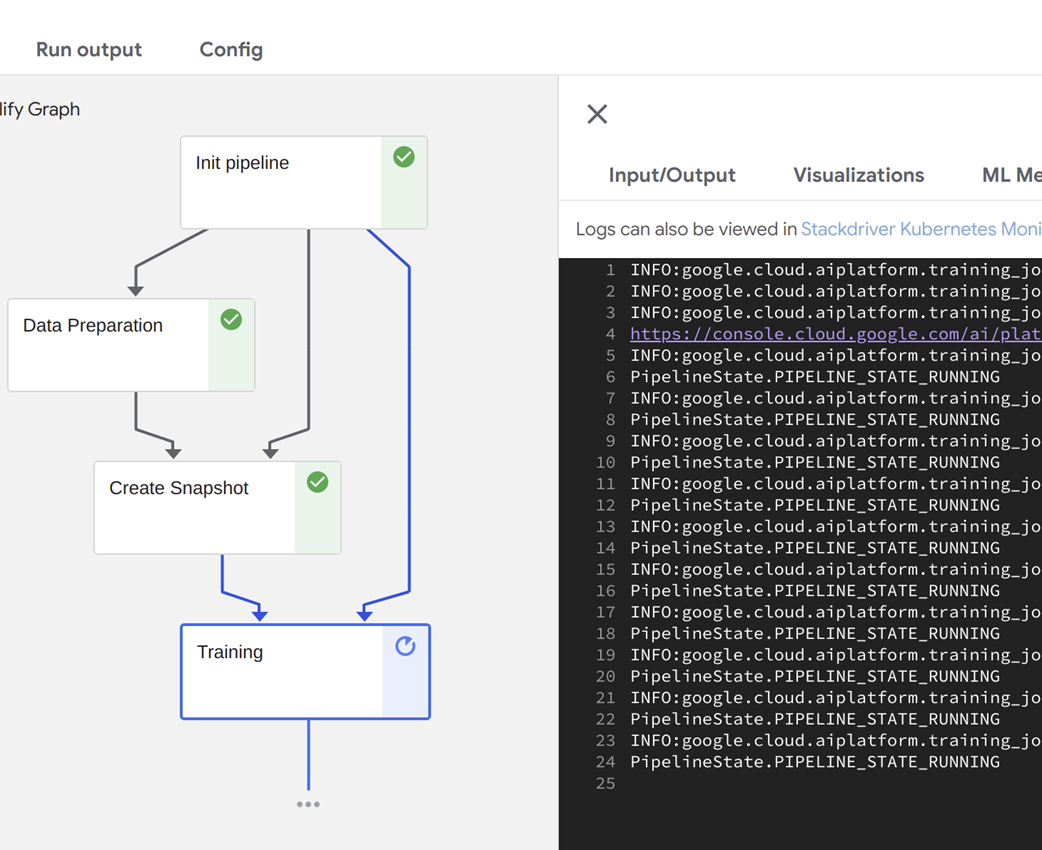
An automated pipeline being executed in Kubeflow.
