1 Thinking in distributed systems: Models, mindsets, and mechanics
Modern software is unavoidably distributed: multiple concurrent components communicate over a network to deliver functionality that a single machine cannot provide alone. This chapter motivates why we distribute—so systems can remain correct, scalable, and reliable as load grows and failures occur—and frames the core challenge: complexity emerges from many parts and their interactions. It argues that progress comes from strong mental models, not just terminology or tool familiarity, and defines good models as both correct (no falsehoods) and complete (no relevant omissions). With an emphasis on moving from “knowing” to “understanding,” it sets the goal of reasoning about distributed systems confidently through precise, shared abstractions.
The chapter builds a baseline model of a distributed system as a state machine that advances in discrete steps, each taken by a component or the network, through internal work and message exchanges. It clarifies global versus local viewpoints—observers can see the whole system; components see only their local state and their network channel—and shows how correctness can be specified via safety (nothing bad happens) and liveness (something good eventually happens). Scalability and reliability are treated as responsiveness under load and failures, respectively, formalized with service-level indicators, objectives, and error budgets. The text highlights that multiple, even contrasting, models can be valid depending on focus, warns about overreliance on analogies, and introduces “systems of systems” thinking (holons/holarchies) to flexibly zoom in and out of complex architectures.
To make abstractions tangible, the chapter presents an office-building metaphor for components, network, and external interfaces, which cleanly captures crash and message-delivery semantics such as loss, duplication, and reordering. It advocates “thinking above the code,” modeling concurrency through interleavings to generalize race conditions and connect to database serializability, and distills the central design problem: