RLHF is presented as a way to bring human preferences into AI systems, especially for problems where the right behavior is hard to define precisely. The chapter explains that this method rose to prominence as language models became widely used and as people needed systems that could respond in ways that are not just correct, but also helpful, safe, and aligned with subtle user expectations. It frames RLHF as part of the broader shift from base-model pretraining to post-training, a process that has become central to modern AI development.
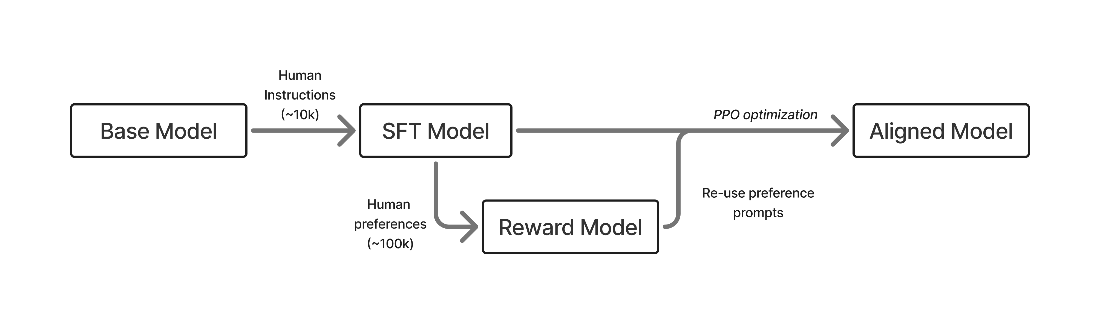
The chapter outlines the basic RLHF pipeline: first, train a model to follow instructions; second, collect human preference data to train a reward model; and third, use reinforcement learning to improve the model’s responses based on that reward signal. It emphasizes that RLHF does not mainly change individual tokens one by one, but instead shapes whole responses, teaching the model what kinds of answers are better or worse. This is why RLHF can influence tone, format, reliability, and conversational quality, not just factual accuracy.
Beyond the mechanics, the chapter argues that post-training extracts and amplifies capabilities already present in base models, much like refining a car chassis into a high-performance vehicle. It contrasts early skepticism about RLHF with later evidence that preference tuning and related methods are essential for strong modern models, even though they are costly and technically complex. The chapter closes by positioning the book as a guide to the evolving landscape of RLHF and neighboring methods, with the goal of helping readers understand both how these systems are built and why they matter so much for current AI progress.
A rendition of the early, three stage RLHF process: first training via supervised fine-tuning (SFT, chapter 4), building a reward model (RM, chapter 5), and then optimizing with reinforcement learning (RL, chapter 6).
Summary
RLHF incorporates human preferences into AI systems to solve problems that are hard-to-specify programmatically, and became widely known through ChatGPT’s breakout, which made the capabilities of language models more approachable.
The basic RLHF pipeline has three steps: instruction fine-tuning to teach the model to follow the question-answering format, training a reward model on human preferences, and optimizing the model with RL against that reward.
RLHF is known to primarily change the style, tone, and format of model responses – making them more helpful, warm, and engaging. But it’s not “just style transfer”: RLHF also improves benchmark performance, though over-optimization (e.g., excessive length or chattiness) can harm capabilities in other domains.
The elicitation theory of post-training suggests that base models contain latent potential, and post-training’s job is to extract and cultivate that intelligence into useful behaviors.
RLHF is one component of modern post-training, alongside instruction fine-tuning (IFT/SFT) and reinforcement learning with verifiable rewards (RLVR), used together in an intertwined manner to craft particular training recipes.
FAQ
What is RLHF, and why was it created?RLHF stands for Reinforcement Learning from Human Feedback. It was created to help AI systems handle hard-to-specify problems, especially when human preferences are difficult to express directly. Instead of relying only on explicit rules, RLHF uses human feedback to guide model behavior.Why did RLHF become especially important in modern AI?RLHF became important because it helped transform language models from simple text generators into useful assistant-like systems. It played a major role in the success of ChatGPT and later large language models by improving how models respond to users.What are the main steps in the RLHF pipeline?The basic RLHF pipeline has three steps: first, train an instruction-following language model; second, collect human preference data to train a reward model; third, optimize the language model with reinforcement learning using the reward model as the signal.How does RLHF differ from supervised fine-tuning?Supervised fine-tuning teaches models to imitate examples and learn the basic format of instruction following. RLHF goes further by optimizing responses at the whole-answer level, using human preference feedback to shape better, more helpful, and more aligned outputs.What kinds of improvements does RLHF make to model responses?RLHF often improves the style of responses, making them more reliable, warm, engaging, and helpful. It can also shape subtle behaviors that are hard to capture with simple rules, such as tone, safety, and overall usefulness.Why is style such a big part of RLHF?Style matters because it affects how users receive information. RLHF can change a model’s tone, structure, and manner of response so that answers feel more natural, supportive, and usable, not just technically correct.What is a reward model in RLHF?A reward model is a model trained on human preference comparisons to score how good a response is. It produces a scalar reward signal that later guides reinforcement learning, helping the system learn which outputs humans prefer.Why is RLHF considered more complex than instruction tuning?RLHF is more complex because it relies on proxy reward models, noisier human preference data, and careful control of optimization. It can also suffer from over-optimization and other issues like length bias, so it requires more engineering and compute.What is the “elicitation” intuition for post-training?The elicitation view says pretraining gives the model broad hidden potential, and post-training helps extract and shape that potential into useful behavior. In this view, post-training does not create intelligence from scratch; it makes existing capabilities easier to access and use.How does RLHF fit into the broader idea of post-training?RLHF is one part of post-training, which includes instruction tuning, preference fine-tuning, and newer methods like reinforcement learning with verifiable rewards. Together, these techniques help turn a pretrained base model into a more capable and useful assistant.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Reinforcement Learning from Human Feedback ebook for free
Reinforcement Learning from Human Feedback ebook for free