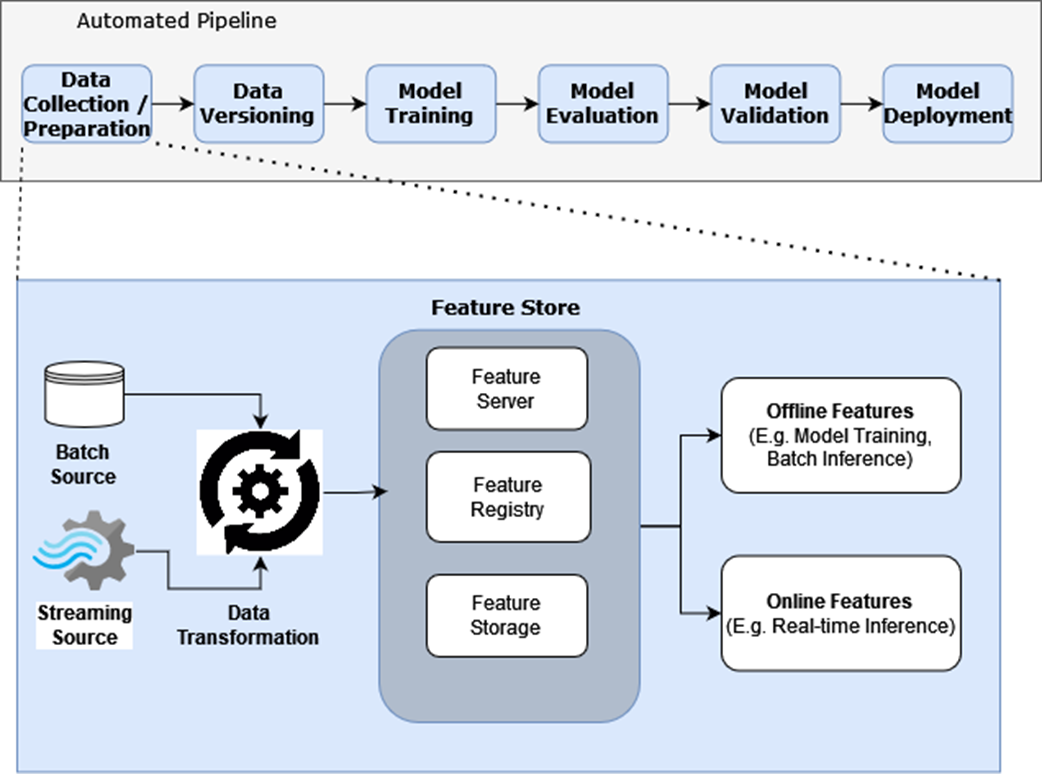
Feature Stores take in transformed data (features) as input, and have facilities to store, catalog, and serve features.
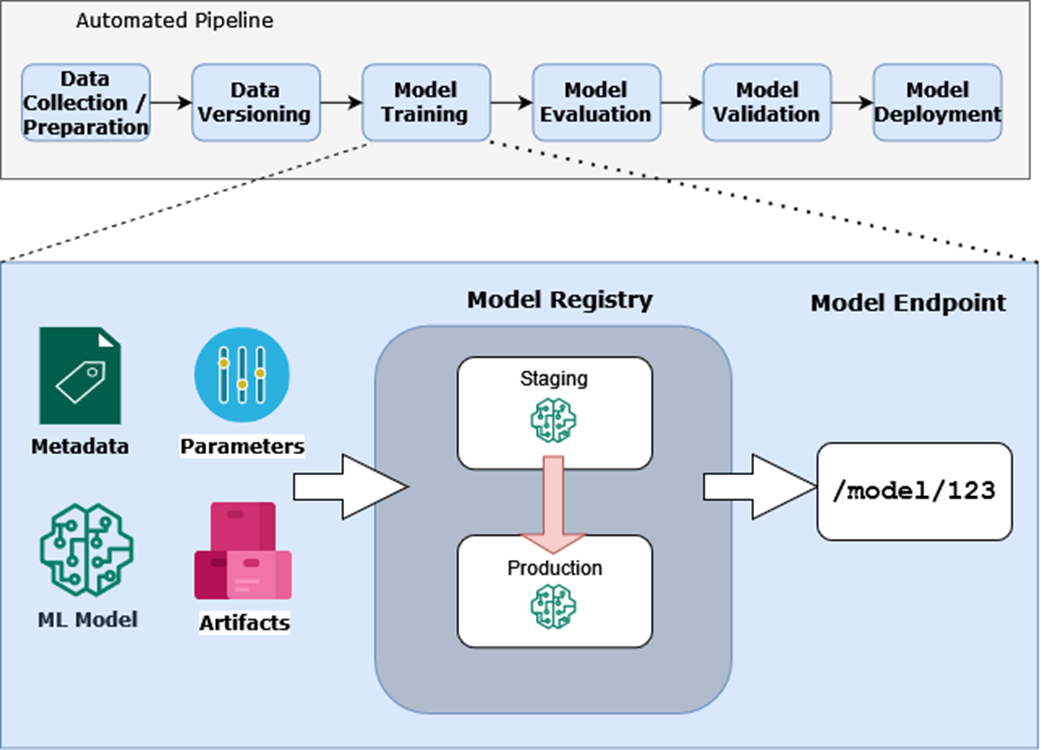
The model registry captures metadata, parameters, artifacts, and the ML model and in turn exposes a model endpoint.
