1 How AI works
This chapter offers a clear, opinionated tour of how modern AI—especially large language models (LLMs)—works in practice. It explains popular terms that have entered mainstream conversation (tokens, embeddings, temperature, context window) and shows how everyday experiences with chatbots are shaped as much by “wrappers” around models as by the models themselves. Along the way, it highlights real-world constraints and trade-offs: token-based billing, the growing but finite context windows, quirks of tokenization that make some languages costlier to handle than English, and known weaknesses such as letter-level reasoning. It also demystifies why chat systems feel helpful and up to date: the surrounding software inserts system prompts, orchestrates tools and function calls, and retrieves external documents (RAG) to augment a model that is otherwise a static next-token predictor.
Under the hood, LLMs are autoregressive predictors that generate text one token at a time from a fixed vocabulary. Tokens are mapped to high-dimensional embeddings that capture meaning, enabling the transformer architecture to contextualize each token with attention, multihead mechanisms, and many stacked layers before scoring the probabilities of the next token. Sampling settings (temperature, Top-p, Top-k) control creativity versus conservatism, while context-window limits govern how much text can be considered at once. The chapter details how wrappers expand raw capabilities—turning single-token predictions into full responses, delimiting turns for chat, calling external tools for real-time data, and injecting retrieved passages so outputs can cite or reflect recent or private information. It also explains practical frictions, from token billing and chat-history growth to the challenges of non-English tokenization and analyzing letter-level structure.
Zooming out, the chapter situates LLMs within machine learning at large: models are built by designing an architecture and then learning billions of parameters from data. LLMs rely heavily on self-supervised pretraining, followed by fine-tuning and reinforcement learning with human feedback (RLHF) to better align behavior with human preferences; their quality is optimized via loss functions and large-scale stochastic gradient descent. Beyond language, convolutional neural networks (CNNs) extract hierarchical visual features, U-Nets transform images to images, and diffusion models denoise inputs to generate images and even video, while multimodal systems combine CNNs and LLMs to move between text and visuals. The chapter closes with a sober principle: there is no universally best model. Progress comes from crafting architectures and scaffolding—transformers, CNNs, tool use, and retrieval—tailored to each task, with humans guiding models far more than it may seem.
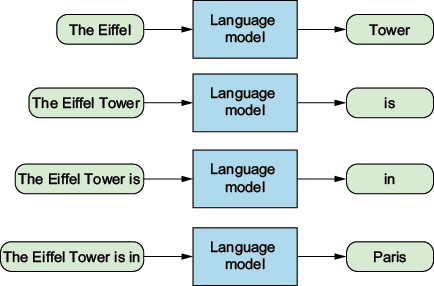
To generate full sentences, the LLM wrapper used the LLM to generate one word, then attached that word to the initial prompt, then used the LLM again to generate one more word, and so on.
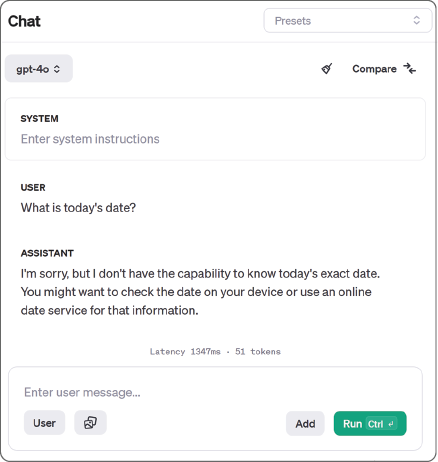
OpenAI’s API lets users define a system prompt, which is a piece of text inserted into the beginning of the user’s prompt.
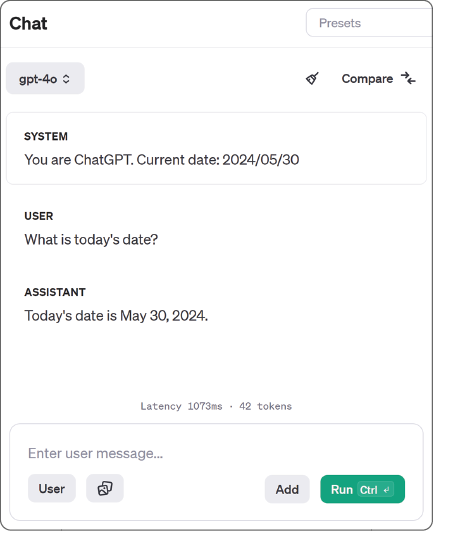
When the current date is supplied as part of the system prompt, the LLM can answer questions about the current date.
