1 How RAG research prevents disasters
Retrieval-Augmented Generation (RAG) connects large language models to authoritative, current knowledge sources so responses are grounded rather than guessed. The chapter opens with a cautionary lesson: a customer-service chatbot confidently contradicted the airline’s own policy, illustrating a factually inconsistent hallucination that led to legal and financial consequences. Beyond one incident, the authors argue that organizations repeatedly face three enduring constraints—keeping knowledge current, preventing hallucinations during synthesis, and accessing private, fast-changing internal data—making RAG not a fad but a durable architectural pattern. Research literacy becomes a strategic edge: teams that understand how RAG really works can anticipate limitations, engineer safeguards, and turn reliability into a competitive advantage.
To move from trial-and-error to engineering discipline, the chapter introduces a seven-point taxonomy of RAG failures—missing content, missed top rank, factually inconsistent hallucination, not in context, not extracted, incorrect specificity, and incomplete answers—and shows how these issues quietly erode trust even when systems are “usually” right. It maps failure modes to concrete remedies across the indexing and query pipelines: better curation and chunking, query expansion and hypothetical document generation, hybrid retrieval and re-ranking, result fusion, context compression and organization, and generation-time grounding and verification. Research-backed methods such as Self-RAG (confidence and self-critique), FLARE (active, need-aware retrieval), HyDE (bridging query–document vocabulary gaps), and result-fusion strategies help detect uncertainty, trigger additional retrieval, and align synthesis with sources. The chapter also weighs costs and infrastructure trade-offs, noting that while longer contexts, fine-tuning, and caching strengthen RAG, they do not replace retrieval-first grounding.
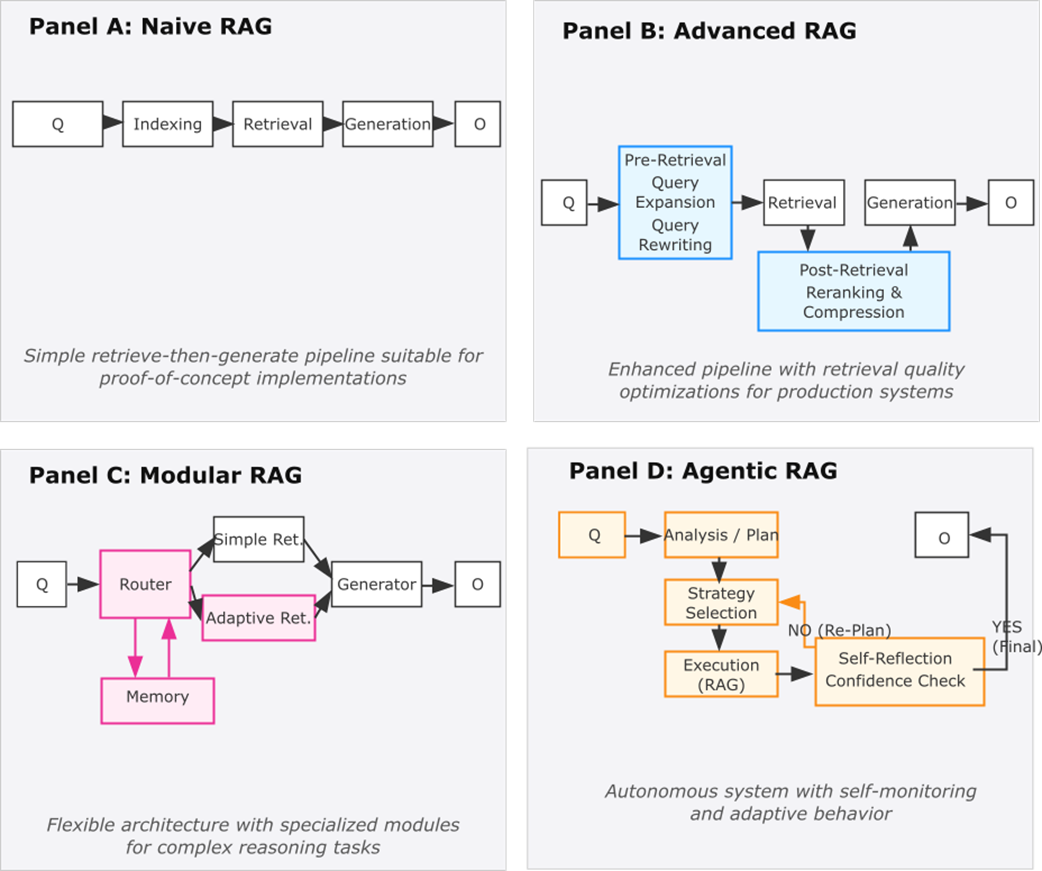
Finally, the authors chart an architectural progression that guides investment: Naive RAG for rapid, low-cost foundations; Advanced RAG to optimize preprocessing, retrieval, and context for production; Modular RAG to compose specialized components across diverse data and tasks; and Agentic RAG for autonomous, iterative information seeking with self-monitoring and multi-step reasoning. Each stage has clear upgrade triggers tied to accuracy demands, domain complexity, risk, and scale, along with operational considerations like orchestration, evaluation, and cost controls. The book’s teaching approach emphasizes research literacy, prevention of known failure modes, progressive complexity, hands-on implementation, and systematic evaluation—so practitioners can predict, measure, and improve reliability before failures undermine user trust.