think globally, act locally—craft global guarantees via only local observations and actions. Throughout, short “AHA!” moments reinforce that guarantees are application-specific and emergent, encouraging readers to juggle multiple mental models, embrace changing resolutions of view, and build the disciplined reasoning needed to design functional, scalable, and reliable distributed systems.
Mental model and system

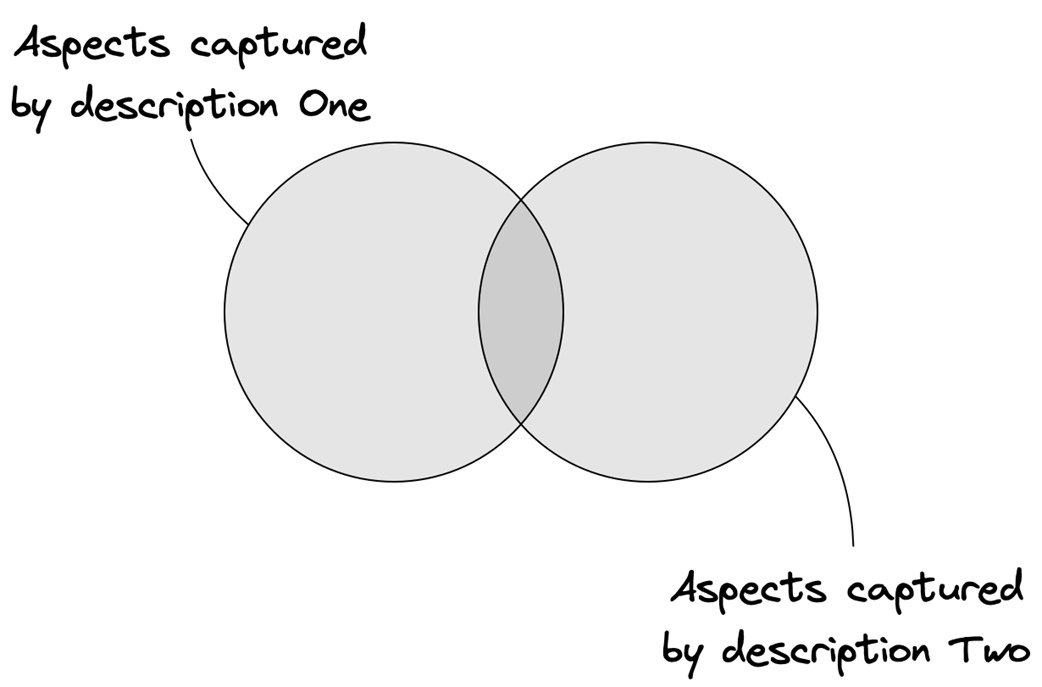
Different models describing the same aspects of a system (the set of facts of each model totally overlaps)

The network as the buffer of inflight messages

The components as the buffer for inflight messages
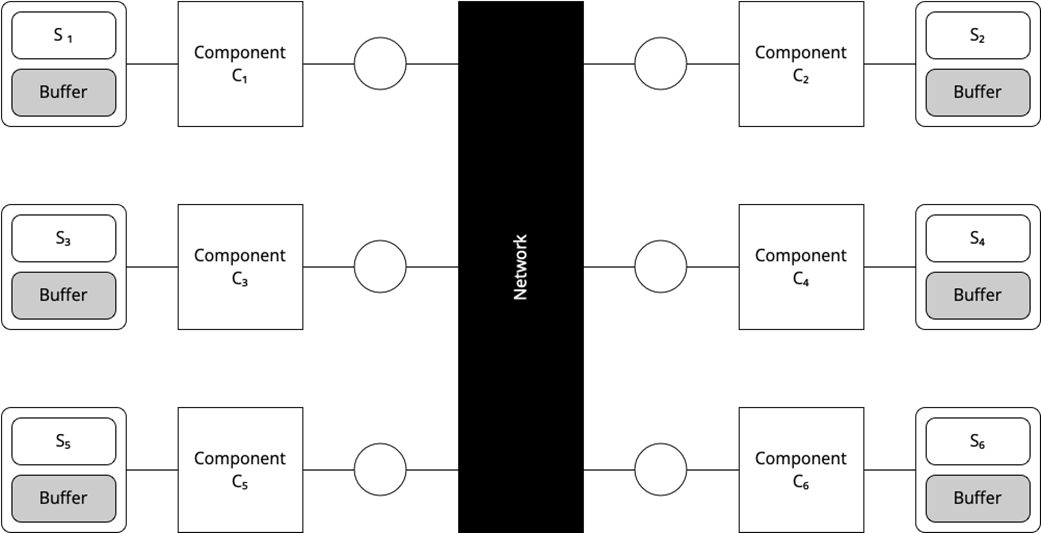
