Large language models deliver impressive general abilities, but their breadth makes them slow, costly, and hard to control when applied to focused business problems. This chapter motivates tailoring models to specific tasks and domains—often by building smaller, faster small language models—as a path to lower latency and cost, better governance and explainability, and, crucially, true competitive differentiation. The central idea is to move beyond using generic systems and prompts, and instead reshape the model itself so architecture and objectives align.
When prototypes become production systems, several issues surface: token-based API costs scale unpredictably; oversized infrastructure sits underused; and relying on the same general models as competitors limits unique value. Prompt engineering and retrieval techniques help but cannot alter a model’s core competencies, while fine-tuning closed models is expensive and deepens vendor lock-in. Even open models often over-index on benchmarks and ship capabilities that go unused in real workloads. The chapter argues for right-sizing and specialization, shows that targeted pruning combined with knowledge distillation can substantially reduce parameters with limited performance loss, and highlights the need for transparency in regulated settings via tools like activation analysis to understand and shape behavior.
The solution is a rearchitecting pipeline that modifies structure first and knowledge second. It begins with pruning to remove components that contribute least to the target objectives, followed by knowledge distillation to restore capabilities from a teacher model, and optionally adds efficient fine-tuning (such as LoRA) for domain specialization; light teacher calibration can precede these steps. A domain dataset guides what to prune and how to specialize, while a general dataset helps preserve broad skills. The pipeline is flexible—supporting deep specialization or pure efficiency gains—and the book provides a practical roadmap and toolkit (GPU-centric workflows, PyTorch, and the Hugging Face ecosystem), culminating in activation-level techniques, including fairness-oriented pruning, to turn practitioners into true LLM architects.
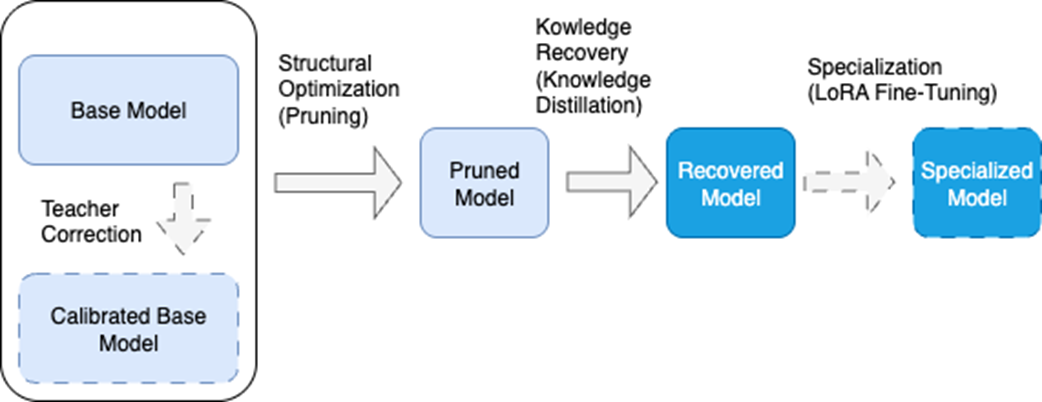
The model tailoring pipeline consists of core phases (shown with solid arrows) and optional phases (shown with dashed arrows). In the first phase, we adapt the structure to the model's objectives through pruning. Next, we recover the capabilities it may have lost through knowledge distillation. Finally, we can optionally specialize the model through fine-tuning. An optional initial phase calibrates the base model using the dataset for which we're going to specialize the final model.
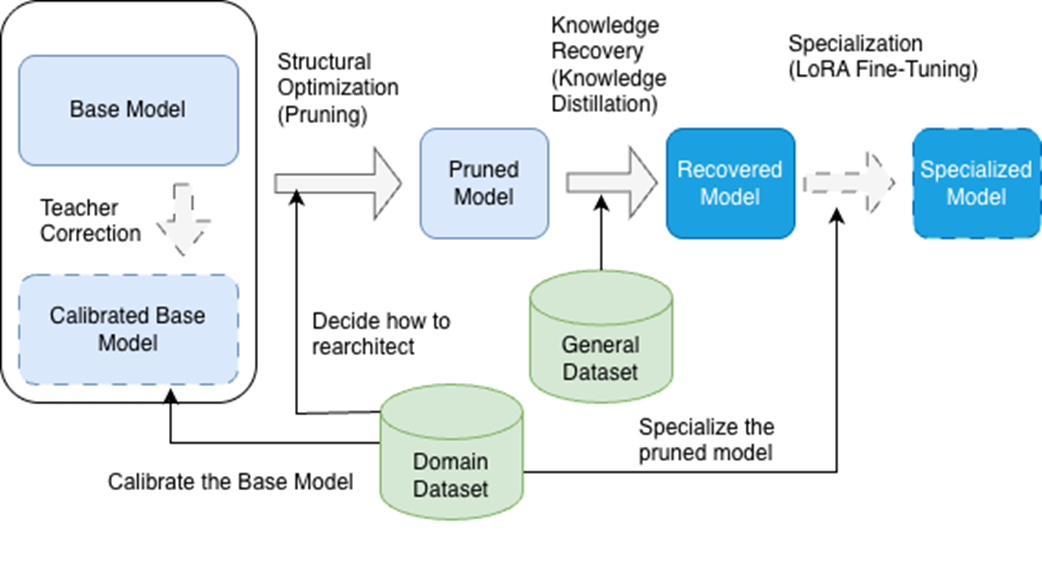
Dataset integration in the tailoring pipeline. The domain-specific dataset guides the calibration of the base model, informs structural optimization decisions, and drives the final specialization through LoRA fine-tuning. A general dataset supports Knowledge Recovery, ensuring the pruned model retains broad capabilities before domain-specific specialization. This dual approach optimizes each phase for the project's specific objectives.
