10 The Nature of Preferences
Reinforcement learning from human feedback treats human preferences as the fuel and target of learning when explicit reward design is infeasible. But what counts as “better” is often subjective and context-laden—as simple as preferring one poem over another—so RLHF inherits the ambiguity of human judgment. The chapter situates RLHF within an interdisciplinary lineage spanning philosophy, psychology, economics, decision theory, optimal control, and modern deep learning. Because each field brings its own assumptions about what preferences are and how they can be optimized, RLHF can never be a fully solved problem; in practice it emphasizes empirical alignment on concrete behaviors rather than perfect value calibration. Ongoing work therefore explores pluralistic alignment across populations and personalization to respect divergent values while maintaining practical performance.
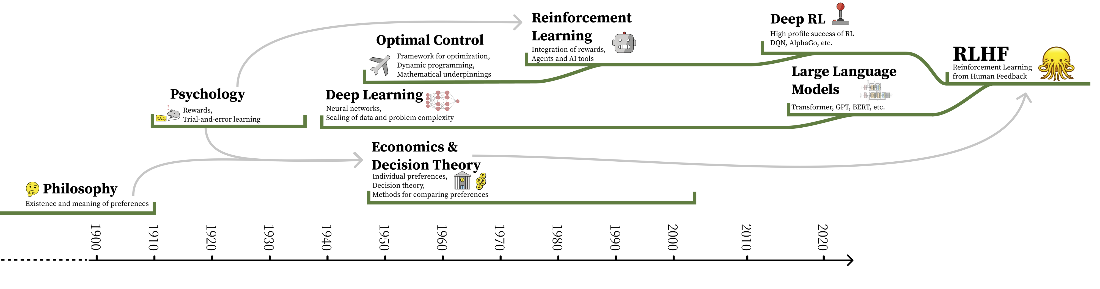
Historically, ideas about utility and choice—from early probability and decision theory through utilitarian calculus to formal treatments of uncertainty—paved the way for modeling preference as something that could be quantified. Reinforcement learning then fused operant conditioning’s notion of “reward” with control theory’s utility-to-go, culminating in the Bellman equation and the MDP framework, and later in TD learning, Q-learning, and deep RL successes in games and control. These methods assume stable, well-defined objectives and stationary environments, assumptions that clash with messy, open-ended human judgments. Although inverse reinforcement learning is closely related to learning rewards from behavior, RLHF largely evolved through an engineering path focused on reward modeling from comparative feedback at scale. The result is a powerful toolkit optimized for utility under uncertainty, yet strained when compressing many heterogeneous, shifting human desiderata into a single scalar signal.
The chapter details why this compression is fragile: human preferences drift over time, depend on presentation and context, and resist neat Markovian assumptions or full observability common in RL formalisms. While the Von Neumann–Morgenstern utility theorem licenses representing preferences with expected utility, its prerequisites are routinely violated in real interfaces and social settings. Social choice results (like impossibility theorems) underscore that not all fairness desiderata can be satisfied simultaneously, and attempts at interpersonal utility comparison or principal–agent formulations introduce new tensions, including corrigibility concerns. Practically, RLHF data can exhibit intransitivity, framing effects, reliance on noisy proxies, and low inter-annotator agreement, all of which complicate aggregation and optimization. Hence RLHF is best viewed as an iterative, empirically grounded process: it aligns models to observed human feedback for specific tasks while acknowledging unresolved normative trade-offs, motivating better dataset engineering, evaluation, and personalization rather than a final, universal solution.
The timeline of the integration of various subfields into the modern version of RLHF. The direct links are continuous developments of specific technologies, and the arrows indicate motivations and conceptual links.
Summary
- RLHF sits at the intersection of philosophy, economics, psychology, reinforcement learning, and deep learning – each bringing its own assumptions about what preferences are and how they can be optimized.
- Reinforcement learning was designed for domains with stable, deterministic reward functions, but human preferences are noisy, context-dependent, temporally shifting, and not always transitive – a fundamental mismatch that shapes the limitations of RLHF.
- The Von Neumann-Morgenstern utility theorem provides theoretical license for modeling preferences as scalar functions, but its assumptions (transitivity, comparability, stability) are routinely violated in practice. Impossibility theorems in social choice theory further show that no single aggregation method over preferences can satisfy all fairness criteria simultaneously.
- These challenges explain why RLHF will never be fully “solved,” but they do not prevent it from being useful. In practice, RLHF operates on more tractable problems of style and performance rather than attempting to resolve the full complexity of human values.
- The practical mechanics of collecting and structuring preference data in light of RLHF’s complex motivations are covered in Chapter 11.
 The RLHF Book ebook for free
The RLHF Book ebook for free