Different models describing different aspects of a system (the set of facts of each model partially overlaps)
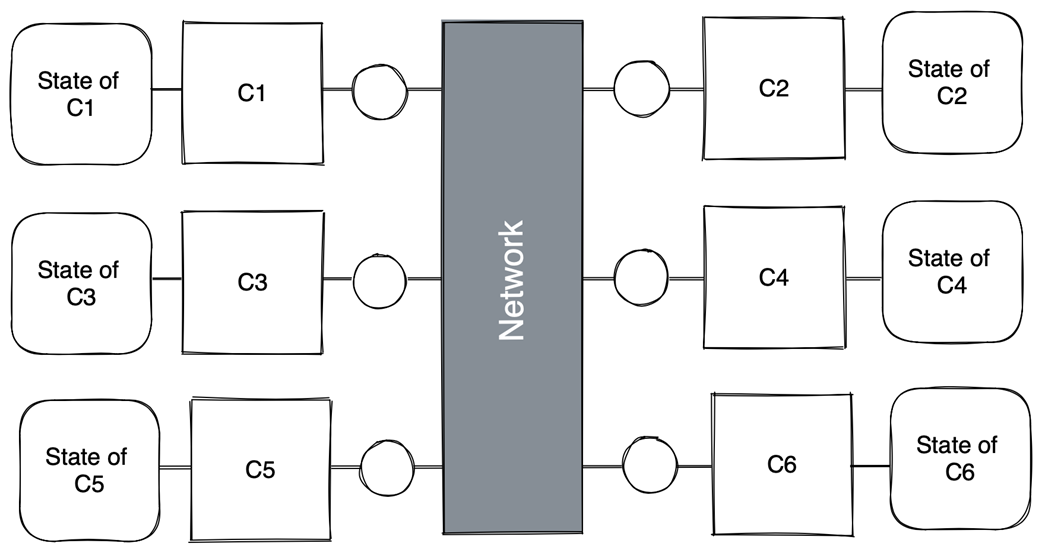
A distributed system as a set of concurrent, communicating components (local state of network not shown)
Behavior of a system as a sequence of states

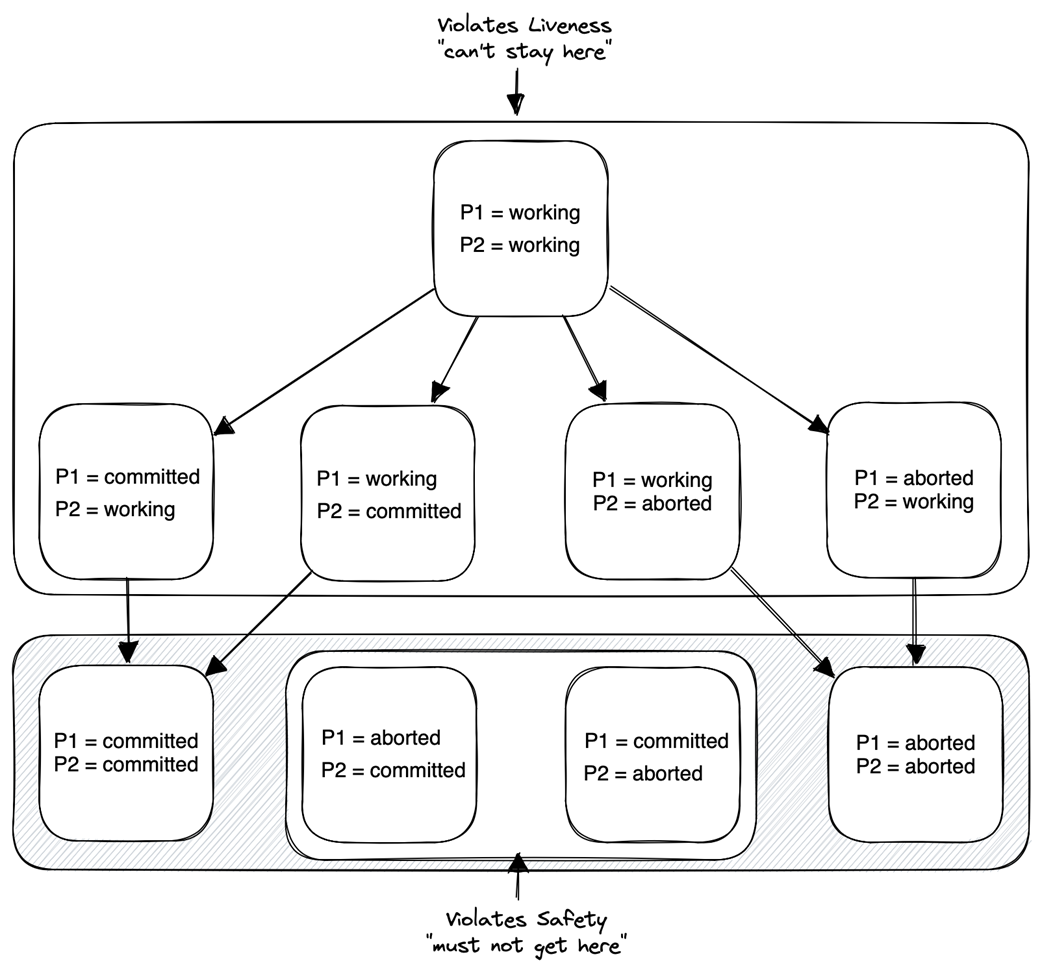
Safety and liveness

Behavior space of a distributed transaction with two participants
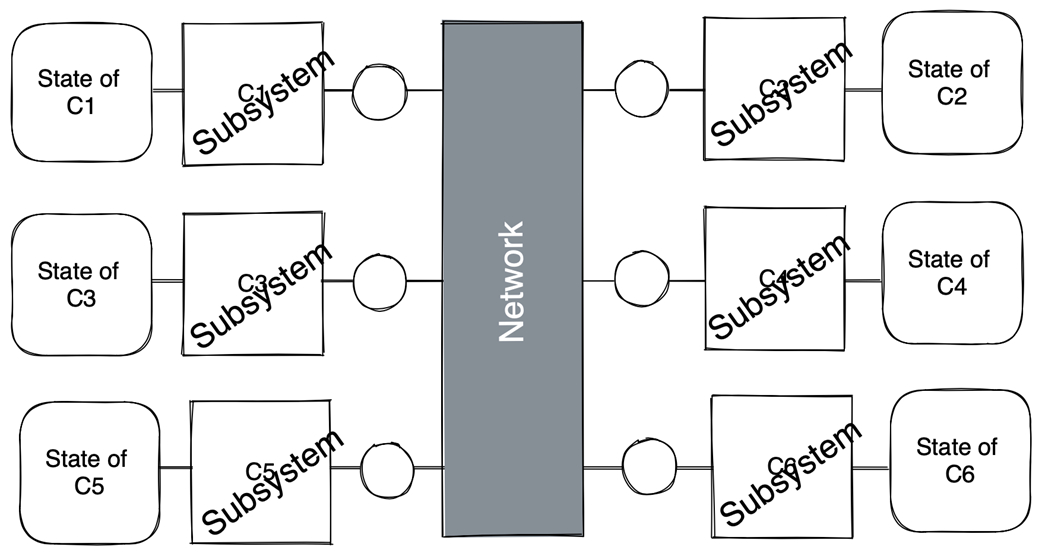
A distributed system as a set of concurrent, communicating subsystems
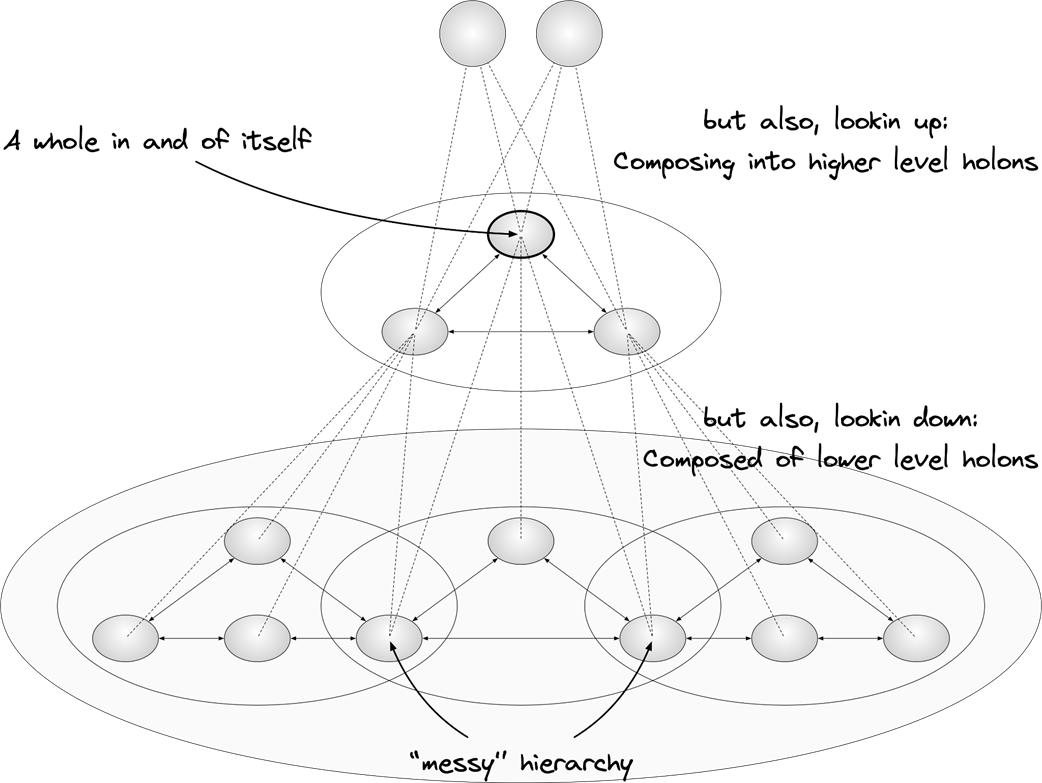
Holons and holarchies
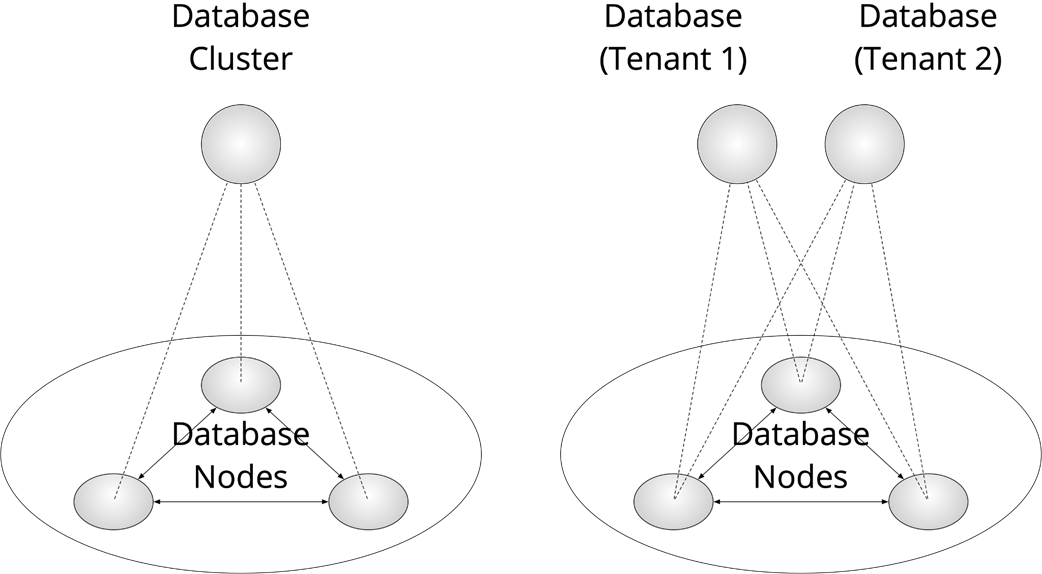
Two different holarchies, representing the same system