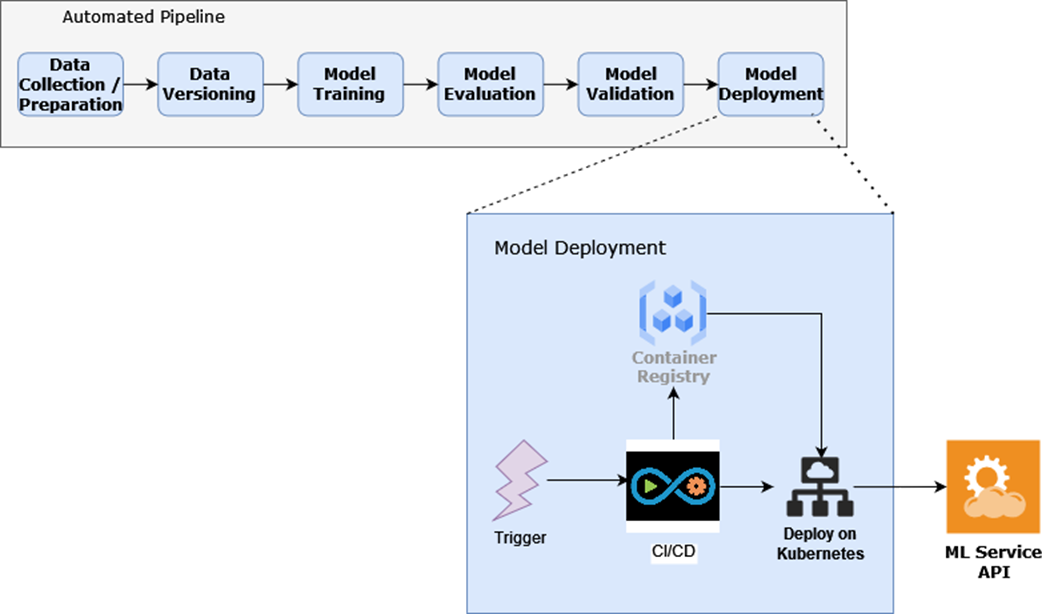
Model deployment consists of the container registry, CI/CD, and automation working in concert to deploy ML services.
Summary
- The Machine Learning (ML) life cycle provides a framework for confidently taking ML projects from idea to production. While iterative in nature, understanding each phase helps you navigate the complexities of ML development.
- Building reliable ML systems requires a combination of skills spanning software engineering, MLOps, and data science. Rather than trying to master everything at once, focus on understanding how these skills work together to create robust ML systems.
- A well-designed ML Platform forms the foundation for confidently developing and deploying ML services. We'll use tools like Kubeflow Pipelines for automation, MLFlow for model management, and Feast for feature management - learning how to integrate them effectively for production use.
- We'll apply these concepts by building two different types of ML systems: an OCR system and a Movie recommender. Through these projects, you'll gain hands-on experience with both image and tabular data, building confidence in handling diverse ML challenges.
- Traditional MLOps principles extend naturally to Large Language Models through LLMOps - adding components for document processing, retrieval systems, and specialized monitoring. Understanding this evolution prepares you for the modern ML landscape.
- The first step is to identify the problem the ML model is going to solve, followed by collecting and preparing the data to train and evaluate the model. Data versioning enables reproducibility, and model training is automated using a pipeline.
- The ML life cycle serves as our guide throughout the book, helping us understand not just how to build models, but how to create reliable, production-ready ML systems that deliver real business value.
 Machine Learning Platform Engineering ebook for free
Machine Learning Platform Engineering ebook for free