Summary
The use of oversized generic LLMs brings problems like high production costs, lack of differentiation from competitors, and zero explainability of decisions.
Models increase their effectiveness and efficiency by adapting their architecture to a specific domain and task.
The model tailoring process consists of three phases: Structure Optimization, Knowledge Recovery, and Specialization.
The domain-specific dataset is a main element and common thread throughout the entire process, ensuring that each optimization and specialization phase is aligned with the final objective.
Knowledge distillation transfers capabilities from the original teacher model to the pruned student model, learning not only the correct answers, but also the reasoning process that leads to them.
Fine-tuning techniques, like LoRA, allow domain specialization by training only a small number of parameters, drastically reducing costs and time needed.
Modern architectures like LLaMA, Mistral, Gemma, and Qwen share structures that make them ideal for rearchitecting techniques.
By mastering these techniques, developers can go from being model users to model architects.
FAQ
What makes generic LLMs a poor fit for specialized business tasks?They are trained for broad, multi-domain competence and often reach tens or hundreds of billions of parameters. This breadth brings heavy compute and latency, while features optimized for benchmarks (like massive context windows or mixture-of-experts) are underused in narrow domains. The result is higher cost, slower inference, and limited domain effectiveness compared to a right-sized, task-focused model.What is model tailoring (rearchitecting), and how is it different from prompt engineering or plain fine-tuning?Model tailoring alters the model’s structure and internals for a specific objective. It combines pruning (removing low-value components), knowledge distillation (recovering capabilities from a teacher), optional domain fine-tuning (e.g., LoRA), and analysis of neuron activations to surgically correct behavior. Prompt engineering and RAG guide outputs or add information, but don’t change the model’s internal expertise; fine-tuning alone updates weights without fixing architectural mismatch and can be costly and provider-dependent on closed models.What are Small Language Models (SLMs) and why build them?SLMs are specialized models with a few million to low billions of parameters. They’re lightweight and fast, ideal as building blocks that collaborate with other SLMs and software. Benefits include lower inference cost, faster iteration, easier deployment on edge devices, and competitive differentiation for domain tasks.Why don’t prompt engineering and RAG deliver lasting differentiation?Prompt engineering can nudge behavior, and RAG can inject fresh or private knowledge, but neither changes the way the model processes information. The core expertise remains generic, so performance gains plateau and outputs converge with competitors using the same base models and data access.What risks do API-based general models introduce in production?Costs scale unpredictably with both input and output tokens (especially with tool-using agents), and inference spend can explode after POC. Fine-tunes on closed models create vendor lock-in (non-exportable weights, version churn). Black-box issues arise from limited visibility and unannounced model updates that can break systems. Oversized on-prem deployments can be equally wasteful if the model is mismatched to the task.What are the phases of the model rearchitecting pipeline, and when should I use the minimal vs. full pipeline?The core phases are: (1) Structural Optimization via pruning, (2) Knowledge Recovery via distillation, and (3) optional domain specialization via LoRA. There’s also an optional initial Teacher Correction to lightly align the base model with your data. Use the minimal pipeline (1+2) when you mainly need efficiency (e.g., edge deployment) without deep domain specialization; use the full pipeline when domain accuracy and differentiation are required. The order maximizes compute savings by training on smaller models.How do pruning and knowledge distillation work together to retain quality?Pruning removes layers/neurons that contribute least to your objective, guided by task data. Distillation then restores capability by having the pruned “student” learn not only answers but the teacher’s step-by-step reasoning patterns. Research cited in the chapter shows targeted pruning plus distillation can cut parameters by roughly 25–30% with limited average performance loss on specialized tasks.What role does data play across the pipeline?A domain-specific dataset is the backbone: it can calibrate the teacher, reveal what to prune, shape distillation goals, and drive final LoRA specialization. A general-purpose dataset supports recovery so the pruned model retains broad skills. If you only want efficiency, you can skip domain data and prune using structural importance metrics, or use benchmark datasets (e.g., BoolQ for reading comprehension, IFEval for instruction following) to target specific capabilities.How does rearchitecting improve explainability and compliance?By analyzing neuron activations, you can see which components fire for certain inputs, diagnose behavior, and apply fairness pruning to remove unwanted behaviors with minimal impact on performance. Owning and modifying the model reduces black-box risks and helps meet explainability requirements in regulated sectors where API-only opacity and silent updates are problematic.What hardware and software are recommended to follow the book’s examples?An NVIDIA CUDA-capable GPU with ~12GB VRAM is sufficient; a Google Colab T4 (often on the free tier) works for many notebooks. The software stack centers on PyTorch and Hugging Face (Transformers, models hub), plus lm-evals for benchmarking. Configure an HF_TOKEN in Colab when needed. The book also provides the open-source optiPfair library to encapsulate boilerplate, and uses modern model families like LLaMA, Gemma, and Qwen.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Rearchitecting LLMs ebook for free
Rearchitecting LLMs ebook for free