Global point of view

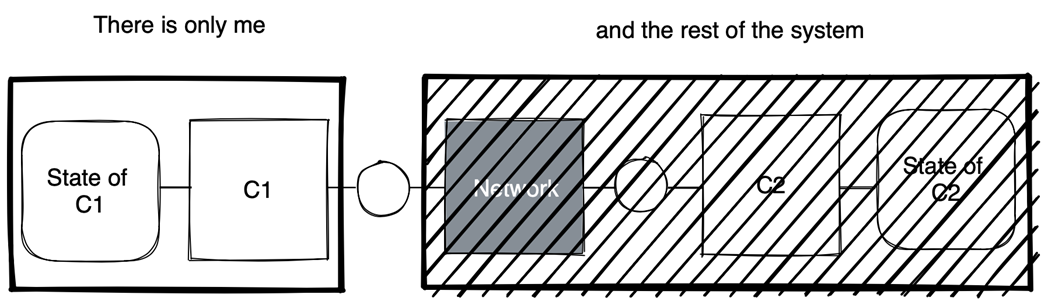
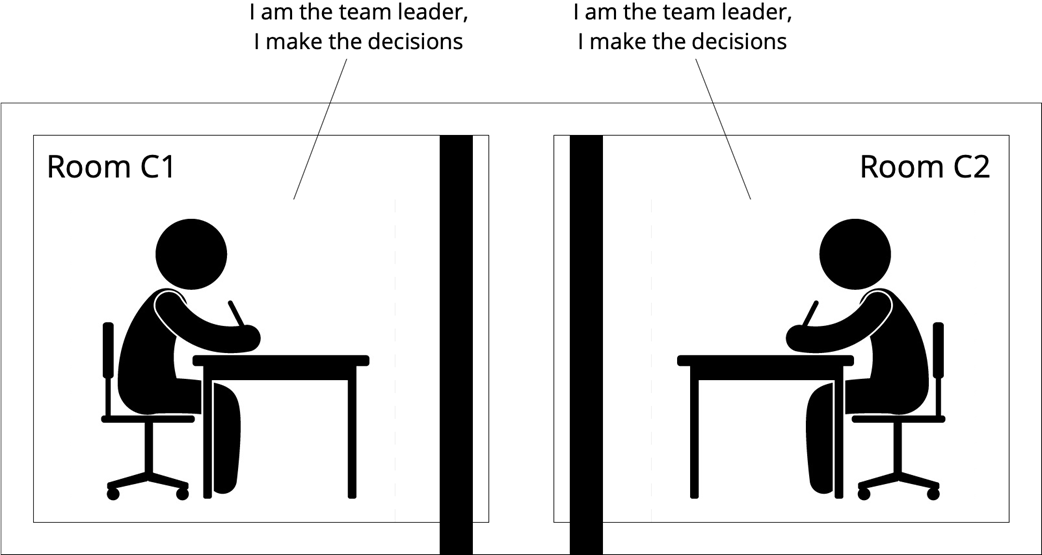
C1’s point of view
Distributed Systems Incorporated
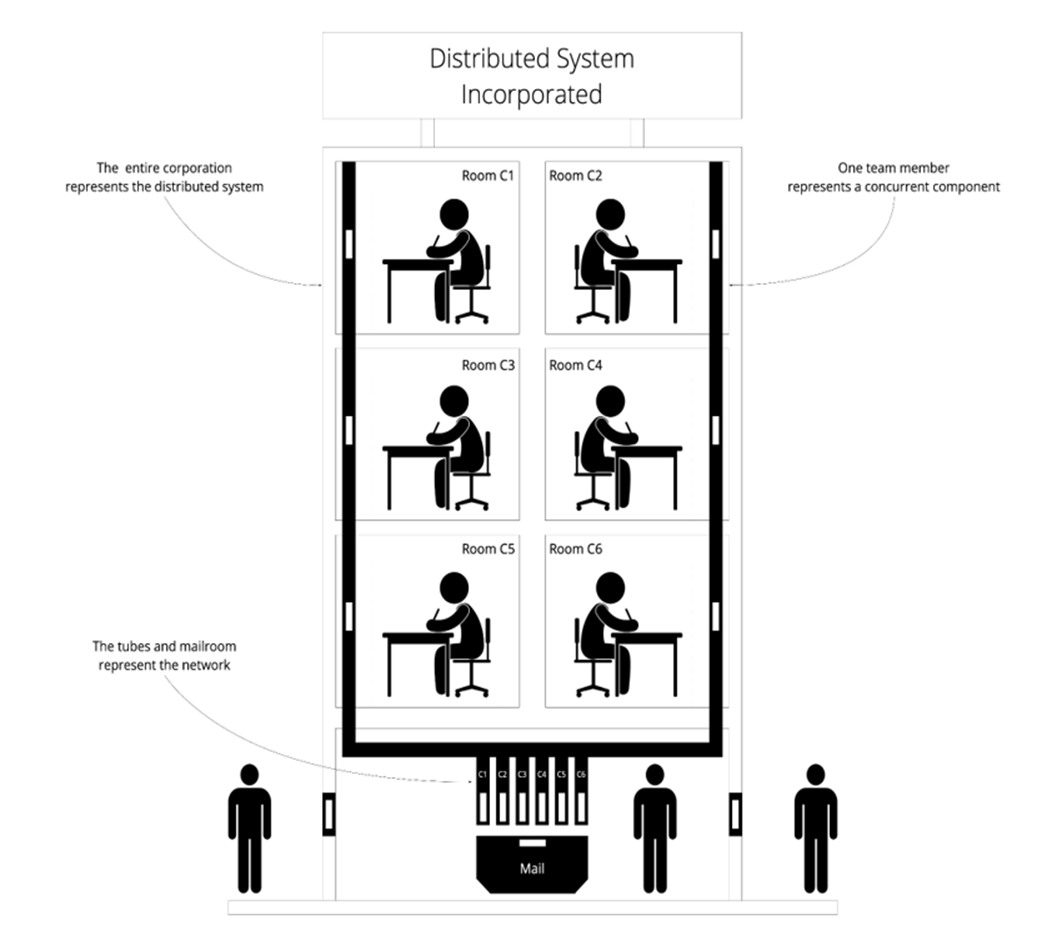
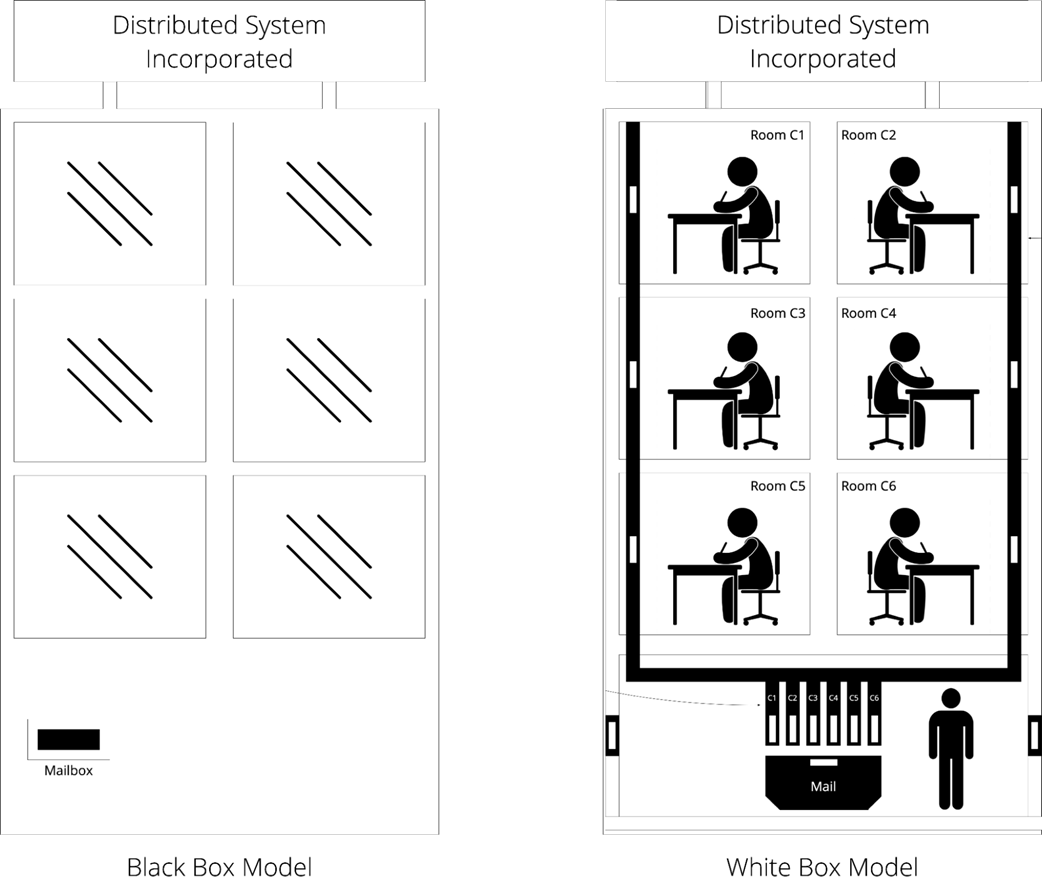
Black box versus white box, a global point of view
Local point of view

Splitbrain
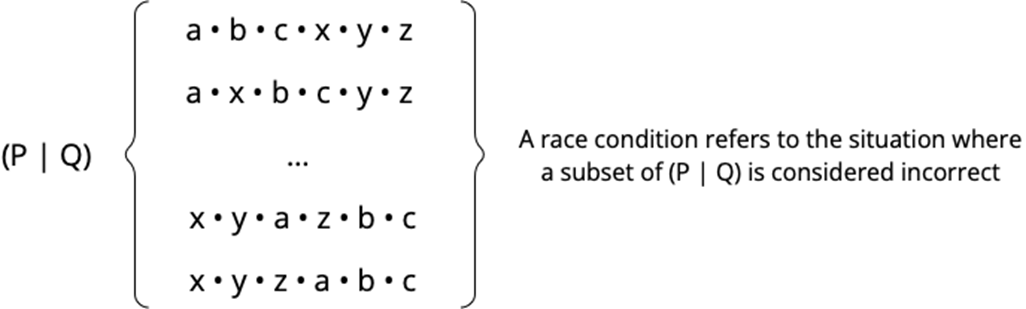
Reasoning about race conditions
Reasoning about serializability

Summary
- A mental model is the internal representation of the target system and is the basis of comprehension and communication.
- Striving for a deep understanding of distributed systems is better than merely knowing about their concepts.
- A distributed system is a set of concurrent components that communicate by sending and receiving messages over a network.
- The core challenge in designing distributed systems is creating a coherent system that functions as a whole despite each component having only local knowledge.
- Ultimately, we are interested in the guarantees a system provides. We reason about these guarantees in terms of correctness—that is, in terms of safety and liveness guarantees as well as scalability and reliability guarantees.
- Distributed systems can be visualized as a corporation, where rooms represent concurrent components, pneumatic tubes represent the network, and a mailbox represents the external interface.
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free