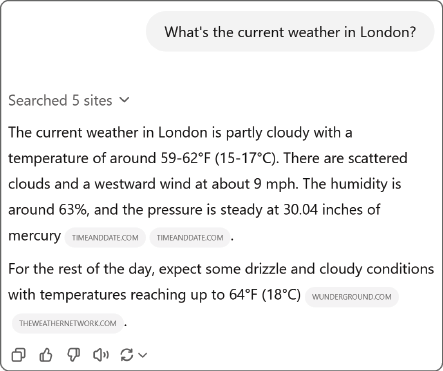
ChatGPT called a function to search the web behind the scenes and inserted the results into the user’s prompt. This creates the illusion that the LLM browses the web.
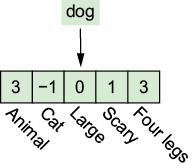
Each token is mapped to a vector of numbers. We can imagine that each number in the vector represents a topic. Here’s an imaginary list of topics and their respective numbers for the “dog” token.
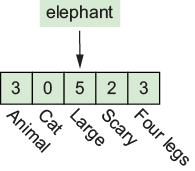
An imaginary embedding vector for the “elephant” token
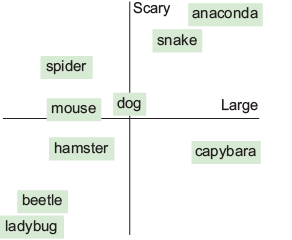
We can think the numbers in an embedding vector as coordinates that place the token in a multidimensional “meaning space.”
LLMs often struggle to analyze individual letters in words.

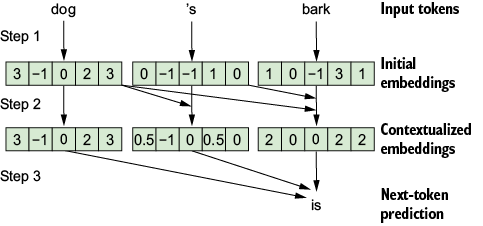
LLM overview. In step 1, the tokens are mapped to embeddings one by one. In step 2, each embedding is improved by contextualizing it using the previous tokens in the prompt. In step 3, the much-improved embeddings are used to make predictions about the next token.
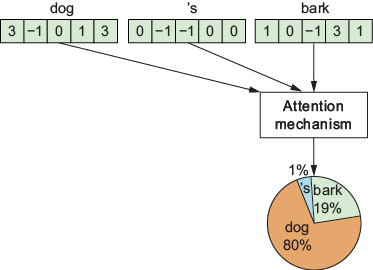
The attention mechanism calculates the relative relevance of all tokens in the context window to contextualize or disambiguate the last token.
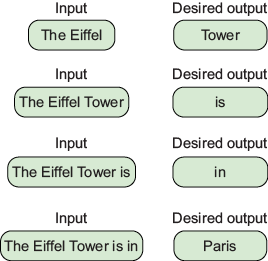
Training examples are generated by subdividing existing sentences and turning the last token in each into the desired autocomplete label.
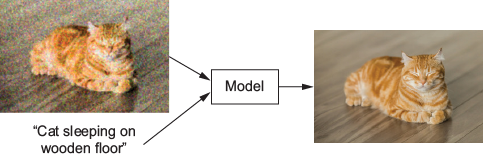
A diffusion model is trained to improve a corrupted image paired with its caption.
A diffusion model is used repeatedly to have a desired image emerge from Gaussian noise.

Summary
- LLMs are designed to guess the best next word that completes an input prompt.
- LLMs subdivide inputs into valid tokens (common words or pieces of words) from an internal vocabulary.
- LLMs calculate the probability that each possible token is the one that comes next after the input.
- A wrapper around the LLM enhances its capabilities. For examples, it makes the LLM eat its own output repeatedly to generate full outputs, one token at a time.
- Current LLMs represent information using embedding vector, which are lists of numbers.
- Current LLMs follow the transformer architecture, which is a method to progressively contextualize input tokens.
- LLMs are created using machine learning, meaning that data is used to define missing parameters inside the model.
- There are different types of machine learning, including supervised, self-supervised, and unsupervised learning.
- In supervised learning, the computer learns by example—it is fed with examples of how to perform the task. In the case of self-supervised learning, these examples are generated automatically by scanning data.
- Popular LLMs were first trained in a self-supervised way using publicly available data, and then, they were refined using manually generated data to align them to the users’ objectives.
- CNNs are a popular architecture to process other types of data, such as images.
- CNNs are combined with transformers to create multimodal AI.
 The AI Pocket Book ebook for free
The AI Pocket Book ebook for free