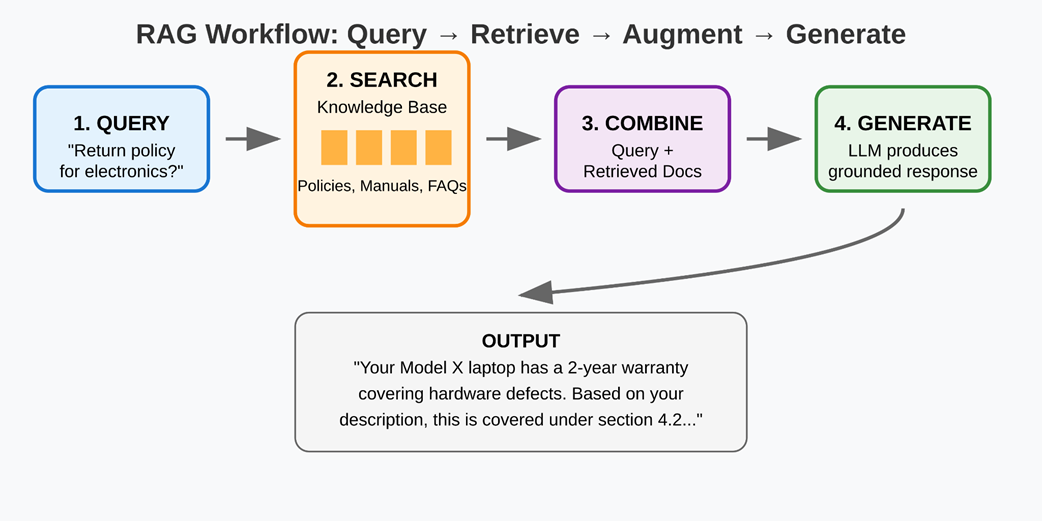
The RAG workflow — from user queries to grounded responses through retrieval and generation.
RAG architectural evolution from Naive to Agentic implementations. Each paradigm builds upon its predecessors while adding specialized components and capabilities to address increasingly complex requirements.
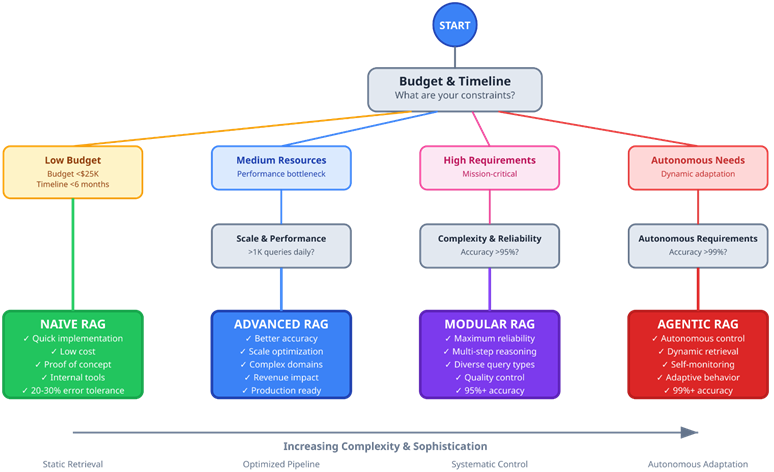
RAG Implementation Decision Tree — Business Decisions guiding RAG choices.
Summary
- Retrieval-Augmented Generation solves three critical limitations that make standalone language models unreliable for production applications: knowledge boundaries that prevent access to current information, hallucinations that generate unverifiable claims, and the inability to incorporate private organizational knowledge that drives business decisions.
- The seven-point failure taxonomy provides a systematic diagnosis for RAG system problems rather than guessing at solutions. Failure points, such as "Missed the Top Rank" and "Factually Inconsistent Hallucination," enable the precise identification of issues and the selection of research-backed solutions that address specific failure modes.
- RAG systems evolve through four architectural stages based on complexity requirements and business needs. Naive RAG establishes basic retrieve-then-generate functionality for proof-of-concept applications. Advanced RAG optimizes retrieval quality and context processing for production performance. Modular RAG implements adaptive strategies and quality control for mission-critical applications. Agentic RAG introduces autonomous planning and self-correction to the retrieval and generation loop.
- The core RAG architecture coordinates two specialized components: retrieval systems that find relevant information from external knowledge sources, and generation systems that synthesize retrieved context with user queries to produce grounded, factual responses. This coordination enables AI systems that combine broad language capabilities with specific, current, and verifiable knowledge.
- Research literacy transforms technology evaluation from reactive debugging to proactive problem-solving. Understanding the academic foundations behind RAG techniques enables independent assessment of new approaches, strategic planning for system evolution, and adaptation to changing requirements without waiting for tutorials or expert opinions.
 Retrieval Augmented Generation, The Seminal Papers ebook for free
Retrieval Augmented Generation, The Seminal Papers ebook for free